
第1章 简介异构计算 - 1.3 并行思想
大多数应用开始都是运行在单核上。不过,在高性能计算时代,当系统提供多个计算资源时,这些资源就会用来为应用加速。标准的方法包括“分而治之”和“分散-聚合”的分解方式,为编程者提供一系列高效利用并行资源的方式。“分而治之”是将一个问题递归的划分为数个子问题,直到可用的计算资源能够解决划分后的子问题。“分散-聚合”会先发送一部分输入数据到每个并行资源中,然后将这些输入数据处理后的结果进行收集,再将这些结果合并到一个结果数据集中。以前,划分后的任务大小与计算资源的能力有很大关系。图1.1展示了普遍应用处理排序和矢量相乘的方式,以往的应用会将任务映射到可并行的计算资源中进行加速计算。
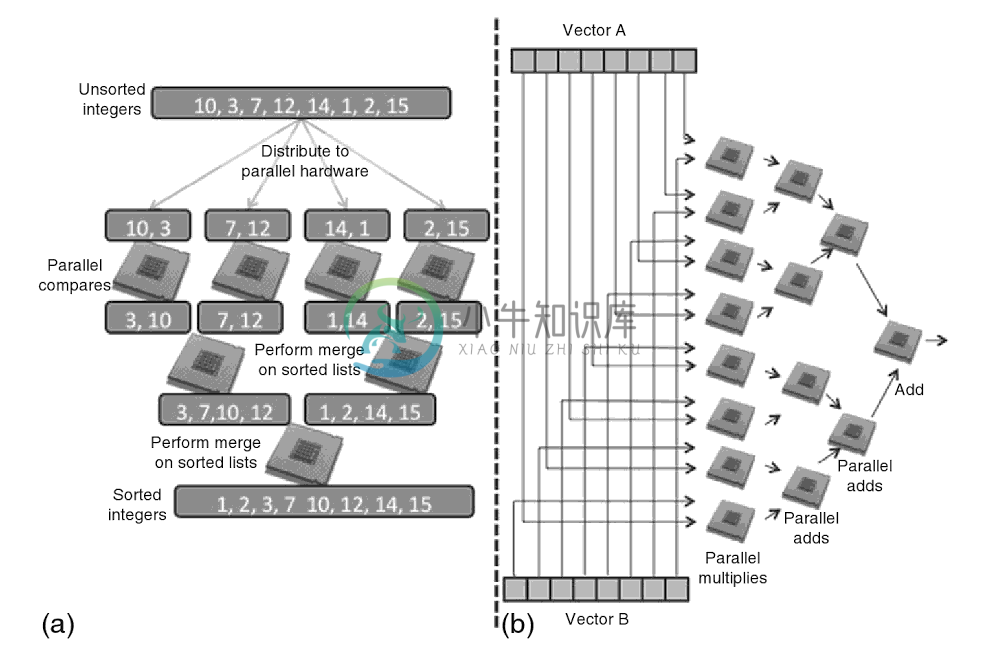
图1.1 (a)简单的排序例子:分而治之的实现,将一个列表划分为短列表,然后对这些短列表进行排序,然后将这些已经排序的短列表进行排序。 (b)矢量-标量乘法:将乘法分开计算,然后将乘法的结果通过一系列操作进行相加。
现代计算系统发展中,并行化和异构化成为一种趋势,这样传统的编程方式就一定会受到冲击。因为CMOS(互补金属氧化物半导体,Complementary Metal Oxide Semiconductor)的功耗和热极限是额定的,微处理器供应商发现硬件的瓶颈很难让设备获取更高的性能,所以其不得不使用多芯片的方式(或定制的方式)来替代单个芯片。因为硬件供应商们已经这样做了,那么对于编程者来说,就再也没有“免费的午餐”了(The Free Lunch Is Over)。同时,需要编程者抽离应用中并行的部分。编程者还要根据相关算法去划分任务,并且将这些划分好的任务映射到不同的硬件平台上。
过去的10年,并行计算设备的数量和计算能力都在快速的增长。近期,GPU出现在计算领域;今天,其能够使用很低的功耗,并提供很高的计算能力,让如今计算机的计算能力达到了一个新的水平。GPU已不是单纯基于驱动的3D实时图像渲染技术的硬件设备,GPU在其他方面的进化也十分迅速,并且成为一种完全可编程的设备,能够对数据和任务并行的任务进行处理。硬件制造商如今将CPU和GPU集成在了一块芯片上面,这将是下一代异构计算的趋势。计算敏感和数据敏感的应用都可以看做为一个任务,任务的代码在内核中。内核可运行在GPU上,GPU使用低功耗和高性能完成相应的任务,而CPU之后仅负责对非kernel代码任务的执行。
很多系统,以及大自然和人造世界中的某些现象,都展示着不同类别的并行和并发:
- 分子动力学——分子之间是互相影响的。
- 天气和海洋模型——成千上万的波浪和潮汐。
- 多媒体系统——视觉和音效,成千上万像素和波形。
- 汽车生产流水线——成千上万的汽车部件,每一款部件都由很多相同的产品线在生产。
并行计算由Almasi和Gottlieb[1]定义,这种计算模式下,很多计算可以同时进行。原理就是将大问题分割成小问题,这样小问题之间没有关联,就可以同时进行解决。这种程度的并行,依赖其实是物质内在的本质(还记得大自然中存在着有很多并行的现象吧),应用这样的原理就可以来处理手头上的问题。对于算法技巧和软件设计来说,了解哪些部分可以并行也是很重要的。我们先对两个简单例子进行讨论,展示其内在的并行计算:1.两个整型数组相乘;2.文本查找。
第一个例子会将两个整型数组A和B拆分后进行相乘,每个拆分数组中都有N个数组成,然后将乘后的结果存储到C数组中。图1.2展示了拆分的方式。串行的C++代码如下清单1.1所示。
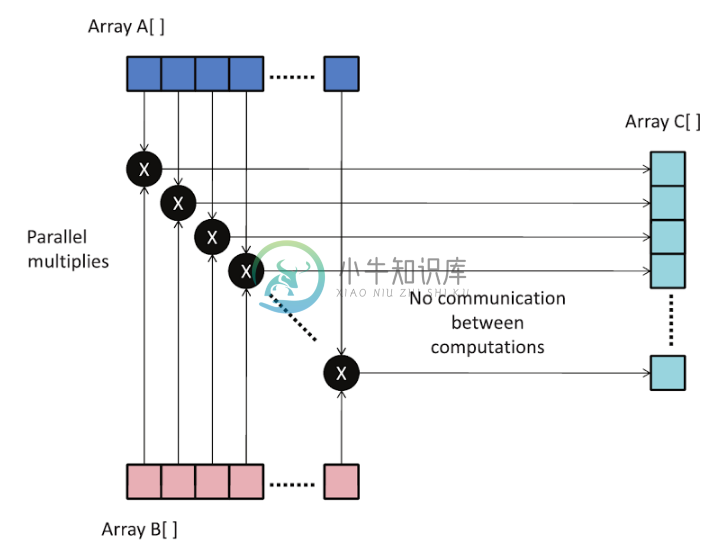
图1.2:A与B数组相乘,并将结果存入C数组中。
// 清单 1.1: 数组相乘for (int i = 0; i < N; ++i){C[i] = A[i] * B[i];}
虽然这段代的计算敏感度并不高,但这段代码确实可以并行。低计算敏感度说明该算法的计算部分操作,要少于内存操作。A和B中的元素都是相互独立的,如果要并行化这段代码,需要选择C++代码段中能够独立执行的代码段进行并行化。这段代码是可以数据并行的,A和B数组可以经过同样的处理,然后产生C数组中的数据。
我们再可以来看一个通过划分方式,实现简单任务并行的例子。任务有在操作系统处理中有着不同的状态,比如:完成、等待、处理、挂起等。这里我们讨论的是,使用整个任务的部分输入作为一个子项进行操作。任务并行可以进一步推广到流水线上,或是复杂的并行交互上。图1.3展示了一个任务并行在流水线的例子,这个例子使用快速傅里叶变化将图像从时域输出到频域上。
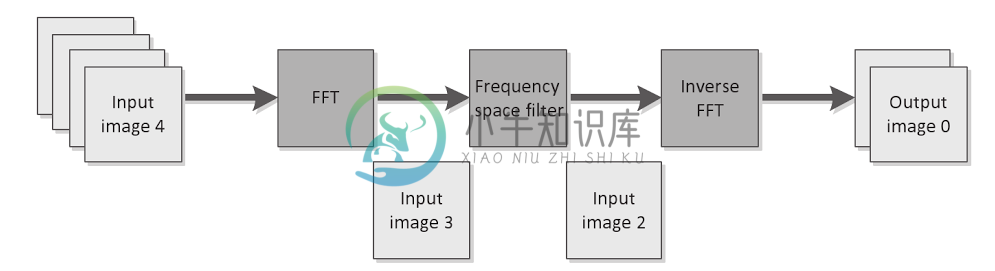
图1.3:FFT的任务并行例子。不同的图像将会被分为三个独立的任务进行。
让我们来看第二个例子。这里我们要尝试对不同的查找词进行分割,然后统计查找词在文本中出现的次数(可见图1.4)。假设查找词有N个,那我们可以将查找词和输入字符串进行匹配(相当于一个任务)。每个例子中查找词都会和输入的文本字符串进行匹配操作。这种方式很高效,并行度不错。不过,每次输入的字符串都要和这N个查找词进行匹配。每个并行任务都在执行相同的操作。与上个例子相比,这是一个任务细粒度并行化的例子。这两个例子展示了数据和任务级别的并行。
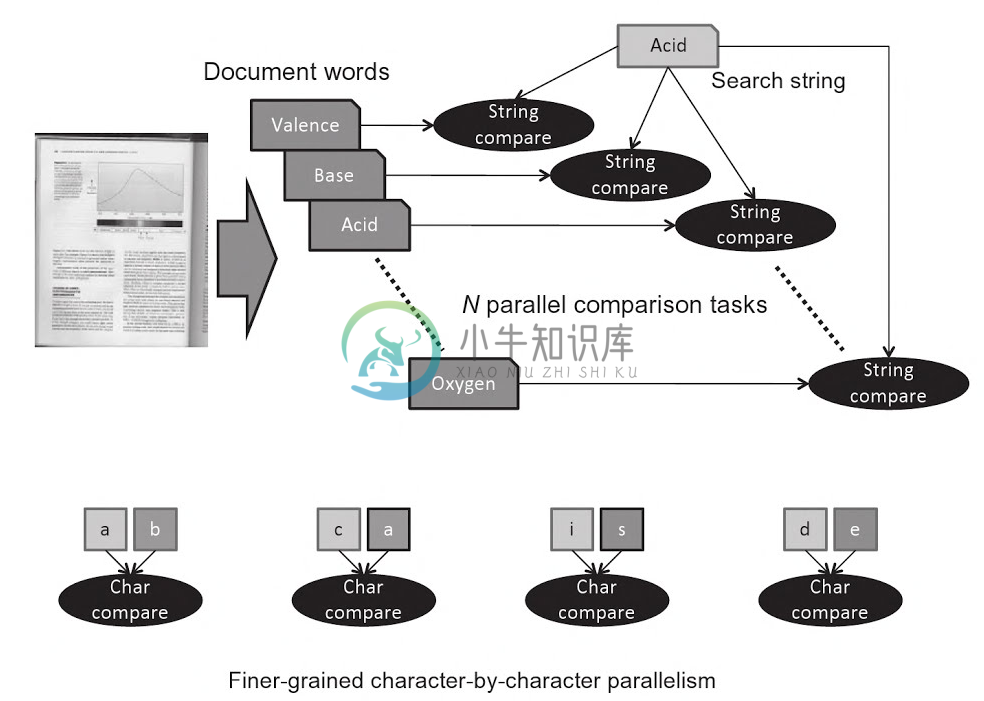
图1.4:任务级并行,多个查找词可以同时进行查找。也展示了,在一个词内,细粒度“字符与字符”相比较的并行性。
匹配数量是确定的,那我们需要将其出现的次数进行相加。同样的,相加操作也可以并行化。这一步中,会介绍“归约”原理,我们将使用高效的方式,利用并行资源来对各个词进行统计。图1.5所示的归约树,就是我们用来处理相加计算的方式,其时间复杂度为O(logN)。
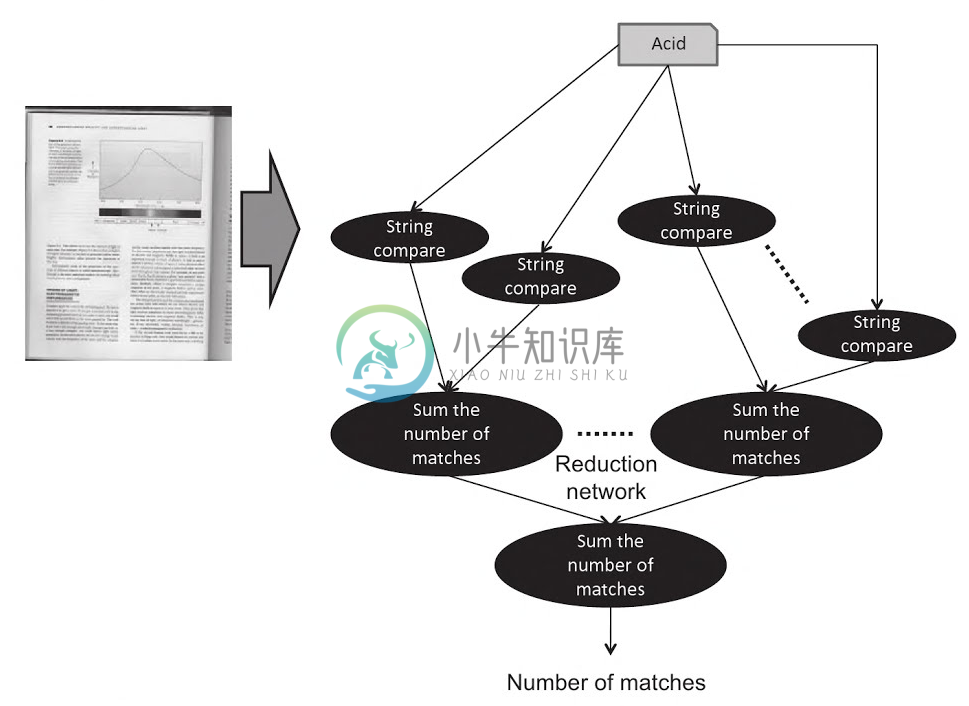
图1.5:结束了图1.4中的字符串比较之后,就要将匹配的结果进行相加,放入到一个结果节点中。
[1] G.S.Almamsi, A Goulieb, Highlu Parraleel Computing, Benjamin-Cummings Publishing Co.. Inc.. RedWood City, Ca, USA, 1989