
1.5.4 使用FDS
在 TrainJob 中使用 FDS
上一节通过一个简单的例子介绍了Cloud-ML Trainjob的基本使用。实际训练任务往往需要大量的训练数据,训练的模型、过程数据、Log等也需要及时保存,本节介绍怎么结合Cloud-ML和FDS实现训练数据的加载和结果保存。
Cloud-ML平台提供三种访问FDS的方式,
- 直接使用FDS的SDK。
- 使用Tensorflow框架时,使用框架本身提供的FDS访问功能。 注意:目前Cloud-ML平台提供的框架中,仅有Tensorflow进行了增强,可以直接访问FDS。
- 通过FDS FUSE把FDS文件挂载到本地。
本章,我们将介绍前两种方式,下一章介绍第三种即FDS FUSE的使用方式。
使用 FDS SDK
FDS提供了常见语言的SDK,可以通过这些SDK在代码中实现对FDS的访问。
在上手Trainjob中,我们介绍过,可以在setup.py文件中指定代码的依赖包,所以,要使用FDS SDK,我们的setup.py文件可以写成下面格式:
import setuptools
setuptools.setup(name='cloudml-tutorial-01', version='1.0', packages=['trainer', 'galaxy-fds-sdk'])
然后,我们可以在代码中操作FDS. 具体做法请参考FDS文档。
附录1,使用Python SDK访问FDS给出一个简单例子,可供参考。
下面我们详细介绍一下直接使用Tensorflow API 访问FDS。
使用 Tensorflow API 访问 FDS
官方TensorFlow目前只支持本地文件系统、Google内部的GFS和对象存储服务Google storage,社区版本已经支持HDFS。
我们基于TensorFlow API实现了与内部对象存储服务FDS的集成,可以直接在API层面实现对FDS的访问。注意,这里必须使用Cloud-ML平台提供的TensorFlow版本。
下面结合例子介绍使用方法。
示例介绍
这个例子使用Tensorflow在MNIST数据上实现一个简单的图像分类。众所周知,MNIST数据都是如下格式: 
该模型的详细介绍可参考:MNIST For ML Beginners
步骤
上传数据到 FDS
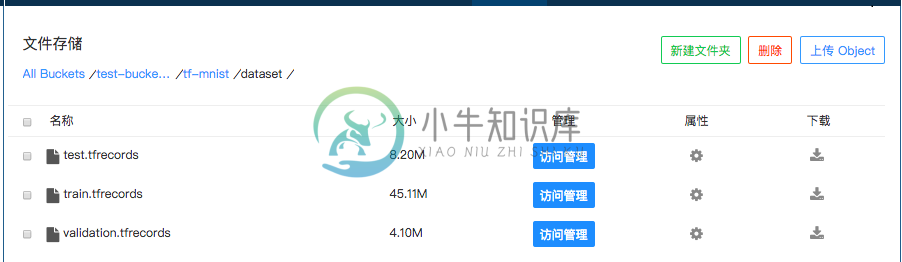
我们预先将MNIST数据转换成TFRecord,并将数据上传到FDS。假设上传到下面目录:
All Buckets/test-bucket-xg/tf_mnist/dataset,
该目录下面包括train,test和validation三个文件,分别对应训练集、测试集和验证集。
如下图示:
准备训练代码
我们需要在训练代码中指定FDS的存储路径。
完整的训练代码请参考附录2,使用Tensorflow API 访问FDS
TensorFlow应用代码只需把数据地址改为fds即可,其他代码无需改动,如下图:

其中,
- 分别对应ASSK的ID,Secret, FDS的Endpoint和bucket;
- 指定训练数据的存储路径;
- Tensorflow Checkpoint 的保存路径;
- 最终训练结果的保存路径。
代码打包
使用上一节介绍的打包方式,将代码打包。
提交Cloud-ML训练 使用下面命令提交训练代码。下面命令使用了-g 参数,这个参数指定我们使用一个GPU训练。 对GPU的支持,是Cloud-ML相较物理机一个优势之一:
- 用户不用关心底层不同型号的GPU的驱动,不用关心用什么Cuda/Cudnn版本,用户需要做的,只是一个简单的参数,告诉我要用GPU,以及要用多少个GPU;
- 目前我们的物理机服务器都是4卡GPU,对于大型的训练任务需要多于4卡的时候,物理机就很难满足,而Cloud-ML则可以轻松实现扩展。
cloudml jobs submit -n tf-fds -m trainer.task2 -u fds://test-bucket-xg/tf-mnist/tf_fds_test-1.0.tar.gz -g 1
查看任务日志
使用上一节介绍的方式,可以查看任务日志。下图是这个训练任务的一个节选:
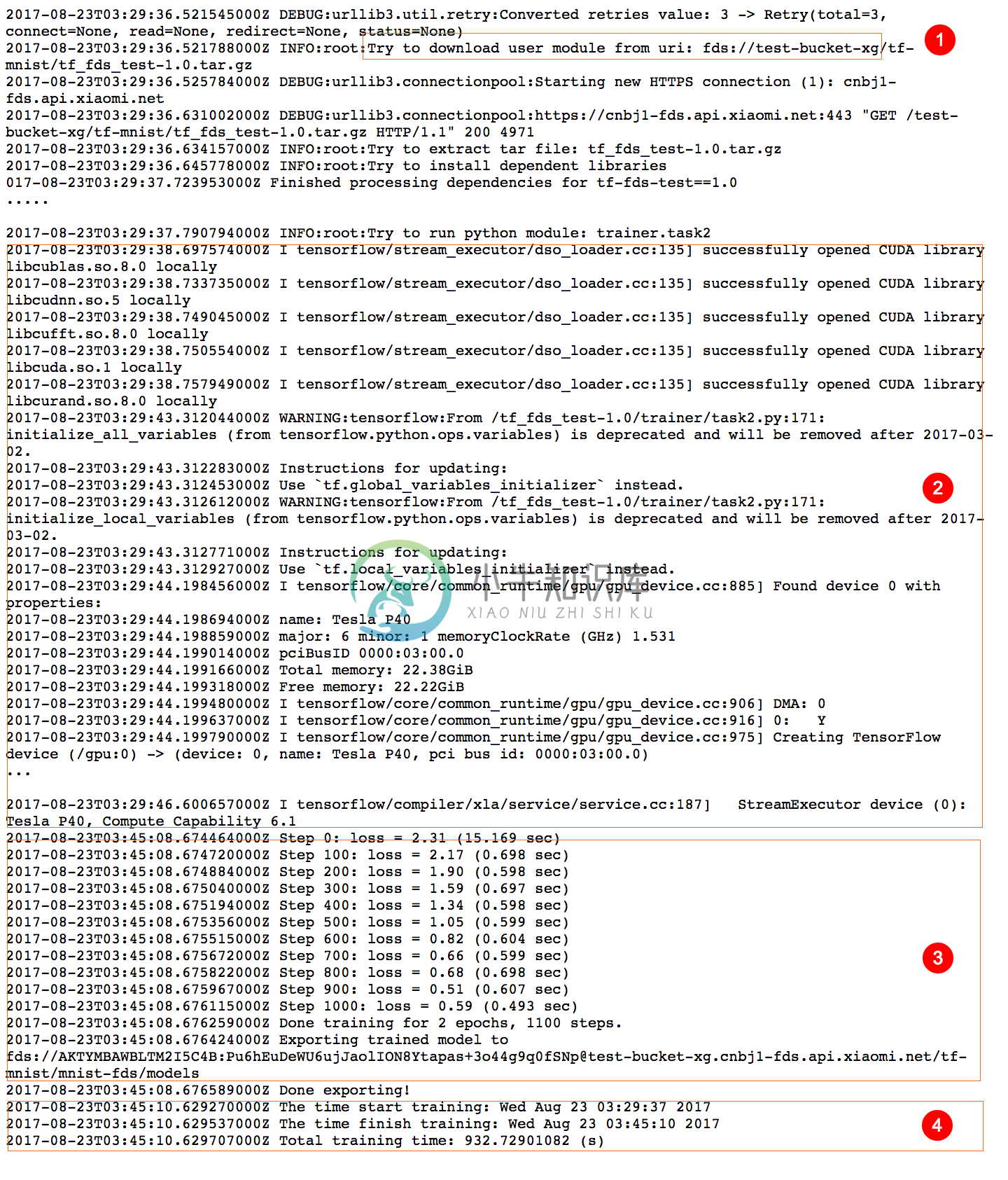
从Log上我们可以看出,这个训练任务使用了一个Tesla P40 的GPU,如上图2所示。
训练的结果
检查我们训练结果是否成功保存到我们指定的FDS目录中。下图是输出,我们可以看到保存下来的checkpoints 和最终训练的model。

存在问题
本节介绍了两种方式,一种是使用FDS的SDK, 一种是使用Tensorflow的API,两种方法在一定程度上支持了数据存储方面的要求,对用户来说,都有一定的局限性:使用SDK的方式,用户需要在训练代码中引入FDS的接口,不方便代码移植;Tensorflow API方式,训练代码无需修改,但是不能扩展到其他框架。一种更灵活的方式,是使用下面将要介绍的Fuse。
附录1,使用Python SDK访问FDS
import os
import glob
import sys
from fds import GalaxyFDSClient, GalaxyFDSClientException
from fds.model.fds_object_metadata import FDSObjectMetadata
bucket = 'johndoe'
log_dir = 'path/to/logs'
client = GalaxyFDSClient()
metadata = FDSObjectMetadata()
# the following meta-mode gives rights: rw-r--r--
metadata.add_header('x-xiaomi-meta-mode', '33188')
try:
for log in glob.glob(log_dir + '/*'):
if os.path.isfile(log):
print log.split('/')[-1]
with open(log, 'r') as f:
data = f.read()
path_to = log.split('/')[-1]
res = client.put_object(bucket, path_to, data, metadata)
print 'Put Object: ', res.signature, res.expires
client.set_public(bucket, path_to)
print 'Set public', path_to
except GalaxyFDSClientException as e:
print e.message
附录2,使用Tensorflow API 访问FDS
# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Train and Eval the MNIST network.
This version is like fully_connected_feed.py but uses data converted
to a TFRecords file containing tf.train.Example protocol buffers.
See tensorflow/g3doc/how_tos/reading_data.md#reading-from-files
for context.
YOU MUST run convert_to_records before running this (but you only need to
run it once).
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os.path
import time
import numpy
import tensorflow as tf
from tensorflow.python.platform import gfile
from tensorflow.contrib.session_bundle import exporter
from tensorflow.examples.tutorials.mnist import mnist
#from tensorflow.contrib.session_bundle import exporter
ID = "your aksk id"
SECRET = "you aksk secret"
ENDPOINT="cnbj1-fds.api.xiaomi.net"
BUCKET = "test-bucket-xg"
dataset_path = "fds://%s:%s@%s.%s/tf-mnist/dataset" % \
(ID, SECRET, BUCKET, ENDPOINT)
checkpoint_path = "fds://%s:%s@%s.%s/tf-mnist/mnist-fds/checkpoints" % \
(ID, SECRET, BUCKET, ENDPOINT)
export_path = "fds://%s:%s@%s.%s/tf-mnist/mnist-fds/models" % \
(ID, SECRET, BUCKET, ENDPOINT)
# Basic model parameters as external flags.
flags = tf.app.flags
FLAGS = flags.FLAGS
flags.DEFINE_float('learning_rate', 0.01, 'Initial learning rate.')
flags.DEFINE_integer('num_epochs', 2, 'Number of epochs to run trainer.')
flags.DEFINE_integer('hidden1', 128, 'Number of units in hidden layer 1.')
flags.DEFINE_integer('hidden2', 32, 'Number of units in hidden layer 2.')
flags.DEFINE_integer('batch_size', 100, 'Batch size.')
flags.DEFINE_string('train_dir', dataset_path,
'Directory with the training data.')
flags.DEFINE_string('checkpoint_dir', checkpoint_path,
'Directory for periodic checkpoints.')
flags.DEFINE_string('export_dir', export_path,
'Directory to export the final trained model.')
flags.DEFINE_integer('export_version', 1, 'Export version')
# Constants used for dealing with the files, matches convert_to_records.
TRAIN_FILE = 'train.tfrecords'
VALIDATION_FILE = 'validation.tfrecords'
def read_and_decode(filename_queue):
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example,
# Defaults are not specified since both keys are required.
features={
'image_raw': tf.FixedLenFeature([], tf.string),
'label': tf.FixedLenFeature([], tf.int64),
})
# Convert from a scalar string tensor (whose single string has
# length mnist.IMAGE_PIXELS) to a uint8 tensor with shape
# [mnist.IMAGE_PIXELS].
image = tf.decode_raw(features['image_raw'], tf.uint8)
image.set_shape([mnist.IMAGE_PIXELS])
# OPTIONAL: Could reshape into a 28x28 image and apply distortions
# here. Since we are not applying any distortions in this
# example, and the next step expects the image to be flattened
# into a vector, we don't bother.
# Convert from [0, 255] -> [-0.5, 0.5] floats.
image = tf.cast(image, tf.float32) * (1. / 255) - 0.5
# Convert label from a scalar uint8 tensor to an int32 scalar.
label = tf.cast(features['label'], tf.int32)
return image, label
def inputs(train, batch_size, num_epochs):
"""Reads input data num_epochs times.
Args:
train: Selects between the training (True) and validation (False) data.
batch_size: Number of examples per returned batch.
num_epochs: Number of times to read the input data, or 0/None to
train forever.
Returns:
A tuple (images, labels), where:
* images is a float tensor with shape [batch_size, mnist.IMAGE_PIXELS]
in the range [-0.5, 0.5].
* labels is an int32 tensor with shape [batch_size] with the true label,
a number in the range [0, mnist.NUM_CLASSES).
Note that an tf.train.QueueRunner is added to the graph, which
must be run using e.g. tf.train.start_queue_runners().
"""
if not num_epochs: num_epochs = None
filename = os.path.join(FLAGS.train_dir,
TRAIN_FILE if train else VALIDATION_FILE)
with tf.name_scope('input'):
filename_queue = tf.train.string_input_producer(
[filename], num_epochs=num_epochs)
# Even when reading in multiple threads, share the filename
# queue.
image, label = read_and_decode(filename_queue)
# Shuffle the examples and collect them into batch_size batches.
# (Internally uses a RandomShuffleQueue.)
# We run this in two threads to avoid being a bottleneck.
images, sparse_labels = tf.train.shuffle_batch(
[image, label], batch_size=batch_size, num_threads=2,
capacity=1000 + 3 * batch_size,
# Ensures a minimum amount of shuffling of examples.
min_after_dequeue=1000)
return images, sparse_labels
def run_training():
"""Train MNIST for a number of steps."""
gfile.MkDir(FLAGS.checkpoint_dir)
# Tell TensorFlow that the model will be built into the default Graph.
with tf.Graph().as_default():
# Input images and labels.
images, labels = inputs(train=True, batch_size=FLAGS.batch_size,
num_epochs=FLAGS.num_epochs)
# Build a Graph that computes predictions from the inference model.
logits = mnist.inference(images,
FLAGS.hidden1,
FLAGS.hidden2)
# Add to the Graph the loss calculation.
loss = mnist.loss(logits, labels)
# Add to the Graph the predict
# Add to the Graph operations that train the model.
train_op = mnist.training(loss, FLAGS.learning_rate)
# The op for initializing the variables.
#init_op = tf.initialize_all_variables()
init_op = tf.group(tf.initialize_all_variables(), tf.initialize_local_variables())
# Create a session for running operations in the Graph.
sess = tf.Session()
# Create checkpoint saver
saver = tf.train.Saver()
# Initialize the variables (the trained variables and the
# epoch counter).
sess.run(init_op)
# Start input enqueue threads.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
step = 0
while not coord.should_stop():
start_time = time.time()
# Run one step of the model. The return values are
# the activations from the `train_op` (which is
# discarded) and the `loss` op. To inspect the values
# of your ops or variables, you may include them in
# the list passed to sess.run() and the value tensors
# will be returned in the tuple from the call.
_, loss_value = sess.run([train_op, loss])
duration = time.time() - start_time
# Print an overview fairly often.
if step % 100 == 0:
saver.save(sess, FLAGS.checkpoint_dir + '/model.ckpt',
global_step=step)
print('Step %d: loss = %.2f (%.3f sec)' % (step, loss_value,
duration))
step += 1
except tf.errors.OutOfRangeError:
print('Done training for %d epochs, %d steps.' % (FLAGS.num_epochs, step))
finally:
# When done, ask the threads to stop.
coord.request_stop()
# Wait for threads to finish.
coord.join(threads)
print('Exporting trained model to ' + FLAGS.export_dir)
# NOTE this format is depreceted, please refer to tensorflow_serving for
# more examples
saver = tf.train.Saver(sharded=True)
model_exporter = exporter.Exporter(saver)
signature = exporter.classification_signature(input_tensor=images,
scores_tensor=logits)
model_exporter.init(sess.graph.as_graph_def(),
default_graph_signature=signature)
model_exporter.export(FLAGS.export_dir, tf.constant(FLAGS.export_version),
sess)
print('Done exporting!')
sess.close()
def main(_):
run_training()
if __name__ == '__main__':
tf.app.run()