
SKylark OS 介绍
概述
GX8010/GX8009 SSD Kit SDK 是完整的智能音箱离在线混合方案,包括唤醒识别、语音识别(ASR)、自然语言处理(NLP)、返回意图识别结果(可定制skill)等,打通从底层到应用的整条链路。启动硬件平台,运行demo 程序,可进行基本的本地语音交互。SDK 主要模块包含:
- OpenWRT:提供完整的编译环境,进行Toolchain 下载,并编译Uboot、Kernel、系统软件和应用软件,生成需要的全部固件和根文件系统。
- Senseflow:信号处理系统,负责语音拾取、前处理和特征提取,能调用语言模型处理数据、合成语音和分词,与云端交互。
- Uboot:为内核启动准备环境,并加载内核。
- Kernel:提供Linux 操作系统。
- Skylark:提供多媒体信息的输入、处理、输出及各种外围器件的驱动、操控等一系列解决和二次开发方案。开发者可直接或二次开发后应用于各种人工智能产品。
当前离线方案支持以下功能:
- 通过“小芯宝贝”唤醒词触发唤醒状态
- 通过按键触发唤醒状态
- 支持音乐播放功能
- 支持TTS 播放功能
- 本地技能平台,可自定义简单的skill
当前在线方案支持以下云端:
- 支持图灵云端
- 支持声智Azero云端
- 支持rokid云端
- 支持思必驰云端
软件方案简介
OpenWRT框架图
智能音箱方案使用OpenWRT 来编译所有模块,生成所需要的固件和根文件系统,OpenWRT 整体软件框架如下图:

OpenWRT 软件框架
其中第一行为原始目录,第二行为编译过程中生成的目录,我们将Senseflow 和Uboot 设计为package 下的软件包,通过Makefile 来定义软件包版本、下载地址、编译方式和安装地址等。在target 里定义firmware 和Kernel 的编译过程。编译完成后firmware和ipk都会放在bin 目录对应的板级内。
SKylark OS软件框架图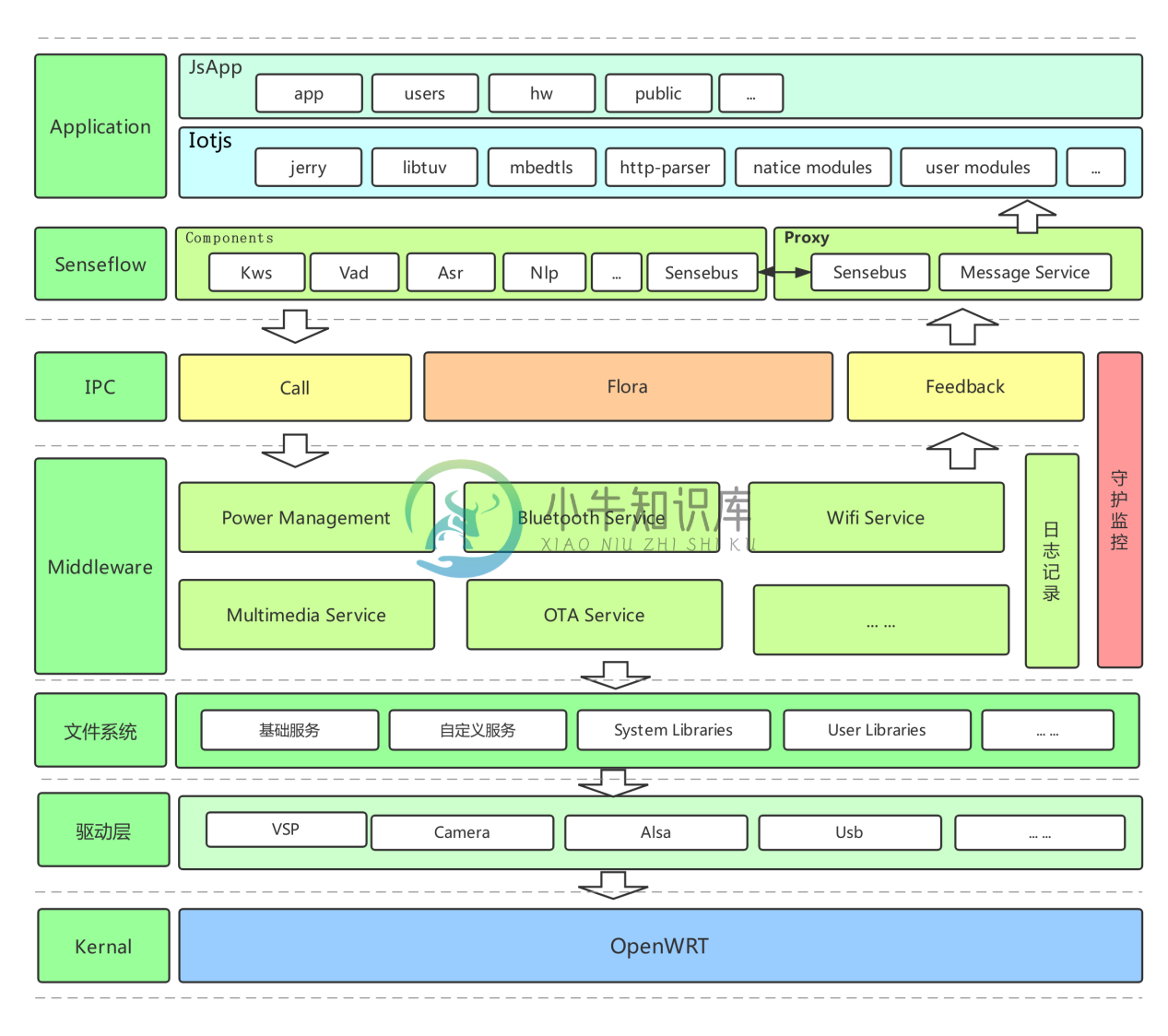 语音术语介绍
语音术语介绍
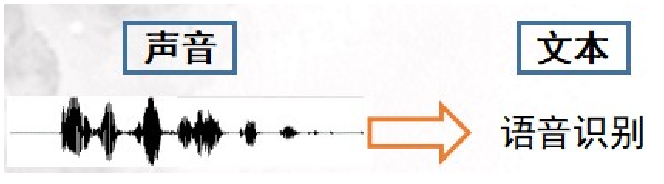
语音识别(ASR :Automatic Speech Recognition)
将声音转换成文本
语音合成(TTS:text-to-speech)
把文本转换成声音

语义理解(NLU: Natural Language Understanding)
识别说话人的意图
声学模型
声学模型教会机器“哪个字词发什么音”

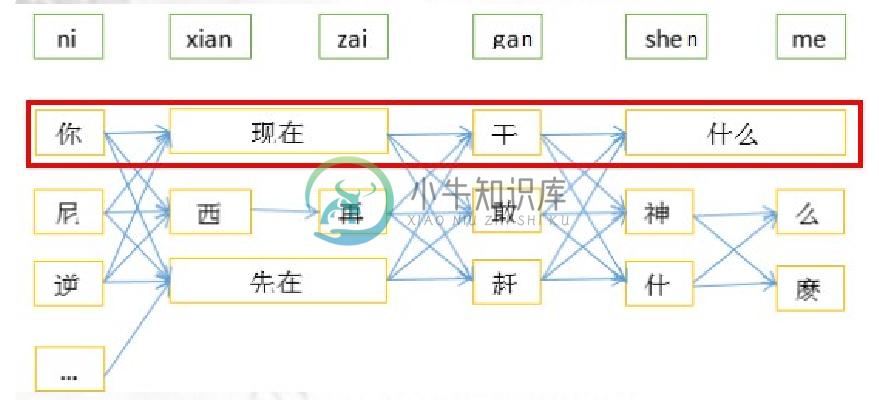
语言模型
语言模型教会机器“什么样的文字组合是合理的、更常见的”
语音活动检测(Vad: Voice Activity Detection)
VAD 可以区分非语音段和语音段。 如果使用了VAD,就可以自动检测声音的开始与停止,未识别到语音段时,不会进行识别处理,识别到语音段,才把音频发送到服务器处理
唤醒(wake up)
静默时,设备持续录音,用唤醒词唤醒设备后,设备才对后续的声音进行识别,以避免误操作 本地唤醒指唤醒算法运行在设备端 云端唤醒指唤醒算法运行在服务器
自噪声,环境噪声
自噪声:设备自身喇叭产生的噪声属于自噪声(例:电视喇叭,音箱喇叭),但是汽车发动机噪声不属于自 噪声 环境噪声:除自噪声外,都是环境噪声说明:自噪声可以通过算法消除绝大部分(因为自噪声的信号可以直接采集到),环境噪声通过大量数据的统计特征来抑制,但无法完全消除
回声消除(AEC:acoustic echo cancellation)
语音设备消除自噪声,让设备可以在本机播放音乐的同时,识别人说的话(不能消除环境噪声)
原理:
假设音箱喇叭播放音乐,人在说话,那么麦克风收集的数据是 音乐声+人声 。此时把喇叭的数据传给主控芯 片,通过比较麦克风数据(音乐+人声)和喇叭数据(音乐),可以消除麦克风中的音乐声。我们把内部电路传递 的信号叫做参考信号。因为麦克风的音乐是空间中传播(340m/s),数据会慢一些,因此实际处理的时候,会 把参考信号延时,与麦克风信号在时间上对齐再做处理。
波达方向定位(DOA)
声音传到多个麦克风会产生时延,算法根据时延可以计算声源方向,从而获取说话人的角度方向。
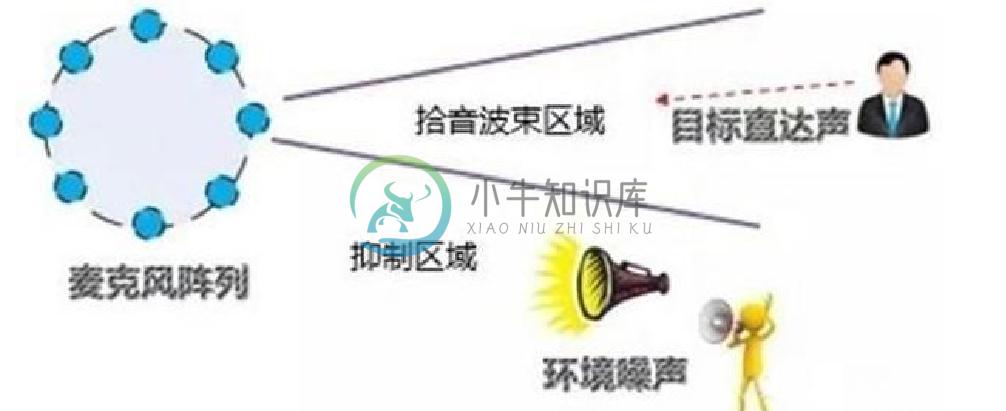
波束形成(beamforming)
波束形成是对麦克风阵列中各个麦克风输出的声音进行信号处理,从而形成空间指向性。这种方法会抑制目 标角度声音以外的声音干扰,不仅抑制噪声也包括其他方向的人声。
自动增益补偿(AGC:Automatic Gain Control)
AGC可以自动调麦克风的收音量,不会因发言者与麦克风的距离改变时,声音有忽大忽小声的缺点。
背景噪声抑制 (ANS : Automatic Noise Suppression)
ANS可探测出背景固定频率的杂音并消除背景噪音,呈现出与会者清晰的声音。
信噪比(SDR或 S/N)
有效信号与噪声信号的功率比值,单位是db(分贝) , 3db≈2倍
混响
声波在室内传播时,要被墙壁、天花板、地板等障碍物反射,每反射一次都要被障碍物吸收一些。这样,当 声源停止发声后,声波在室内要经过多次反射和吸收,最后才消失,我们就感觉到声源停止发声后还有若干 个声波混合持续一段时间(室内声源停止发声后仍然存在的声延续现象)。这种现象叫做混响,这段时间叫 做混响时间。
稳态噪声,非稳态噪声
稳态噪声:指噪声声压级; 的变化较小(一般不大于3dB),且不随时间有大幅度的变化,如电机、风机及其他电磁噪声,固定转速的摩 擦、转动等噪声。
非稳态噪声:指噪声强度; 随时间而有起伏波动(声压变化大于3dB)。有的呈周期性噪声,如锤击;有的呈无规律的起伏噪声,如交通 噪声。
字准率
所有测试结果中,字的准确率。例如: 一段文本总字数为S,语音识别的文字数为O,错误的字数为R,缺少的字 数为D,增加的字数为I,则字准率为: (1-(R+D+I)/S )*100% 通俗理解:去掉错的字,多的字,少的字,剩下的字的准确率

句准率
所有句子数目为S ,有任意字错误的句子数目为W , 句准确率= (1-W)*100%
句准率≤字准率
总谐波失真(THD)
由于电路不可避免的振荡或其他谐振产生的二次,三次总谐波失真与噪声测试谐波与实际输入信号叠加,在 输出端输出的信号就不单纯是与输入信号完全相同的成分,而是包括了谐波成分的信号,这些多余出来的谐 波成分与实际输入信号的对比,用百分比来表示就称为总谐波失真。
谐波是指对周期性非正弦交流量进行傅里叶级数分解所得到的大于基波频率整数倍的各次分量,通常称为高 次谐波
相干性
相关就是信号之间的相似程度,例如一个单位正弦波(幅值、频率都为1)和一个单位余弦波,由于它们在0 时刻是正交的,所以不相关。
相干是包含相位信息的,还是一个单位正弦波和一个单位余弦波,它们是相干的,因为具有相同的频率(恒 定的相位差)。
相位一致性
多个麦克风在相同的外界条件下感应同一声信号时表现的相位一致程度。此参数直接影响时延差的精确程度, 进而影响定位准确度
声学过载点(AOP)
声学过载点是麦克风的一项参数。外界音量太大时,麦克风失真会提高,当失真等于10%时的输入的声压大小为 声学过载点 例如: AOP=120db