
Spring cloud Feign 深度学习与应用详解

简介
Spring Cloud Feign是一个声明式的Web Service客户端,它的目的就是让Web Service调用更加简单。Feign提供了HTTP请求的模板,通过编写简单的接口和插入注解,就可以定义好HTTP请求的参数、格式、地址等信息。Feign会完全代理HTTP请求,开发时只需要像调用方法一样调用它就可以完成服务请求及相关处理。开源地址:https://github.com/OpenFeign/feign。Feign整合了Ribbon负载和Hystrix熔断,可以不再需要显式地使用这两个组件。总体来说,Feign具有如下特性:
- 可插拔的注解支持,包括Feign注解和JAX-RS注解;
- 支持可插拔的HTTP编码器和解码器;
- 支持Hystrix和它的Fallback;
- 支持Ribbon的负载均衡;
- 支持HTTP请求和响应的压缩。
Spring Cloud Feign致力于处理客户端与服务器之间的调用需求。随着业务的扩展和微服务数量的增多,不可避免的需要面对如下问题:
- 弹性客户端
- 雪崩效应
简单来说,使用Spring Cloud Feign组件,他本身整合了Ribbon和Hystrix。可设计一套稳定可靠的弹性客户端调用方案,避免整个系统出现雪崩效应。
雪崩效应
在微服务架构中,微服务是完成一个单一的业务功能,这样做的好处是可以做到解耦,每个微服务可以独立演进。但是,一个应用可能会有多个微服务组成,微服务之间的数据交互通过远程过程调用完成。这就带来一个问题,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,产生“雪崩效应”。引发雪崩效应的原因有:
- 硬件故障:如服务器宕机,机房断电,光纤被挖断等;
- 流量激增:如异常流量,重试加大流量等;
- 缓存穿透:一般发生在应用重启,所有缓存失效时,以及短时间内大量缓存失效时。大量的缓存不命中,使请求直击后端服务,造成服务提供者超负荷运行,引起服务不可用;
- 程序BUG:如程序逻辑导致内存泄漏,JVM长时间FullGC等;
- 同步等待:服务间采用同步调用模式,同步等待造成的资源耗尽;
- 服务降级故障:服务的降级可以是以间歇性的故障开始,并形成不可逆转的势头。可能开始只是一小部分服务调用变慢,直到突然间应用程序容器耗尽了线程(所有线程都在等待调用完成)并彻底崩溃。
弹性客户端
客户端弹性模式是在远程服务发生错误或表现不佳时保护远程资源(另一个微服务调用或者数据库查询)免于崩溃。这些模式的目标是为了能让客户端“快速失败”,不消耗诸如数据库连接、线程池之类的资源,还可以避免远程服务的问题向客户端的消费者进行传播,引发“雪崩”效应。spring cloud Feign主要使用的有四种客户端弹性模式:
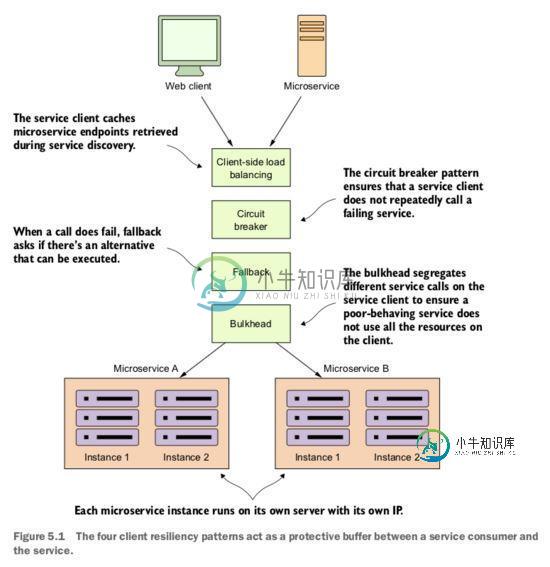
客户端负载均衡(client load balance)模式
Spring Cloud Feign集成Ribbon处理。Ribbon 是一个基于 http 和 tcp 客户端的负载均衡,可以配置在客户端,以轮询、随机、权重(权重意思是请求时间越久的server,其被分配给客户端使用的可能性就越低。)等方式实现负载均衡。Feign其实不是做负载均衡的,负载均衡是Ribbon的功能,Feign只是集成了Ribbon 而已。Feign的作用的替代RestTemplate,性能比较低,但是可以使代码可读性很强。
断路器(circuit breaker)模式
本模式模仿的是电路中的断路器。有了软件断路器,当远程服务被调用时,断路器将监视这个调用,如果调用时间太长,断路器将介入并中断调用。此外,如果对某个远程资源的调用失败次数达到某个阈值,将会采取快速失败策略,阻止将来调用失败的远程资源。
后备(fallback)模式
当远程调用失败时,将执行替代代码路径,并尝试通过其他方式来处理操作,而不是产生一个异常。也就是为远程操作提供一个应急措施,而不是简单的抛出异常。
舱壁/隔板(bulkhead)模式
舱壁模式是建立在造船的基础概念上。一艘船会被划分为多个水密舱(舱壁),因而即使少数几个部位被击穿漏水,整艘船并不会被淹没。将这个概念带入到远程调用中,如果所有调用都使用的是同一个线程池来处理,那么很有可能一个缓慢的远程调用会拖垮整个应用程序。在舱壁模式中可以隔离每个远程资源,并分配各自的线程池,使之互不影响。
Hystrix介绍
Hystrix,英文翻译是豪猪,是一种保护机制,Netflix公司的一款组件。主页:https://github.com/Netflix/Hystrix/。Hystix是Netflix开源的一个延迟和容错库,用于隔离访问远程服务、第三方库,防止出现级联失败。

Hystrix特性
1.断路器机制-断路器模式
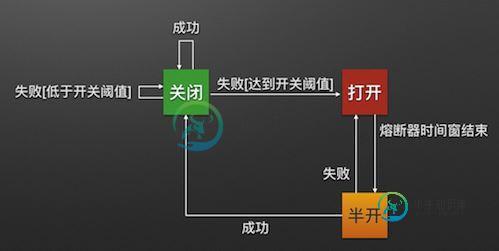
断路器很好理解, 当Hystrix Command请求后端服务失败数量超过一定比例(默认50%), 断路器会切换到开路状态(Open)。这时所有请求会直接失败而不会发送到后端服务。断路器保持在开路状态一段时间后(默认5秒), 自动切换到半开路状态(HALF-OPEN)。这时会判断下一次请求的返回情况, 如果请求成功, 断路器切回闭路状态(CLOSED), 否则重新切换到开路状态(OPEN)。Hystrix的断路器就像我们家庭电路中的保险丝, 一旦后端服务不可用, 断路器会直接切断请求链, 避免发送大量无效请求影响系统吞吐量, 并且断路器有自我检测并恢复的能力。
熔断器模式就像是那些容易导致错误的操作的一种代理。这种代理能够记录最近调用发生错误的次数,然后决定使用允许操作继续,或者立即返回错误。熔断器就是保护服务高可用的最后一道防线。 熔断器开关相互转换的逻辑如下图:
2.Fallback-后备模式
Fallback相当于是降级操作。对于查询操作, 我们可以实现一个fallback方法, 当请求后端服务出现异常的时候, 可以使用fallback方法返回的值. fallback方法的返回值一般是设置的默认值或者来自缓存。
3.资源隔离-舱壁(bulkhead)模式
在Hystrix中, 主要通过线程池来实现资源隔离。通常在使用的时候应该根据调用的远程服务划分出多个线程池。例如调用产品服务的Command放入A线程池, 调用账户服务的Command放入B线程池. 这样做的主要优点是运行环境被隔离开了。这样就算调用服务的代码存在bug或者由于其他原因导致自己所在线程池被耗尽时, 不会对系统的其他服务造成影响。 但是带来的代价就是维护多个线程池会对系统带来额外的性能开销。如果是对性能有严格要求而且确信自己调用服务的客户端代码不会出问题的话, 可以使用Hystrix的信号模式(Semaphores)来隔离资源。
Spring Cloud Feign 应用
上面主要是讲述了Feign模式管理客户端方面应对的一些问题和理论知识,下面将讲述Feign结合Ribbon和Hystrix在项目中的落地应用。
创建Feign
在Spring Boot项目中, 推荐在pom中添加Feign依赖(feign默认会使用JDK自带的 HttpUrlConnection ,相对于Apache的HttpComponent缺失连接池等扩展信息,详情见:FeignRibbonClientAutoConfiguration)。
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency> <dependency> <groupId>io.github.openfeign</groupId> <artifactId>feign-httpclient</artifactId> </dependency>
在App启动类中,设置启用Feign:
@EnableFeignClients
public class App {
}
搭建一个Feign Client基本配置:
@FeignClient(value="wl-service")
public interface WlFeignClient {
@RequestMapping(method = RequestMethod.GET, value= "/stores")
List<Store> getStores();
@RequestMapping(method = RequestMethod.POST, value= "/stores/{storeId}", consumes = "application/json")
Store update(@PathVariable("storeId") Long storeId, Store store);
@FeignClient
在此处可以配置客户端访问服务的方式,及通过服务名走服务发现模式和http地址模式,其参数可配置如:
- 服务发现:@FeignClient(value = "wl-v1-00", fallback = ArticleSystemRemoteFallback.class)
- http地址:@FeignClient(name = "wl-test", url = "${test.url}", path = "combwl", fallbackFactory = GoodsGroupFeignFallbackFactory.class)
- 服务发现 模式value及微服务的名称,fallback即定义后备模式,当触发熔断时,定义后备返回接口,便于客户端“快速失败”。
- http地址模式 url即是对应微服务的访问地址,path可设置或不设置,表示该服务下面的通用访问路径。fallback是定义后备模式。
FeignClient模式通过Apache的HttpComponent封装调用时,需注意多参数,json等数据的细节处理。
Feign Hystrix断路器模式
Feign本身集成了Hystrix。但默认情况下没有启动。必须显示声明(feign.hystrix.enabled=true)。客户端应用就是在配置文件中设置hystrix的配置,项目自动根据配置文件参数调整。hystrix配置(所有的配置可以参考com.netflix.hystrix.HystrixCommandProperties这个类)。
常用的hystrix配置设置如下:
hystrix:
command:
default:
circuitBreaker:
# 是否开启熔断(默认true)
enabled: true
# 熔断生效至少请求数量(默认20),当同一HystrixCommand请求数量低于此值时,熔断不会开启
requestVolumeThreshold:20
# 失败次数超过比例才开启熔断
errorThresholdPercentage: 50
# 强制开启熔断
#forceOpen: true
# 强制关闭熔断
#forceClosed: true
execution:
isolation:
# THREAD:单独开启线程执行;SEMAPHORE:在调用线程上执行(由于我们现有框架中FeignUserContextInterceptor中使用了ThreadLocal,所以必须使用第二种方式)
18. strategy: SEMAPHORE
19. thread:
20. # 执行超时时间(这个时间设置很重要,因为HystrixCommand会包装RibbonClient实例,那么这个时间就必须要大于ribbion timeout * retry,后面Ribbon章节会介绍)
timeoutInMilliseconds: 2000
semaphore:
# 由于我们使用SEMAPHORE模式,当每个feign并发发起请求超过此值时,请求会被拒绝,直接调用降级方法,异常信息关键字:could not acquire a semaphore for execution
maxConcurrentRequests: 1000
fallback:
isolation:
semaphore:
# 由于我们使用SEMAPHORE模式,当每个feign并发发起请求调用降级方法超过此值,调用降级方法会被拒绝,直接抛出异常,异常信息关键字:fallback execution rejected
maxConcurrentRequests: 1000
Feign Hystrix后备模式
后备模式就是在远程调用服务时,被断路器切断或服务调用超时时,返回的一种备用方案。应用举例如下:
直接设置fallback,该模式不便于调试具体远程服务调用出错的信息。
/**
* 服务发现模式
*/
@FeignClient(name = "eureka-client",fallback = OpenFeignFallbackServiceImpl.class)//eureka-client工程的服务名称
public interface OpenFeignService {
@GetMapping("/name")//这里的请求路径需要和eureka-client中的请求路径一致
public String test();//这里的方法名需要和eureka-client中的方法名一致
}
/**
* 服务发现-对应后备模式的方法定义
*/
@Service
public class OpenFeignFallbackServiceImpl implements OpenFeignService{
@Override
public String test() {
return "调用服务失败!";
}
除了fallback模式,还可以调用fallbackFactory,这种可以记录远程调用失败的具体明细异常。建议采用此方案设置后备模式。
/**
* 声明调用客户端
*/
@FeignClient(name = "wl-sku", url = "${wl.url}", path = "wl", fallbackFactory = WlSkuFeignFallbackFactory.class)
public interface WlSkuFeign {
/**
* 基于商品编码获取商品销售属性明细
*
* @param relationId 参数编码
* @return
*/
@RequestMapping(method = RequestMethod.GET, path = "/item/{relation_id}")
ResponseBody<GoodsItemDto, EmptyMeta> getItemDetail(@PathVariable("relation_id") Integer relationId);
}
/**
* 申明后备模式
*
*/
@Component
public class WlSkuFeignFallbackFactory implements FallbackFactory<WlSkuFeign> {
@Override
public WlSkuFeign create(Throwable cause) {
return relationId -> {
ErrorLogger.getInstance().log("商品sku getItemDetail降级服务", cause);
return ResponseBody.fallback(cause, new Error("getItemDetail", "商品服务不可用"));
};
}
}
Feign Hystrix舱壁(bulkhead)模式
Feign集成了Hystrix,也可以设置客户端为舱壁模式。通过设置Hystrix的配置文件即可。
Hystrix隔离级别由SEMAPHORE(信号量)模式切换为THREAD(线程池)模式,同时服务追踪功能相应调整适用THREAD模式。该模式有如下特性:
- 各上游服务(feign客户端)线程资源隔离,相互不影响,可以实现完全的独立配置。
- 由于feign请求是独立线程,才可以真正意义上的实现超时降级功能(使用semaphore实际上是假的超时功能,比如超时设置1S,实际执行3S,但整体还是会执行3S,只是3S后会抛出TimeoutException触发降级),而thread模式则能够正在的在1S后直接Interrupt请求线程且立刻触发降级,达到真正的断流保护作用。
- 开启线程池模式会额外开销服务器资源,在开启这种模式时,线程池的数量,服务器资源还是需要监控,综合设置。
Hystrix舱壁(bulkhead)模式常用配置文件:
# 全局统一配置
hystrix:
command:
default:
execution:
isolation:
# 更改为THREAD,其余SEMAPHORE开头的配置可以去掉
strategy: THREAD
thread:
# 默认1000
timeoutInMilliseconds: 2000
threadpool:
default:
# 这个属性很重要,默认false。当false时:maximumSize=coreSize,当true时:取值Math.max(maximumSize,coreSize),所以如果想设置最大数,必须设置为true
allowMaximumSizeToDivergeFromCoreSize: false
# 默认10
coreSize: 10
maximumSize: 10
# 默认1M,线程池内超过coreSize的线程允许最大空闲时间
keepAliveTimeMinutes: 1
# 等待队列,默认-1即SynchronousQueue,直接交由线程池拒绝或者等待
maxQueueSize: -1
# 默认5,这个值的出现是因为线程池的queueSize无法动态变更,所以用这个值可以动态变更来前置检测是否拒绝,当maxQueueSize为-1或者0时,这个检测直接通过后交由线程池自己处理,当maxQueueSize大于0时,由queueSize<queueSizeRejectionThreshold来决定是否拒绝请求,所以如果设置maxQueueSize,最终队列拒绝效果是以此值为准
queueSizeRejectionThreshold: 5
Feign Ribbon 负载均衡模式
Feign可通过配置参数设定Ribbon的运行模式,Ribbon配置(所有配置参考com.netflix.client.config.CommonClientConfigKey和com.netflix.client.config.DefaultClientConfigImpl)。一般设置负载均衡的重试机制,服务轮询模式,请求响应时间等参数。
Feign模式下Ribbon常用配置参数如下:
ribbon: # 默认相同的route不重试,可以避免一些各种重试引起的问题,简单化(但服务提供方还是应该尽量保证幂等性) MaxAutoRetries: 0 # 默认只重试不同route一次 MaxAutoRetriesNextServer: 1 # 由于在前面feign文档中已经讲到使用自己配置的HttpClient连接池,所以不需要配置ribbon连接池相关的任何属性(因为考虑到每个服务提供方的不同,后期可能会更改回来使用ribbon连接池方式) # 默认5000 ReadTimeout: 5000 # 默认2000 ConnectTimeout: 2000 # NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule #配置规则 随机 # NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #配置规则 轮询 # NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RetryRule #配置规则 重试 # NFLoadBalancerRuleClassName: com.netflix.loadbalancer.WeightedResponseTimeRule #配置规则 响应时间权重 NFLoadBalancerRuleClassName: com.netflix.loadbalancer.BestAvailableRule #配置规则 最空闲连接策 # 后续可能会自定义一些负载均衡策略,通过这里来设置 # ribbon子容器饥饿加载,避免偶尔因为服务重启后第一次发起请求时延迟加载耗时造成fallback,但是会增加系统启动时间(新版才支持) eager-load: enabled: true clients: - a - b - c #一个客户端远程多个微服务,可针对单个微服务做特殊配置 # ribbon客户端名称(即feign客户端名称) <clientName>: ribbon: listOfServers: www.baidu.com xxx: xxx
Spring Cloud Feign 注意事项
fallback
Feign降级本地实现,必须实现当前Feign接口,且必须声明为一个bean,feign调用异常时会自动调用实现方法。
@Component
public class WlFeignFallback implements WlFeign {
@Override
public ResponseBody<List<Object>, EmptyMeta> getTest() {
return ResponseBody.fail(new Error("xx", "xx"));
}
}
fallbackFactory
Feign降级工厂类,必须实现feign.hystrix.FallbackFactory接口,适用于复杂的根据异常类型动态选择降级实现类(也必须实现当前Feign接口),并且这个工厂类也必须声明为一个bean。(可以获取详细异常信息,首选)。
configuration
自定义的独立Feign客户端的配置类,可以覆盖Feign默认的任何通用的Logger.Level,Retryer,Request.Options,RequestInterceptor,SetterFactory。特别注意,自定义的Configuration类不能加 @Configuration 注解,否则会被自动扫描,注册到通用配置中,会被全局Feign使用,同时方法必须加 @Bean 注解。
/**
* feign全局配置
*
* @Configuration 加上为全局,不加为自定义
*/
@Configuration
public class FeignConfiguration {
/**
* feign日志
*/
@Profile({"self", "local", "dev"})
@Bean
public Logger.Level level() {
return Logger.Level.FULL;
}
/**
* http请求时长,最好小于hystrix时长
*/
@Bean
public Request.Options options() {
return new Request.Options(2000, 3500);
}
/**
* 使用默认的不重试机制,单独feign有特殊需求单独配置
*/
public Retryer retryer() {
// 最小重试间隔,最大重试间隔,最多尝试次数(包括第一次)
return new Retryer.Default(100L, 500L, 2);
}
url/path
显示声明固定服务访问路径,最终访问路径为:url+path( @FeignClient )+path( @RequestMapping )注意,无论使用自动服务发现还是固定访问路径方式, @FeignClient 注解的name或者value属性不能为空(serviceId已经摒弃)。
方法返回类型
通过Feign调用远程服务,可以定义调用的方法返回void,业务对象类型或者 feign.Response 复杂类型。
method
必须使用 @RequestMapping 显式声明method,不能使用 @GetMapping 或者 @PostMapping 。
// 显示指定方法 @RequestMapping(method = RequestMethod.POST)
consumes
凡是使用PHP服务,因为请求必须为json,必须添加consumes=MediaType.APPLICATION_JSON_VALUE(不能使用MediaType.APPLICATION_JSON_UTF8_VALUE,因为apache http ContentType在校验时不允许有'“‘,',‘,';‘出现,详情参考: org.apache.http.entity.ContentType valid(String s) 方法)。
GET请求复杂对象
// 方式1:使用Map传输
@RequestMapping(path="xxx", method=GET)
ResponseBody<T> test(@RequestParam Map<String, Object> map) {
}
// 方式2:独立设置param
@RequestMapping(path="xxx", method=GET)
ResponseBody<T> test(@RequestParam("aaa") String aa, @RequestParam("bb") int bb) {
}
支持application/x-www-form-urlencoded格式http接口
// 如果接口返回类型是text/html,必须用string接受,然后手动反序列化,如果是applicatin/json,则可以直接用对象接受
@RequestMapping(path="xxx", method=POST, consumes=MediaType.APPLICATION_FORM_URLENCODED_VALUE)
public String test(@RequestBody MultiValueMap<String, String> map) {
}
@RequestMapping(path="xxx", method=POST, consumes=MediaType.APPLICATION_FORM_URLENCODED_VALUE)
public RequestBody test(String content) {
}
Feign,Hystrix,Ribbon配置参数注意
Feign本身可以设置重试,还可以设置请求时长,Hystrix设置熔断,Ribbon可以设置重试机制,请求时长。这些参数在配置时,要合理设置,避免冲突。为了确保Ribbon重试的时候不被熔断,就需要让Hystrix的超时时间大于Ribbon的超时时间,否则Hystrix命令超时后,该命令直接熔断,重试机制就没有任何意义了。
#ribbon超时配置为2000,请求超时后,该实例会重试1次,更新实例会重试1次。 service-hi: ribbon: ReadTimeout: 2000 ConnectTimeout: 1000 MaxAutoRetries: 1 MaxAutoRetriesNextServer: 1 hystrix: command: default: execution: timeout: enabled: true isolation: thread: timeoutInMilliseconds: 8000
Feign的HTTP Client
Feign在默认情况下使用的是JDK原生的URLConnection发送HTTP请求,没有连接池,但是对每个地址会保持一个长连接,即利用HTTP的persistence connection 。建议采用Apache的HTTP Client替换Feign原始的http client, 从而获取连接池、超时时间等与性能息息相关的控制能力。Spring Cloud从 Brixtion.SR5 版本开始支持这种替换,首先在项目中声明Apache HTTP Client和 feign-httpclient 依赖。
<!-- 使用Apache HttpClient替换Feign原生httpclient -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
</dependency>
<dependency>
<groupId>com.netflix.feign</groupId>
<artifactId>feign-httpclient</artifactId>
<version>${feign-httpclient}</version>
</dependency>
为了合理的利用Apache HTTP Client做http请求,建议自定义http请求的配置参数。
@Bean(destroyMethod = "close")
public CloseableHttpClient httpClient() {
// 最终存活时间还需要看服务端的keep-alive设置,和空闲时间以及间歇的validate是否通过
PoolingHttpClientConnectionManager pool = new PoolingHttpClientConnectionManager(30, TimeUnit.SECONDS);
pool.setMaxTotal(2000);
// 目前只有一个路由,默认等于最大值,根据业务并发量设置
pool.setDefaultMaxPerRoute(2000);
// 检查非活动连接,避免服务端重启后或者服务端keep-alive过期主动关闭连接造成失效,对于微服务场景可能还比较普遍,但受限HTTP设计理念,这也并发完全可靠,使用re-try/re-execute机制来弥补,考虑到可能很多Niginx配置为5秒keep-alive
// TODO 这个值还待商榷
pool.setValidateAfterInactivity(5 * 1000);
return HttpClients.custom()
.setConnectionManager(pool)
// 连接空闲10s就回收,这个会启动独立线程检测,所以必须声明destroy方法来关闭独立线程
.evictIdleConnections(10, TimeUnit.SECONDS)
// 建立连接时间和从连接池获取连接时间,以及数据传输时间
.setDefaultRequestConfig(RequestConfig.custom()
// http建立连接超时时间
.setConnectTimeout(1000)
// 从连接池获取连接超时时间
.setConnectionRequestTimeout(3000)
// socket超时时间
.setSocketTimeout(10000)
.build())
// 自定义重试机制
.setRetryHandler((exception, executionCount, context) -> {
// 目前只允许重试一次
if (executionCount > 1) {
return false;
}
// 如果是服务端主动关闭连接的,数据并没有被服务端接受,可以重试
if (exception instanceof NoHttpResponseException) {
return true;
}
// 不要重试SSL握手异常
if (exception instanceof SSLHandshakeException) {
return false;
}
// 超时
if (exception instanceof InterruptedIOException) {
return false;
}
// 目标服务器不可达
if (exception instanceof UnknownHostException) {
return false;
}
// SSL握手异常
if (exception instanceof SSLException) {
return false;
}
HttpClientContext clientContext = HttpClientContext.adapt(context);
HttpRequest request = clientContext.getRequest();
String get = "GET";
// GET方法是幂等的,可以重试
if (request.getRequestLine().getMethod().equalsIgnoreCase(get)) {
return true;
}
return false;
})
// 默认的ConnectionKeepAliveStrategy就是动态根据keep-alive计算的
.build();
}
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
主要内容:数据量,硬件依赖,特色工程在本章中,我们将讨论机器和深度学习概念之间的主要区别。 数据量 机器学习使用不同数量的数据,主要用于少量数据。另一方面,如果数据量迅速增加,深度学习可以有效地工作。下图描绘了机器学习和深度学习在数据量方面的工作 - 硬件依赖 与传统的机器学习算法相反,深度学习算法设计为在很大程度上依赖于高端机器。深度学习算法执行大量矩阵乘法运算,这需要巨大的硬件支持。 特色工程 特征工程是将领域知识放入指定特征的
-
本节将讨论优化与深度学习的关系,以及优化在深度学习中的挑战。在一个深度学习问题中,我们通常会预先定义一个损失函数。有了损失函数以后,我们就可以使用优化算法试图将其最小化。在优化中,这样的损失函数通常被称作优化问题的目标函数(objective function)。依据惯例,优化算法通常只考虑最小化目标函数。其实,任何最大化问题都可以很容易地转化为最小化问题,只需令目标函数的相反数为新的目标函数即可
-
词向量 自然语言需要数学化才能够被计算机认识和计算。数学化的方法有很多,最简单的方法是为每个词分配一个编号,这种方法已经有多种应用,但是依然存在一个缺点:不能表示词与词的关系。 词向量是这样的一种向量[0.1, -3.31, 83.37, 93.0, -18.37, ……],每一个词对应一个向量,词义相近的词,他们的词向量距离也会越近(欧氏距离、夹角余弦) 词向量有一个优点,就是维度一般较低,一般
-
主要内容 课程列表 专项课程学习 辅助课程 论文专区 课程列表 课程 机构 参考书 Notes等其他资料 卷积神经网络视觉识别 Stanford 暂无 链接 神经网络 Tweet 暂无 链接 深度学习用于自然语言处理 Stanford 暂无 链接 自然语言处理 Speech and Language Processing 链接 专项课程学习 下述的课程都是公认的最好的在线学习资料,侧重点不同,但推
-
Google Cloud Platform 推出了一个 Learn TensorFlow and deep learning, without a Ph.D. 的教程,介绍了如何基于 Tensorflow 实现 CNN 和 RNN,链接在 这里。 Youtube Slide1 Slide2 Sample Code
-
现在开始学深度学习。在这部分讲义中,我们要简单介绍神经网络,讨论一下向量化以及利用反向传播(backpropagation)来训练神经网络。 1 神经网络(Neural Networks) 我们将慢慢的从一个小问题开始一步一步的构建一个神经网络。回忆一下本课程最开始的时就见到的那个房价预测问题:给定房屋的面积,我们要预测其价格。 在之前的章节中,我们学到的方法是在数据图像中拟合一条直线。现在咱们不