
第4章 不只是编码
If you want to go fast, go alone.
If you want to go far, go together.
——非洲谚语
前面我们学习了PhalApi框架的基础内容,以及高级主题,但这些内容都是针对于框架内部本身的介绍。在实际项目开发中,从项目立项到交付给最终用户使用,这个过程,除了编写代码外,还有很多事件要做,而且需要使用更多的外部工具,与更多不同角色的人员一起合作。所以这一章,我们将会进行面的学习。
本章涉及的内容主要有测试驱动开发、设计模式、重构。这些内容在软件开发中都是需要的,而且不限于任何语言,更不限于任何开发框架。在这里之所以再次讲述,是为了让开发人员更好地理解如何在PhalApi框架开发下进行最佳实践。
4.1 测试驱动开发
做正确的事,比把事情做正确更为重要。
当明确需要做何事后,再通过事先编写单元测试来准确表达我们将要实现的功能,是相当具有指导意义的。你会发现接下来你的开发历程就是:单元测试-设计-重构,而且这种正向循环是很有创造性的,并且进行到一定程度后会慢慢体会到浮现式设计的乐趣。
此外,在具备自我验证能力下的单元测试套件下,更是为我们搭建了一个360度的安全网,一个可以任意大胆进行各种尝试的沙箱环境,并能最大程度上让核心业务逻辑得以保证,从而保证了最终的交付质量。其中,快速反馈大大缩短了等待的周期,以便我可以快速发现问题、定位问题、修复问题、再回归测试验证。而通过层层验证的核心业务,更是让我们增大了自身对代码质量的信心。
关于测试驱动开发TDD,有很多资料已进行了说明,我们将进行简单的回顾,然后重点学习如何具体在PhalApi中进行测试驱动开发。
4.1.1 意图导向编程、原则与模式
意图导向编程
当开发一个需求时,理想的状态从起点到终点可以直线到达,不做一点无用功,但这也是几乎不可能的,没有代码可以只编写一次就能成为最终的产品代码。实际情况更多是,需要在这个开发过程中进行一些探索,最终找到一条合适的路径到达终点,虽然这个过程有点点波折,但却是目前我们所能找到的最短路径。最糟糕的情况莫过是,在探索过程中,我们离目标终点越行越远,甚至忘记了此行的目的,不仅做了很多无用功,还引入了不必要的复杂性,虽然最终也到达了目的地,却留下难以维护、难以理解的代码。而在意图导向编程下,我们可以再次回归到最佳的状态,因为有了指引,而不至于迷失开发方向。
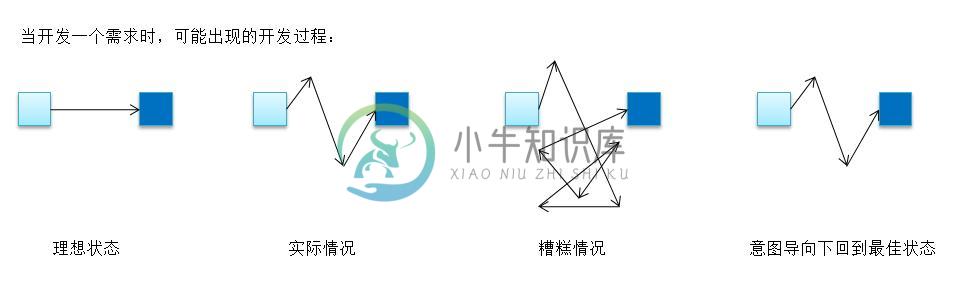
图4-1 摘自《测试》的图
在编写代码前,先写测试代码,更容易提高我们开发的关注点 。因为,在开发过程中, 作为开发工程师,大多时候会被外界不停地打断,例如需求沟通、线上问题处理、临时会议、新邮件提醒等,这些打断开发思路的事情还不算人个事务在内,例如上洗手间、接听电话等。而通过单元测试则可以让你“几乎忘却需要做什么”的情况下重新让你回到之前的状态,特别在并行开发多个不同项目的需求时尤其重要。
遵循测试驱动开发最佳实践,有助保持流状态的意图导向编程。它最重要的好处在于可以帮助我们保持住上下文,以帮助我们在纷繁的工作中保持难得的流状态。频繁地切换思路,势必会影响我们对开发的状态投入,尤其长时间的打断会严重让我们忘却之前在大脑临时内存区域的一些重要待办事项。而“红-绿-重构”下的测试驱动开发,能够帮助我们保持对最终达成目标的关注。即,失败的测试帮助了我们持久化记住了之前那一历史时刻大部分的信息和场景概况。除此之外,遵循“红-绿-重构”这样的流程,我们可以在更高的层面关注需要实现的功能需求,并自顶而下地进行设计优化,精益代码。
编写测试的原则、模式和指导
首先应该意识到,测试代码和生产代码一样重要。其次,测试代码也应该和生产代码一样被同步维护更新,这样才能保持生气,更大地发挥作用。只有当不断地对测试的代码进行修修补补,我们才能保持自动化测试这张“安全网”常新。
编写单元测试的原则,前面已经有前辈总结,可参考F.I.R.S.T.原则。
- 快速 Fast
- 独立 Independent
- 可重复 Repeatable
- 自足验证 Self-validating
- 及时 Timely
编写单元测试的模式,可参考构造-操作-检验(BUILD-OPERATE-CHECK)模式。这个模式也可以理解成:“当... 做...应该...”。其中,构造包括测试环境的搭建、测试数据前期的准备;操作是指对被测试对象的调用, 以及被测试对象之间的通信和协助交互;最后检验则是对业务规则的断言、对功能需求的验证。
以下是关于如何编写高效测试代码的一些建议。
- 1、与产品代码分开,与测试代码对齐
- 2、利用测试骨架自动生成测试代码
- 3、使用测试替身、测试桩构建昂贵资源、制造异常情况
- 4、每个测试一个概念
4.1.2 在PhalApi下进行TDD的一般步骤
接口服务提供的功能,与图形界面软件提供的功能不一样,接口服务的功能是看不见,摸不着的,没有图形可视化,也可以人性的交互。但也正这样,接口服务是最适合也是最有必要进行单元测试的领域。
在使用phalApi进行接口服务开发时,我们强烈推荐采用测序驱动开发的方式快速开发接口服务。其目的主要是提高我们的开发速度的同时,提升接口服务的代码质量,降低风险。我们致力于以简单的方式编写接口服务,我们也更应该致力于提供稳定可靠的接口服务,因为直接用户是我们的接口服务的客户端,而最终用户是普通的使用用户,也是我们项目的消费者。通过提供有价值的,针对特定领域业务的服务,不仅体现了我们搭建接口系统的价值,更是体现了我们作为开发工程师所创造的价值。
前置条件
在PhalApi下进行测试驱动开发之前,需要一些前置条件。首先,已经部署好PhalApi开发环境,并已创建具体的开发项目。还记得吗?创建项目的方式有多种,可以通过可视化安装向导创建,也可以使用phalapi-buildapp脚本命令,还可以手动创建。在本书中,我们使用的是模拟的商城Shop项目。
其次,确保已安装PHPUnit并且可以正常使用,并且生成测试代码骨架的phalapi-buildtest脚本命令已有执行权限。当PHPUnit安装成功后,查看其版本可以看到:
$ phpunit --v
PHPUnit 4.3.4 by Sebastian Bergmann.
PHPUnit官网:https://phpunit.de
最后,也是最重要的,待开发的接口服务的需求已理解并已经明确。即,已经清楚地知道我们将要做什么。如果对需求还是模棱两可,建议你先和产品人员继续沟通,直到需求明确后再回来编码开发。
一般开发步骤
在准备好这些准备工作后,便到了在PhalApi进行测试驱动开发这一环节。这个过程的一般步骤可总结为:
- 1、在接口类中定义接口服务的函数签名
- 2、使用phalapi-buildtest为接口类生成测试代码骨架
- 3、完善接口类的测试用例,让测试失败
- 4、在意图导向下完成具体功能开发,让测试通过
- 5、进行适当的重构,追求更高的代码质量
- 6、为领域业务类和数据模型类补充对应的测试代码
- 7、执行单元测试套件,确保全部测试通过,没有引入新的问题
这些步骤都是具体的,所以实际操作起来并没有太大问题。下面我们将通过一个示例,结合以上步骤,进行具体的讲解。
获取评论接口服务开发示例
在前面,我们在搭建RESTful API时,创建了评论接口服务,它提供获取评论、添加评论、更新评论和删除评论了这些功能。这里,我们以获取评论接口服务为例,讲解如何进行测试驱动开发。而其他操作,如添加、更新和删除的开发类似,感兴趣的读者在学习完成获取评论的开发后,也可以参考此一般步骤亲自进行尝试。
- 0、在开始之前
有个约定成俗的做法就是,在开始测试驱动开发之前,应先执行一次全部的单元测试,确保当前全部的测试是通过的。若不是,则应该进行相应的调整。如果是测试代码未及时同时,则更新对应失败的单元测试。如果是产品代码有BUG,那么恭喜你,有了意外的收获。例如,在这里,Shop项目下的单元测试是全部通过的。
$ cd ./Shop/Tests
$ phpunit
PHPUnit 4.3.4 by Sebastian Bergmann.
Configuration read from /path/to/PhalApi/Shop/Tests/phpunit.xml
..........
Time: 71 ms, Memory: 8.25Mb
OK (10 tests, 16 assertions)
- 1、在接口类中定义接口服务的函数签名
假设我们评论的接口类尚未存在,在明确了获取评论的需求后,我们可以先创建对应的接口类,并在里面添加成员函数,通过参数规则配置指定所需要的接口参数,以及在函数注释上注明返回结果的字体。
可以想到,此获取评论接口服务,需要一个评论ID参数,此ID是一个正整数,且为必须。返回的字段应该包含评论ID和评论内容,若评论不存在时,则不返回这些字段。和前面一样,这里将获取评论的接口服务名称命名为:Comment.Get,则可得到以下这样的定义了函数签名的初步代码。
// $ vim ./Shop/Api/Comment.php
<?php
class Api_Comment extends PhalApi_Api {
public function getRules() {
return array(
'get' => array(
'id' => array('name' => 'id', 'type' => 'int', 'require' => true, 'min' => 1, 'desc' => '评论ID'),
),
);
}
/**
* 获取评论
* @desc 根据评论ID获取对应的评论信息
* @return int id 评论ID,不存在时不返回
* @return string content 评论内容,不存在时不返回
*/
public function get() {
}
}
通过在线接口详情文档,可以看到对应生成的接口文档内容。

图4-2 获取评论的在线接口详情文档
这样就完成了我们伟大的第一步,是不是很简单,很有趣?虽然万事开头难,但根据前面所学的知识,完成这一步应该难度不大。接下来,将进入测试驱动开发的真正环节,也是我们开始接触到单元测试代码的环节。
- 2、使用phalapi-buildtest为接口类生成测试代码骨架
Api接口层,是后端开发的主要切入点,也是直接对外提供服务的入口,属于高层次的概念并拥有指定的业务功能。所以在对新接口进行开发前,为接口类编写单元测试是非常有意义的。
准备好接口服务的函数签名的定义后,便可以使用phalapi-buildtest命令生成对应的测试骨架代码了。此命令的使用非常简单,在前面也已进行了相应的说明。这里再稍微重复讲解一下如何使用。phalapi-buildtest的第一个参数是待测试的文件路径,可以是绝对路径,也可以是相对于当前执行目录的相对路径,第二个参数是待测试的类名。如果只是提供了前面这两个参数,会提示PhalApi_Api类未找到。
Tests$ ../../PhalApi/phalapi-buildtest ../Api/Comment.php Api_Comment
PHP Fatal error: Class 'PhalApi_Api' not found in /path/to/PhalApi/Shop/Api/Comment.php on line 6
这是因为缺少了启动文件,缺少了使用自动加载,这时通常需要在第三个参数指定test_env.php文件。即:
Test$ ../../PhalApi/phalapi-buildtest ../Api/Comment.php Api_Comment ./test_env.php
<?php
/**
* PhpUnderControl_ApiComment_Test
*
* 针对 ../Api/Comment.php Api_Comment 类的PHPUnit单元测试
*
* @author: dogstar 20170518
*/
... ....
这时已经可以正常生成测试骨架的代码了,可以添加第四个参数指定作者名称,最后重定向保存到对应的测试文件即可。
Test$ ../../PhalApi/phalapi-buildtest ../Api/Comment.php Api_Comment ./test_env.php > ./Api/Api_Comment_Test.php
保存好生成的代码后,通常还需要修改里面的test_env.php文件的加载路径,以便可以在测试时加载项目的初始化文件,以及进行一些准备工作,例如提供Mock替身,设置测试环境的配置等。如这里的:
// Test$ vim ./Api/Api_Comment_Test.php
require_once dirname(__FILE__) . '/../test_env.php';
调整完毕后,可以试运行一下单元测试。
Tests$ phpunit ./Api/Api_Comment_Test.php
There was 1 error:
1) PhpUnderControl_ApiComment_Test::testGet
PhalApi_Exception_InternalServerError: 服务器运行错误: PhalApi_Api::$id 未定义
/path/to/PhalApi/PhalApi/PhalApi/Api.php:55
/path/to/PhalApi/Shop/Api/Comment.php:34
/path/to/PhalApi/Shop/Tests/Api/Api_Comment_Test.php:45
FAILURES!
Tests: 2, Assertions: 0, Errors: 1.
暂且不管当前测试是否可以通过,因为目前生成的测试代码,只是简单地调用,如果查看生成的测试代码,可以看到这样的调用代码。
// Test$ vim ./Api/Api_Comment_Test.php
/**
* @group testGet
*/
public function testGet()
{
$rs = $this->apiComment->get();
$this->assertTrue(is_int($rs));
}
由于再次生成测试代码时,重定向保存时会覆盖原来的测试代码。这里有一个小技巧,就是提前定义好接口类的全部成员函数,然后再一次性生成全部的测试骨架代码。如果是后面迭代时再添加的成员函数,也可以手动添加对应的测试代码。
- 3、完善接口类的测试用例,让测试失败
单元测试的编写,如前面所说,可参考F.I.R.S.T.原则和构造-操作-检验模式。但对于接口类的构造环节,由于需要在内部模拟发起接口请求,我们需要使用PhalApi提供的辅助类PhalApi_Helper_TestRunner::go($url, $params = array())执行接口服务,它的第一个参数是接口服务URL,里面需要包含service参数,第二个可选参数是更多接口参数。
根据构造-操作-检验模式,再结合辅助类,根据获取评论接口服务的定义,可以通过获取评论ID为1的评论,并验证其返回格式和内容进行验证。即:
// Test$ vim ./Api/Api_Comment_Test.php
/**
* @group testGet
*/
public function testGet()
{
// Step 1. 构建
$url = 'service=Comment.Get';
$params = array('id' => 1);
// Step 2. 执行
$rs = PhalApi_Helper_TestRunner::go($url, $params);
// Step 3. 验证
$this->assertEquals(1, $rs['id']);
$this->assertArrayHasKey('content', $rs);
}
上面的单元测试的意思简单明了,结合构造-操作-检验模式再加以说明一下。
首先,是第一步构建。
// Step 1. 构建
$url = 'service=Comment.Get';
此$url参数即对应接口请求时的URL参数,将$url追加在项目访问入口后面,并在浏览器打开可以得到同样的执行效果。但这样的好处更在于通过单元测试帮我们记住各种接口测试的业务场景,而不再是像以前那样打开N个浏览器窗口人工进行调试和人工重复性的验证,也不用像以前那样苦苦寻找浏览器记录。
如果接口需要POST数据,或者其他更多参数,可以使用$params来传递更多参数,一如:
$params = array('id' => 1);
接下来,就是执行。这里的操作,显然就是对应我们接口服务的调用。简单地如:
// Step 2. 执行
$rs = PhalApi_Helper_TestRunner::go($url, $params);
这样,便可以在服务端模拟进行一次接口的请求调度,注意这里是在服务端进行的接口请求,而不是客户端。这样的好处是可以进行白盒测试,则不是黑盒测试,从而可以得出代码测试覆盖率。
最后,是验证。在对接口返回的结果中,我们可以这样依次进行正确性的验证:先验证接口返回的格式是否正确,有无字段遗漏;再返回的业务数据是否正确。
// Step 3. 验证
$this->assertEquals(1, $rs['id']);
$this->assertArrayHasKey('content', $rs);
由于测试环境的数据变动频繁,所以我们可以针对个别的接口进行更精确的验证,而对类似列表获取这样的大批量的数据,则校验其结构格式。除此之外,还有一种情况也是需要纳入检验,即除了上面的正常请求情况下的异常请求。
当获取评论的接口服务功能未具体实现时,运行此单元测试,应该是失败的,并且失败信息提示评论ID不等于期望的1。
1) PhpUnderControl_ApiComment_Test::testGet
Failed asserting that null matches expected 1.
到了这一步,我们的意图已经很明确,那就是能正常获取到评论的内容并返回。
- 4、在意图导向下完成具体功能开发,让测试通过
接下来,就是如何具体实现此获取评论的功能。假设我们的评论内容存在MySQL数据库中,同时为了方便演示下一步的重构,这里暂时先在Api层完成全部的功能开发。但请注意,再一次强调,不应该把全部的功能都塞在Api层,而是应该根据ADM分层结构进行合理的职责划分和分配。
由于需要使用到MySQL数据库,因此这里稍微做一下准备工作。首先是数据库的创建与配置,然后创建评论数据库表和添加一些测试数据。以下是相应的SQl语句。
CREATE TABLE `pa_comment` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '评论ID',
`content` varchar(1024) DEFAULT '' COMMENT '评论内容',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `pa_comment` VALUES ('1', '欢迎使用PhalApi开源接口框架!');
准备好数据库相关的工作后,便可以使用NotORM提供的接口进行对数据库的数据获取。由于这里采用是不恰当的开发方式,需要使用全局的NotORM实例进行操作数据库,因此最初丑陋的实现代码是:
// $ vim ./Shop/Api/Comment.php
public function get() {
return DI()->notorm->comment->where('id', $this->id)->fetchRow();
}
虽然丑陋,但也简单。
此时,重新执行一下单元测试,可以看到是通过的了!
Tests$ phpunit ./Api/Api_Comment_Test.php
... ...
OK (2 tests, 2 assertions)
这时,也可以通过正常正式的方式,访问此获取评论的接口服务,看下是否真的已经可以工作并提供真实的数据。
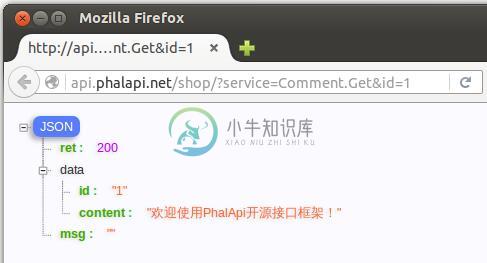
图4-3 初步实现获取评论的运行效果
但故事到此就结束了吗?如果只是单纯编写一个示例代码,差不多到此可暂告生段落。但如果我们开发编写的是用于提供商业服务,最终会投入市场使用的产品代码,那么这仅仅是一个开始。下面会继续进行讲解。
- 5、进行适当的重构,追求更高的代码质量
当功能开发完成后,也通常单元测试后,就可以考虑进行重构了。这时需要重构的内容,可以有以下这些方面进行考虑。
- 是否已按ADM分层模式进行开发?
- 是否已满足非功能性的要求?例如是否需要添加缓存?
- 是否已处理异常的情况?例如获取的数据不存在怎么办?
- 是否已抽离与业务无关、公共的代码?例如提取重复的实现,封装到扩展类库。
- 是否忆消除发现的代码异味?例如明显的重复代码。
- .. ...
关于重构的具体实现方式,在4.3 小步重构一节中会进一步讲解。
- 6、为领域业务类和数据模型类补充对应的测试代码
通常情况下,遵循ADM分层模式编写的接口服务的代码,会有Api类、Domain类和Model类这三个类。但前面我们只是为A类生成了测试代码,虽然在Api这上高层的意图导向下可以很好地完成功能的开发,但为了更全面地保障内部实现细节的正确性,我们有必要对领域业务类和数据模型类也补充对应的测试代码。尤其是领域业务类,更是我们关注的重中之重,因为这一层有着复杂的规则,重要的领域业务逻辑,也是最容易出现问题的热区。
再一次,可以使用phalapi-buildtest命令为Domain类和Model类生成测试骨架代码。
Tests$ ../../PhalApi/phalapi-buildtest ../Domain/Comment.php Domain_Comment > ./Domain/Domain_Comment_Test.php
Tests$ ../../PhalApi/phalapi-buildtest ../Model/Comment.php Model_Comment ./test_env.php > ./Model/Model_Comment_Test.php
然后,进行相应的调整、修改和编写单元测试代码,运行即可。以Domain_Comment类的单元测试为例,我们分别获取一个存在的评论,和一个不存在的评论,并进行相应的验证。关键的代码如下:
// Tests$ vim ./Domain/Domain_Comment_Test.php
require_once dirname(__FILE__) . '/../test_env.php';
class PhpUnderControl_DomainComment_Test extends PHPUnit_Framework_TestCase
{
public function testGet()
{
$id = '1';
$rs = $this->domainComment->get($id);
$this->assertNotEmpty($rs);
}
public function testGetNone()
{
$id = 404;
$rs = $this->domainComment->get($id);
$this->assertEmpty($rs);
}
}
其中,评论ID为404是不存在的评论。编辑好保存后,执行一下此单元测试,是可以通过的。
Tests$ phpunit ./Domain/Domain_Comment_Test.php
... ...
OK (2 tests, 2 assertions)
Model类与此类似,这里不再赘述。
- 7、执行单元测试套件,确保全部测试通过,没有引入新的问题
最后一步,其实也相当于回到了起点。即执行全部的单元测试,并确保全部的测试都是通过的。不现的时,现在我们有了新的单元测试,有了上面评论接口服务对应的单元测试,当准备把代码提交到仓库然后快乐下班之前,我们有必要确认新增加的代码和功能是可以正常运行外,还要确认已有的代码和功能不受影响。
在单元测试目录下,执行phpunit命令,便可执行全部的单元测试,其使用的配置是当前目录的phpunit.xml文件。执行后,可以看到全部的测试都测试通过,且测试用例从原来的10个增加到15个,断言从原来的16个增加到20个。我们的测试势力又强大了!强大的单元测试体系,势必会带来更强大的代码质量。
Tests$ phpunit
... ...
OK (15 tests, 20 assertions)
4.1.3 对接口类的三角验证
如果细细观察,会发现上面实现的代码是很脆弱的。线上环境之所以出现问题,往往是因为我们在前面思考得还不够全面,还不够深入。若在开发阶段,通过测试驱动开发,提前预测或者思考日后线上可能发生的问题的话,那么我们开发的代码就能具有更强大的生存和适应能力。
为了编写出更全面的测试用例,这里分享一下在《测试》一书中讲到的三角验证。
三角验证思路很简单,首先编写一个正常数据处理的测试用例,再编写另外一个正常数据处理的测试用例,最后编写一个失败或异常的测试用例。通过不同的维度,对待测试的类进行全方位的测试。
例如,继续前面获取评论的单元测试,我们先手动追加一条测试数据。
INSERT INTO `pa_comment` VALUES ('2', '欢迎阅读《初识PhalApi》~');
前面对于接口类Api_Comment的单元测试,已经测试了获取评论ID为1的数据,现在让我们再来添加获取评论ID为2的数据,并进行验证。
// Tests$ vim ./Api/Api_Comment_Test.php
public function testGetAgain()
{
$url = 'service=Comment.Get';
$params = array('id' => 2);
$rs = PhalApi_Helper_TestRunner::go($url, $params);
$this->assertEquals(2, $rs['id']);
$this->assertArrayHasKey('content', $rs);
}
再次执行此单元测试,验证通过。
有读者可能会觉得添加对评论ID为2的获取验证,显得多此一举。确实是有一点,这是因为我们的评论接口服务功能已经开发完成。而三解验证主要是应用在测试驱动开发阶段,即在功能未开发完成的时候。还记得,我们最初模拟获取评论的实现代码吗?它是这样的:
public function get() {
return array('id' => $this->id, 'content' => '模拟获取:评论内容');
}
对于这样的情况,上面的测试是有效的。因为它发现了我们正在“造假”,而不是返回真正的业务数据。
继续往前,除了正常情况外,我们还要验证失败或异常情况时,接口服务能否按预期那样响应。例如接口参数非法时怎么办,业务数据不存时怎么处理,调用第三方接口服务超时如何响应,数据库连接不上时如何降级等。对于此获取评论的接口,让我们来验证一下获取一个不存在的评论内容时,是否能按期望那样返回一个空数组。
先添加多一个测试用例,故意获取一个不存在的评论。
// Tests$ vim ./Api/Api_Comment_Test.php
public function testGetNotExists()
{
$url = 'service=Comment.Get';
$params = array('id' => 404);
$rs = PhalApi_Helper_TestRunner::go($url, $params);
$this->assertSame(array(), $rs);
}
需要注意的是,最后的断言,使用的是assertSame(),保证返回的结果的值和类型都是对的,即应该是空数组,不是FALSE,也不是0,更不是NULL。
这里,再次执行此单元测试,会发现,断言失败了!
1) PhpUnderControl_ApiComment_Test::testGetNotExists
Failed asserting that false is identical to Array &0 ().
这表明,前面看似能很好工作的代码,并没有完全按照我们的期望提供服务。而这个问题最终有可能会导致什么问题呢?这要视具体的业务而定,但如果约定在未找到评论时返回空数组,实际上却返回的是布尔值FALSE,在使用Javascript、Java或者Object-C开发的客户端就可能会产生一些奇怪的问题,甚至会导致客户端崩溃。因为返回的类型与预期的不一致。还好,我们及时发现了这个问题。
归其原因,是因为NotORM在向数据库获取数据时,若数据纪录不存在,会返回FALSE。知道了问题所在和对应的原因后,要修改优化就很容易了,只需要在Domain层对Model返回的数据进行判断即可。
// $ vim ./Shop/Domain/Comment.php
<?php
class Domain_Comment {
public function get($id) {
$model = new Model_Comment();
$rs = $model->get($id);
// 判断数据有效性
return !empty($rs) ? $rs : array();
}
}
当然,三角验证不是意味着只有三个测试用例,而是从不同的维度进行验证,包括正常的场景,失败的场景,异常的场景等等。通俗来说,就是想尽一切办法,通过不同的方式验证你的代码的正确性。又比如,对于未传递评论ID或者传递了错误的评论ID时,让我们来验证一下是否如期返回错误提示。
// Tests$ vim ./Api/Api_Comment_Test.php
/**
* @expectedException PhalApi_Exception_BadRequest
*/
public function testGetWithWrongId()
{
$url = 'service=Comment.Get';
$params = array('id' => 'a_wrong_id');
$rs = PhalApi_Helper_TestRunner::go($url, $params);
}
在上面的测试用例中,我们故意传递了值为“a_wrong_id”的评论ID,显然这是错误的参数,并且应该抛出PhalApi_Exception_BadRequest异常,所以我们通过@expectedException注解对此进行了断言。
随着单元测试的不断完善,和生产品代码的不断演进,最后我们将会得到更高质量的代码,和更大的自信心。
4.1.4 “造假”技巧
根据前面所提到的构造-操作-检验模式,在编写单元测试时,首先需要进行的就是构造一个测试场景。但很多时候,待测试的功能实现又依赖于第三方接口或者外部数据。对于这些场景,更好的方案应该是模拟测试数据,也就是利用桩、替身、外部依赖注入等技巧来模拟测试数据,以达到更灵活、覆盖率更高的测试以及制造所需要的待测试场景。
这也是编写单元测试中难度最大、维护成本最高的一部分。为了方便更多读者掌握“造假”技巧,降低对编写单元测试的学习成本,根据这几年的开发经验,下面我将总结在PhalApi下的9个造假技巧。
在开始学习“造假”技巧之前,首先最重要的一个原则是:“给我一个入口,我可以模拟任何数据。” 还有一个前提是:尽量不修改产品源代码。其次,通常情况下,部分代码的写法会严重限制、甚至根本无法对其进行模拟,也就无法进行更好地单元测试。所以不被提倡的写法有:
- 不提倡使用面向过程的函数
- 不提倡使用静态类成员函数
- 不提倡使用private级别的类成员函数/属性
通过构造参数实现外部依赖注入
很多类在实现功能时,需要拥有于外部其他协作类,即聚合关系,或依赖其他服务实现技术功能,像委托关系。在对这类类进行测试时,可以通过构造函数实现外部依赖注入。
在扩展类库中,我们可以看到很多这样场景。一如七牛扩展中构造函数的配置参数。
// $ vim ./Library/Qiniu/Lite.php
class Qiniu_Lite {
public function __construct($config = NULL) {
$this->config = $config;
if ($this->config === NULL) {
$this->config = DI()->config->get('app.Qiniu');
}
... ...
七牛扩展所需要的配置,可以使用默认的'app.Qiniu'配置,也可以通过构造参数从外部指定。所以在测试时,便可以这样提供测试环境的配置。
$config = array(
... ...
);
DI()->qiniu = new Qiniu_Lite($config);
除此之外,也可以通过修改配置文件所在的目录路径来切换单元测试时的配置。细心的读者会发现,这也是通过构造参数实现外部依赖注入的。
// 配置
DI()->config = new PhalApi_Config_File( '/path/to/Tests/Config');
虽然,上面注入的都是基本类型的数据,而非类实例。但也有类实例作为构造参数的示例。例如代理模式下的PHPRPC扩展,其构造参数就是PhalApi类实例。
// $ vim ./Library/PHPRPC/PhalApi.php
<?php
class PHPRPC_PhalAPi {
public function __construct($phalapi = NULL) {
if ($phalapi === NULL) {
$phalapi = new PhalApi();
}
... ...
在对此类进行测试时,我们也可以类似地进行外部模拟注入。
通过方法参数实现外部依赖注入
在很多时候,我们的功能类里只是有个别的操作需要用到特定的外部资源、协作类或者服务,或者本身就是为了提供服务而无状态。这样的话,可以直接通过方法参数来实现外部依赖注入。
例如,需要使用PHPMailer扩展进行邮件发送作为提醒的领域业务类,可以这样编写。
<?php
class Domain_Push {
public function notice($phpmailer, $address) {
// 前期准备 ...
$phpmailer->send($address, '注册激活', '欢迎注册,请点击激活!');
// 更多代码 ...
}
}
在测试时,不需要真正地发送邮件,因此可以使用Mock替身通过方法参数进行外部注入,从而更好地进行模拟测试。
$domain = new Domain_Push();
$domain->notice(new PHPMailer_Lite_Mock(), 'chanzonghuang@gmail.com');
对于PHPMailer_Lite_Mock类,可以这样简单实现。
class PHPMailer_Lite_Mock extends PHPMailer_Lite {
public function send($addresses, $title, $content, $isHtml = TRUE) {
echo "这里将模拟邮件发送,收件人为:$addresses, 标题为:$title \n";
}
}
执行上面的代码测试,最后可以看到输出:
这里将模拟邮件发送,收件人为:chanzonghuang@gmail.com, 标题为:注册激活
通过提取成员函数制造缝纫点
若使用的服务通常只有一个且固定时,对于存在多个方法依赖此服务的情况,使用方法参数注入的方式会显得有点过于重复、烦锁。这种情况下,可以先将创建资源服务的new操作提取到成员函数,再对此成员函数进行模拟。
例如,上面的推送业务类,除了需要发送注册激活邮件外,还要发送验证码邮件。并且未通过方法参数传递PHPMailer扩展类的实例的话,代码实现可能是:
class Domain_Push {
public function notice($address) {
// 前期准备 ...
$phpmailer = new PHPMailer_Lite();
$phpmailer->send($address, '注册激活', '欢迎注册,请点击激活!');
// 更多代码 ...
}
public function verifyCode($address) {
// 前期准备 ...
$phpmailer = new PHPMailer_Lite();
$phpmailer->send($address, '验证码', '验证码是:9527,10分钟内有效。');
// 更多代码 ...
}
}
在上面创建PHPMailer_Lite类实例的代码,使用了new操作,虽然直接,但产生了硬编码,最后导致难以测试,难以模拟。一个比较好的解决方案是,将对此类实例的创建,提取到成员函数,以便制造可替换的缝纫点。调整后的代码是:
class Domain_Push {
public function notice($address) {
// 前期准备 ...
$phpmailer = $this->createPhpmailer();
$phpmailer->send($address, '注册激活', '欢迎注册,请点击激活!');
// 更多代码 ...
}
public function verifyCode($address) {
// 前期准备 ...
$phpmailer = $this->createPhpmailer();
$phpmailer->send($address, '验证码', '验证码是:9527,10分钟内有效。');
// 更多代码 ...
}
protected function createPhpmailer() {
return new PHPMailer_Lite();
}
}
在上面代码中,我们把重复使用new创建PHPMailer_Lite类实例的代码,提取到成员函数Domain_Push::createPhpmailer(),并将原来的new操作换成了相应的成员函数调用。这样调整后,我们便可以通过子类继承的方式进行重写,从而进行替换。
class Domain_Push_Mock {
protected function createPhpmailer() {
return new PHPMailer_Lite_Mock();
}
}
通过DI资源容器进行外部注入
在PhalApi框架中,使用最多的是依赖注入,即我们经常用到的DI。使用DI的一个好处是,我们可以在入口文件,轻松对指定的资源服务进行替换。
例如,在测试启动文件里,我们就对日志服务进行了替换,不是真正写入日志到文件,而是直接在控制台进行输出。
// $ vim ./Shop/Tests/test_env.php
//日记纪录 - Explorer
DI()->logger = new PhalApi_Logger_Explorer(
PhalApi_Logger::LOG_LEVEL_DEBUG | PhalApi_Logger::LOG_LEVEL_INFO | PhalApi_Logger::LOG_LEVEL_ERROR);
所以,在进行单元测试时,日志内容会直接输出到控制台。
通过DI,我们还可以进行各种各样的模拟。又如,对于在单元测试时,不需要使用任何缓存的话,可以将缓存服务注册成空对象缓存类。即:
// $ vim ./Shop/Tests/test_env.php
// 禁用缓存
DI()->cache = new PhalApi_Cache_None();
这样,就可以在测试时,禁止全部缓存,使得缓存都失效。
对PHP官方函数进行模拟
PHP官方函数有:exit()、die()、header()、setcookie()等。而这些如exit()和die()会直接终止单元测试,而header()则会导致警告出现。这些都不利于单元测试。
为此,如何既然使用官方函数,又能很好进行单元测试呢?答案仍然是:入口!即对这些官方的底层函数进行包装。可以在公共目录中创建一个公共类来放置这些底层函数的封装。
// $ vim ./Shop/Common/Kernal.php
<?php
class Common_Kernal {
public static function eixt($status = NULL) {
if ($status === NULL) {
exit();
} else {
exit($status);
}
}
}
而在测试文件中,则可以对这些静态工具方法,进行类覆盖。即在test_env.php文件中编写一个同样的类,但其中的实现是模拟的实现。
// $ vim ./Shop/Tests/test_env.php
if (class_exists('Common_Kernal', FALSE)) {
class Common_Kernal {
public static function eixt($status = NULL) {
echo "exit here ...\n";
}
}
}
值得注意的是,class_exists()第二参数使用FALSE,避免触发真实类的自动加载。这样,在测试时就可以使用假的Common_Kernal类,而在生产环境中就可以使用真实的Common_Kernal类。
“造假”的技巧远不止这些,这里只是列出了一些常用的技巧。通过上面的讲解,可以总结出一个原则:测试代码与产品代码分离,且测试时不能改动任何产品代码。此外,产品代码应尽量提供一个服务入口,即缝纫点,以便使用桩、替身。
4.1.5 用一分钟,尽早发现问题
用代码证明代码
到目前为止,就评论接口服务而言,我们已经完成了产品代码的开发。对于一般接口服务,通常产品类有三个,分别是Api接口控制类,Domain领域业务类,和Model数据模型类。正如前面ADM模式中介绍的,Api类主要负责接口参数的验证、解析和获取,对Domain类进行调度决策并最后返回响应结果;Domain类主要负责特定领域业务规则、逻辑、具体流程的实现;Model类则是通过技术手段提供相应的数据或进行数据交互。这里的评论接口服务对应的三个类,分别是:Api_Comment、Domain_Comment,和Model_Comment,通过文件查找可以看到这三个类。
$ find ./Shop/ -name "Comment*"
./Shop/Api/Comment.php
./Shop/Domain/Comment.php
./Shop/Model/Comment.php
除了产品代码外,也创建并完善了评论接口服务与之平行对应的单元测试。这些单元测试保存在对应项目源代码目录的Tests子目录下,例如这里商城项目源代码目录是./Shop,那么其单元测试目录为./Shop/Tests。通过文件查看,我们也可以看到与之对应的三个测试类,分别是:Api_Comment_Test、Domain_Comment_Test,和Model_Comment_Test。
$ find ./Shop/Tests/ -name "*Comment*"
./Shop/Tests/Api/Api_Comment_Test.php
./Shop/Tests/Domain/Domain_Comment_Test.php
./Shop/Tests/Model/Model_Comment_Test.php
这样是一个很好的开始,有了单元测试这份宝贵的资本,我们多了一套可以保证质量,发现问题的好工具。作为开发人员,编写代码是我们的本职工作,或者说编写代码本来就是我们的爱好。既然如此,同样单元测试也是代码,为什么我们不也好好精心维护呢?如果仍然觉得编写单元测试会增加开发成本,需要大量的时间,那么可以换一个角度来看待单元测试,即把单元测试看作是用代码证明代码。如果能证明代码的正确性,就等于证明了作为开发工程师的专业技能,这样才算得上是一名合格的工程师。因为,我们的工作方式不再是感性的“我觉得我写的这段代码完全没问题”,而是有科学依据理性的“对于我写的代码,我已经证明过了,暂时再也找不到其他问题”。
执行phpunit单元测试的方式
在编写完成清晰、达意、短而美的单元测试后,下一步就是执行它们,以便给正在开发维护的系统实时反馈自我验证的测试结果。让它们跑起来吧!
执行单元测试的方式有很多种,读者在实际操作时可按需使用。为了让大家更清楚知道什么时候应该使用什么样的执行方式,下面按PHPUnit单元测试的维度,从小到多,依次罗列介绍常用的执行方式。
执行单个测试用例 单个测试用例,具体是指单元测试类里的某一个测试用例,可以使用phpunit命令的
--filter <pattern>参数指定测试用例的函数名称,注意这里匹配的是模式,而非字符串的完全匹配。例如,只执行Api_Comment_Test里的testGetAgain,可以:Tests$ phpunit --filter testGet ./Api/Api_Comment_Test.php在最后除了指定某个测试文件,还可以指定待匹配的目录。
执行指定分组测试用例 通过在测试用例的
@group注解后面加上分组名字,可以标注同一群组测试用例。当需要执行某一分组测试用例时,可以使用phpunit命令的--group ...参数,并在后面指定分组。在使用phalapi-buildtest命令生成测试骨架代码 时,默认也会生成@group注解。例如,执行获取评论那一组测试用例,可以:Tests$ phpunit --group testGet ./Api/Api_Comment_Test.php在最后除了指定某个测试文件,还可以指定待搜索的目录。
执行单个测试文件 这种最为常用的执行方式,不需要任何参数,直接在phpunit命令后面加上待执行的测试文件路径即可。在前面大部分也是这种执行方式,下面是其中一个示例。
Tests$ phpunit ./Api/Api_Comment_Test.php执行某个目录下全部的测试文件 测试文件按照惯例,应该与产品代码结构对齐。若是这样,最终项目的测试代码也会像上面那样,有Api测试目录、Domain测试目录、Model测试目录等。如果需要执行某个目录下的全部单元测试,可以在phpunit命令后面加上目录路径,而非文件路径。假设需要执行Api目录下的全部测试文件,可以:
Tests$ phpunit ./Api/执行测试套件 通过phpunit的xml配置文件,可以有效地组织测试套件,指定执行测试的目录或文件,以及排除哪些目录或文件。当需要执行这些测试套件时,需要用到phupnit命令的
-c|--configuration <file>参数,默认使用的配置文件为当前目录的phpunit.xml文件。例如,对于执行./Shop/Tests目录下的测试套件,下面三种方式都是等效的。$ Tests$ phpunit $ phpunit -c ./phpunit.xml $ Tests$ phpunit --configuration ./phpunit.xml
PHPUnit是一个很强大的工具,它还有很多很丰富的执行方式,和其他值得探索的功能。关于PHPUnit的讲解已经超出本书的范畴,感兴趣的同学可参考PHPUnit的官方使用说明,或简单地查看PHPUnit的帮助信息。
但在PHPUnit中有一个很棒的功能,这里不得不提一下,那就是代码覆盖率分析。使用phpunit命令参数--coverage-html <dir>,可以把代码覆盖率报告以HTML形式保存到指定的目录,随后在浏览器打开便可以看到代码覆盖率的具体情况。PhalApi一直追求着更高的代码质量,因此对于单元测试这块是非常重视的,从一开始核心框架代码的单元测试覆盖率就高达90%以上。
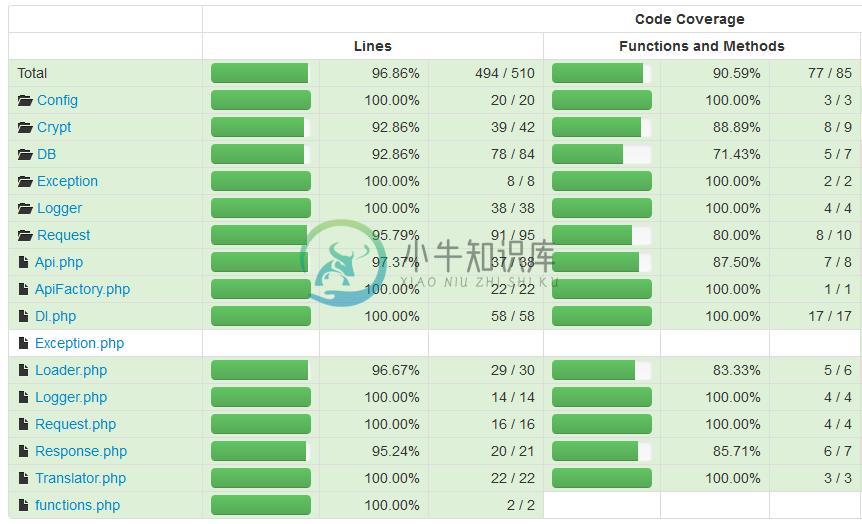
图4-4 早期PhalApi核心框架的覆盖率就高达90%以上
希望在开发项目的过程中,也能同样追求更高的代码测试覆盖率,建议保证核心业务代码的覆盖率高于80%,并从中获益。
一健测试
通过PHPUnit单元测试的XML配置文件,我们已经可以轻松管理项目的单元测试用例。这是很有帮助的,因为随着各业务线的不断丰富,为每条业务线准备一份专属的测试配置文件是很有必要的。试想象一下,评论服务体系有一套测试体系,用户服务体系也有一套测试体系,另外的商品服务也有与之对应的测试体系,对于开发不同模块的功能时,我们可以有针性地执行对应模块的单元测试,难道这不是一件很酷的事情吗? 极限编程推崇反馈与勇气,而划分明确的测试套件给了我们快速的反馈,这些反馈又增加了我们改动代码,进行重构的勇气。
PhalApi提供了一份默认的XML配置文件,并在其中添加了常见的测试目录,分别有公共测试目录、接口层测试目录、领域业务层测试目录和数据模型层测试目录。如果需要添加其他测试目录,可以自行添加。
<testsuites>
<testsuite name="Common">
<directory suffix="Test.php">./Common</directory>
</testsuite>
<testsuite name="Api">
<directory suffix="Test.php">./Api</directory>
</testsuite>
<testsuite name="Domain">
<directory suffix="Test.php">./Domain</directory>
</testsuite>
<testsuite name="Model">
<directory suffix="Test.php">./Model</directory>
</testsuite>
</testsuites>
在编写好单元测试代码,也准备好测试套件后,接下来要做的事情是,就是频繁地执行这些单元测试。频繁是指什么呢?具体来说,就是在每次代码编写完毕后执行一次,在完成阶段性重构工作后执行一次,在开始实现新的接口服务时执行一次,在提交本地代码到远程仓库前执行一次,在进入测试阶段前执行一次,在进行每日构建或者持续集成时执行一次,在正常或紧急发布时合并分支代码到主干后执行一次……执行的时机不一而足,在你想得到的时候都可以执行。
然而,有了各业务线单独专属的测试套件,但当需要执行多个测试套件时怎么办?假设评论服务测试配置文件为phpunit_comment.xml,用户服务测试配置文件为phpunit_user.xml,而商品服务测试配置文件为phpunit_goods.xml,如果每次都需要这样手动重复执行三次:
$ phpunit -c ./phpunit_comment.xml
$ phpunit -c ./phpunit_user.xml
$ phpunit -c ./phpunit_goods.xml
显然是不科学的。不仅影响了开发效率,还严重影响了开发人员的宝贵心情。要知道,开发人员要是心情不好,他“罢工”一小时要远比一台服务器由于故障而“罢工”24小时所造成的损失还要大。为此,我们需要保护好开发人员的心情。还记得在过往学习过程中,遇到需要手工处理重复枯燥的事情,其最好的解决方案是什么吗?没错!就是交给计算机来处理。
而批量处理作业,最适合使用脚本来完成。我们可以这样简单编写一个脚本,用于快速执行多个测试套件。
#!/bin/bash
phpunit -c ./phpunit_comment.xml
phpunit -c ./phpunit_user.xml
phpunit -c ./phpunit_goods.xml
保存后,添加执行权限后便可进行一键测试啦!何乐而不为?
如果你遵循测试驱动开发,但并没有编写任何测试代码,这算不上是测试驱动开发。如果编写了测试代码,但并没频繁地执行这些测试代码,我个人觉得,严格上也算不上是遵循测试驱动的开发。
那么,频繁执行这些测试会消耗很多时间吗?不会的,因为如果符合F.I.R.S.T.原则,即便是上百个测试用例,也可以在1分钟内执行完毕。那么,频繁执行这些测试的好处又是什么呢?在《代码大全》一书里,有一个原则很中肯地总结了这一点。
一般而言,这里的原则是:发现错误的时间要尽可能接近引入该错误的时间。 ——《代码大全 第2版》29页
通过频繁地执行单元测试,可以在编写代码后很快就发现所存在的问题。因为刚一编写完代码,就执行了单元测试。间隔是如此地短,以至于我们可以快速定位问题和解决。所以,这里可总结为:用一分钟,尽早发现问题。
4.1.6 小结
在这一节中,我们重点学习了如何在使用PhalApi开发接口服务时进行测试驱动开发最佳实践。先是学习了意图导向编程,编写单元测试的原则、模式与建议这些理论知识,然后到具体的一般步骤讲解,并结合了示例方便读者动手操作,参照实践。为了能提供就如何编写有效单元测试的技巧,不仅分享了三角验证的使用方法,还分享了一些用于模拟数据的“造假”技巧,这些都是很实用的技能,应当在中实践中运用并熟记于心。最后,单元测试编写好后,还有一个很重要的环节就是充分利用它们。作为一名专业资深的软件开发工程师,应该具备充分使用工具或最大化使用资源的能力。通过配置文件组织单元测试套件,并通过脚本对各业务线的测试体系进行管理,最终可以进行一键测试,尽早发现问题。
要知道,工具和使用方式,同等重要。当前这个时代,我们不缺乏知识,技术和信息,但缺乏的是使用这些资源的能力。对于单元测试也一样,可以说单元测试是软件开发过程中不可或缺的实践,其作用和价值真的不容忽视。但更为重要的是,我们使用单元测试的方式,或者说对待单元测试的态度和思想。
不同的思想,决定了不同的层次,最终产生的效果也会非常微妙。这里分为下策、中策和上策三个级别。首先需要注意的是,如果完全不采用单元测试,那你可以直接跳过本节,也就没有上、中、下策之分了。如果在产品代码开发完成后再补充“多余的”单元测试,认为单元测试是多此一举,只会增加开发人员的负担的话,那么这是下策。因为在事后再添加单元测试,确实意义不大,而且会让开发人员觉得有一点自己否定自己的感觉。明明自己都把事情做完了,而且做对了,为什么还要写什么单元测试呢?但是,如果采用的是测试驱动开发,在编写产品代码之前先编写测试代码,通过测试用例指导功能开发,这是非常有意义的。因为它会不断引导你用最简单的方式完成目标需求功能的开发,更容易产出灵活、优雅、高质量、恰如其分的代码。此乃中策。为什么说是中策呢?不是因为这种使用不够好,而是还有更好的。以至于,对于上策,为突显其重要性,我们不仅单独添加此小结部分,还单独使用新的段落为其讲解——
上策就是,用单元测试尽早发现问题,降低风险。构建完备,360度全方位的单元测试安全网,可以帮助我们在重构时保障原有的功能不受影响,是发布到生产环境前一道强有力的保护关卡,就像出入境一样,每次都要通过严格的海关测试,杜绝一切“非法”(对于代码,指的是不符合期望,限有缺陷)的行为。当你使用单元测试驱动开发已经有很长一段时间并且没有新的心得体会或者更高的收获时,意味着你应该把单元测试作为一个更高层面的思想指导,一如这里的发现问题,降低风险,才能有所突破,迎接新收获。
在我过去开发的项目中,就有过切身的体会。我和我的团队,从一开始什么单元测试都没有,到最后搭建了一键测试并频繁执行,至少在每次合并代码到主线后但在发布上线前,我们都会执行一次一键测试,基本上去打杯水回来的时间就能知道代码有没问题。就这样,时不时会发现一些问题,例如合并代码冲突后解决不当而导致代码丢失,很小的PHP语法问题,漏改的某处代码,前不久一位同事升级了某个API但另外一位同事却在新功能中仍然使用了废弃的旧API。代码虽小,影响甚大。很多严重问题,最终往往是由于很小的问题引起的。所幸的是,通过一键测试,我们很快就发现并修复了。这意味着,发现和修复这些问题,只是消耗了开发人员在准备发布阶段的这段时间,因此代价很低。谁也不能想象,如果这些问题未能及时,流通到线上,投放在市场,会产生怎样的影响,带怎样的代码。更不要到那时再来反思“一行代码到底值多少钱?”这样的问题。
4.2 设计模式的应用
关于设计模式,我想说的有很多,但想说的又很少。因为关于设计模式的书有很多,从最初提及永恒之道的《建筑永恒之道》,到经典的GOF《设计模式》,再到《企业应用架构模式》、《大话设计模式》、《设计模式分析》、《反模式》等,都是非常优秀的学习资料,而且都是非常值得一读的书籍。它们都对设计模式进行了很好的解释,更别说网上海量的学习资料,所以能说的很少。但我依然想分享一下我个人对设计模式的一些理解,希望可以在某个方面帮助到大家。
4.2.1 形式服从于功能
“不论是翱翔的雄鹰,或盛开的苹果花、... ... 形式总是服从于功能。这就是自然法则。”——摩天大楼的创造者之一 Louis Sullivan 1896
亚力山大曾经说过,掌握了一种大家所共有的语言模式后,在设计一些建筑时,是这些建筑本身通过语言模式告诉我,“它就是应该这样设计的!”而不是我个人刻意去这样设计以满足某些其他与建筑本身无关的目的,如个人的报酬、抑或外界的压力等。但如果不掌握这些语言模式,即便感知到这些建筑本质是怎样的,我们也不知如何表达出来,自然也就不知如何确切地构建出来。
设计模式可以说是一种更好组织代码的语言模式,即便不使用它,也能完成功能的开发。但使用它,效果更佳。在这里,我理解的是:形式服从于功能。最终目标是完成满足用户的特定功能,其次是使用设计更好组织代码外在形式,以便更好表达概念的完整性。从业务的视角着手,借助设计模式,可以提高开发效率,快速交付复杂多变的业务功能。更进一步,通过设计模式,可以组织起易于理解、体现概念完整性、更具生气的代码,并逐步演进得到符合领域业务本质的浮现式设计。
下面让我们一起来看下,设计模式是如何应用在各种上下文场景中的。
4.2.2 在项目开发中的应用
这一节,我们将会学习设计模式在项目开发中的应用,讲述在ADM分层模式中可能会使用到的设计模式。
Api层作为最高层的访问入口,负责接收参数和返回结果。由于我们推崇的更更明确职责的划分,而不是把全部的代码都塞在Api层,所以这一层的代码应该是精炼的,简单的,所以一般情况下也就不需要用到设计模式。
应对复杂领域业务的模板方法模式
至于Domain层,情况则完全不同,这里负责着最复杂的领域业务,而设计模式正是用来解决重复问题、简化设计有效的方案。某些业务规则,虽然很复杂,但一般来说会有特定的处理流程,也就是说核心关键的流程是类似的,只是根据不同的人群,或者不同的场景,不同的时期阶段会有相应的变化。这时适宜使用模板方法模式,将公共的流程进行固化,保证核心业务不缺失、不遗漏、不重复、不混乱,同时又能为子类提供进行独具特色处理的机会。概括来说,正规而不失灵活。
这里稍微举两个场景例子。例如对于进行支付结账的业务流程,通常步骤是:
- 1、获取待支付的金额
- 2、判断支付方式
- 3、优惠处理
- 4、进行支付
- 5、返回支付状态及结果
显然,这是一个相对固化的过程,对于任何的支付来说一般都要流经这些环节。其中某些环节有可能是相同的,例如获取待支付的金额,但其中某些环节却又是不同的,例如判断支付方式、进行支付,就会根据不同的支付方式需要进行不同的支付高度,如果使用的是支付宝,那么需要调用支付宝平台提供的接口,如果是微信支付,则需要走微信支付流程。每个环节没有存在绝对的相同或者绝对的不同,支付方式如果只限制为一种,那么就不存在其他支付方式,但出于可扩展性,还是需要提前考虑的。对于优惠处理,有可能会因为时期不同,活动的类型不同,进行不同的促销优惠活动。当找出了这些变化的热区后,再通过模板方法模式,就能很好地把变化的代码逻辑与固化的核心规则隔离开来,使之独立变化,互不影响。这样不仅能让代码更加清晰,也便于快速迭代,更重要是减少出错的概率。
又如常见的消息推送业务流程,假设步骤为:
- 1、判断用户是否满足推送的条件
- 2、获取推送的内容
- 3、通过特定渠道的进行推送
- 4、纪录推送情况
这里假设第1步,第2步和第4步是相同的,而第3步的推送实现,根据待推送消息的重要级别,采用不同的推送方式。如对于实时性要求高或非常重要的推送采用短信通知,谁都希望当他的银行卡有钱转入或转出时能第一时间知道;对于一般性的日常提醒或者需要依赖APP进行交互的则采用App通知提醒功能;而对于修改密码或者忘记密码这样的场景,则通常使用邮件进行发送推送。这又是一个使用模板方法的好地方。不同的推送方式,甚至细化到每种业务推送类型都可以进行定制,同时又保留公共基础流程的复用。
此消息推送的抽象基类,根据上面定义的步骤,可能的实现代码是:
/**
* 消息推送 - 模板方法
*/
abstract class Domain_Notification {
public function push($context) {
if (!$this->isNeedToPush($context)) {
return FALSE;
}
$data = $this->getPushData($context);
$this->deliverMessage($context, $data);
$this->takeRecord($context);
return TRUE;
}
protected function isNeedToPush($context) { }
protected function getPushData($context) { }
abstract protected function deliverMessage($context, $data);
protected function takeRecord($context) { }
}
其中$context参数表示上下文信息,这里通过参数对象来封装了全部所需要的参数,避免过长的参数列表。除了唯一的抽象方法Domain_Notification::deliverMessage($context, $data)外,其他三个都是已经实现的方法,只是这里省略了实现的细节。当定义好高层的概念,并且约定好的接口规范后,下一步就是具体的实现了。
例如,对于需要发送短信进行的通知,可以新增一个子类并完成重要通知的发放。
class Domain_Notification_Emergency extends Domain_Notification {
protected function deliverMessage($context, $data) {
// TODO: 根据上下文$context,将通知数据$data通过短信发送给用户
}
}
而对于需要使用邮箱进行发送的通知,可以再增加一个子类,同样实现具体的推送动作。
class Domain_Notification_Normal extends Domain_Notification {
protected function deliverMessage($context, $data) {
// TODO: 根据上下文$context,将通知数据$data通过邮件发送给用户
}
}
在这里,实现细节暂时不用关注。重点需要学习的是,当遇到复杂的领域业务时,如何利用模板方法模式进行设计,解决所面临的问题,以及更好地引导开发人员一致规范地实现需求,同时满足后续迭代扩展的需求。就上面的消息推送示例而言,如果后面需要增加一种新的推送渠道,也是可以知道在哪个位置如何具体实现的,即是可预见性的实现,而非随意的主观而为。这也是符合开放-封闭原则的。
下面给出最终可能的调用方式。
// 上下文场景信息
$context = array(....);
// 作为紧急消息推送
$emergency = new Domain_Notification_Emergency();
$emergency->push($context);
// 作为普通消息推送
$normal = new Domain_Notification_Normal();
$normal->push($context);
// 作为其他消息推送?
// $other-> = new Domain_Notification_XXX();
// $other->push($context);
轻松切换数据源的策略模式
Model层用于为领域业务层提供原始的数据,这些数据需要通过技术手段从不同的媒介进行提取或交互,有可能来自数据库,或者高效缓存,甚至第三方接口平台等。当需要根据不同的策略切换到从不同的媒介、或者使用不同的方式获取数据时,可以考虑使用策略模式。
曾经,有一位大三的学生,去到一家游戏公司实习,并且很快他的老板就在某个早上找到了他并向他布置了第一个开发任务。
“年轻人,非常欢迎你到我们公司实习!“
“谢谢老板~”
“在这边上班都习惯吧?”
“虽然和学校有点不一样,但这里的同事和前辈都很nice,氛围挺好的。”
“哈哈,那就好。现在有个任务分配给你。”
“好的,老板请讲!”
“恩,是这样的,我们需要开发一个接口服务,为市场人员提供重要的业务数据,但需要……”
经过一番沟通,原来是需要从第三方远程接口获取数据再提供给市场人员。很快,这位实习生就实现了第一版的代码开发,主要使用的是通过SOAP简单对象访问协议访问远程接口。最初的代码的调用类似这样:
$connector = new Model_Connector_Kowa();
$data = $connector->getSomeData();
这段代码工作得很不错,直到有一天老板又过来了……
“嗨,年轻人!上次的代码写得很棒,市场部门在你提供的接口服务下圆满完成了销售额。”
“那真的是太好了!”
“但好像我看到现在用的是SOAP,建议换成PHPRPC协议,一来可以提升性能,二来更有保障。”
“没问题,我这就去了解下PHPRPC并进行优化调整……”
遇到一位懂技术,特别是技术出身的老板,往往会有一番特别的工作体验。经过一番捣鼓后,这位实习生再次完成了改用PHPRPC访问远程接口这一功能。但他想到,如果后期老板需要改用HTTP协议访问的话可以怎样更好地应对?而且,当时这位实习生对切换到PHPRPC的访问方式持保留意见,他同时想到如果PHPRPC上线后效果不理想需要切换回原来的SOAP协议时又该怎么办?
这时,他想到了策略模式。没错,策略模式正是封装了一组可以相互替换的算法,便于在不同的使用场景进行切换。又经过一番重构后,最终代码的调用类似这样:
// 原来SOAP访问方式
// $connector = new Model_Connector_SOAP_Kowa();
// 新的PHPRPC访问方式
$connector = new Model_Connector_PHPRPC_Kowa();
// 未来可能的HTTP访问方式
// $connector = new Model_Connector_HTTP_Kowa();
$data = $connector->getSomeData();
上面有三种访问方式,被注释的创建实例代码表示当前未启用的方式。而其中的Kowa名称没有任何特殊含义,只是一个走心的临时名称。
再一次,对于特定的业务场景,采用合适的设计模式,能有效解决问题。当然,上面的案例基于真实故事改编,而这位实习生,正是笔者本人。
有适配者模式,迁移升级不用愁
随着项目的不断迭代,以及市场业务的日益庞大,各系统会出现拆分、升级、迁移等情况。当接口服务所依赖的底层实现发生改变时,与之对应的调用也需要进行相应的调整。
一个典型的项目案例是,最初全部数据存在数据库中,Model层直接通过操作数据库获取数据。后来提供了统一数据层访问接口,即需要通过用PHP实现的远程接口进行数据访问与操作。再后来,切换到用JAVA实现的微服务。不管底层用的是何种技术实现,对于返回的数据应该是一样的。既然是不同的技术,就会需要提供不同的参数。基于此,可以先实现新的获取或交互方式,再使用适配者模式包装成与原来一致的接口,以保证向前向后兼容性。即使当新的方式不可用时,仍然可以快速切换回到原来的访问方式,保证接口服务的可用性。
以从远程接口获取广告数据为例,假设原来的获取方式是:
// 从远程接口,获取类型为$type的前$num条广告
$model = new Model_Connector_Ad();
$data = $model->getList($type, $num);
采用适配者模式后,新的获取方式是:
// $model = new Model_Connector_Ad();
$model = new Model_Connector_Ad_Adapter();
$data = $model->getList($type, $num);
关于在项目中设计模式的应用,暂时介绍到这里,下面我们继续来看下在扩展类库中的应用。
4.2.3 在扩展类库中的应用
在前面介绍扩展类库的使用时,已经讲解了部分扩展类库的核心设计,以及使用的设计模式,方便大家更深入理解扩展类库背后的微架构。这里,再有针对性地说明一下扩展类库中常见的设计模式,为编写开发自己的新扩展提供帮助和参考。
用于封装第三方类库的外观模式
PHP是一门伟大的语言,而伟大之处在于她的开源社区,在于随处可用的开源框架、类库和代码。很多功能,尤其是技术类的功能,基础设施的搭建,通常都能找到可重用的开源项目,例如配置管理,文件处理,生成随机数,数据加密,日期和时间等。这些开源项目都是非常优秀的,但毕竟他们考虑的场景比较多,为了提供更强大、更全面的功能,自然其使用的复杂度就高,并且会存在一些我们项目中不需要使用到的功能接口。为了解决这些问题,即简化对这些第三方类库的使用,同时方便集成到PhalApi中,我们可以使用外观模式将这些第三方类库封装到扩展类库。
目前在已经的扩展类库中,就可以找到很多这样的场景,有:基于PHPMailer的邮件发送扩展,基于七牛SDK的Qiniu扩展,基于PHPExcel的邮件处理扩展,基于Smarty模板的扩展等等。当你也需要将第三方的类库集成进来时,也可以同样考虑此外观模式。
使用过PHPMailer的开发人员,可能还会记得当需要发一封邮件时,需要调用PHPMailer进行各种设置,包括有设置邮箱服务器,设置邮件的标题、内容、收件人等,并且这些不同的操作需要调用不同的接口进行或者通过不同的类属性成员来设置。但如果通过外观模式封装好的扩展类库,按要求配置注册好后,发送邮件只需要一行代码。
DI()->mailerLite->send($addresses, $title, $content, $isHtml);
通过代理模式提供新的访问入口
PhalApi接口框架默认通过HTTP/HTTPS协议访问接口服务,通过使用扩展类库,可以提供其他形式的访问入口,例如RESTful风格的API、使用SOAP协议或者使用PHPRPC协议、CLI命令行项目。虽然访问的方式不同,但返回的结果结构还是一样的,并且其内部的接口服务的处理和响应是不变的,因此需要保留原来接口服务可复用的部分,而只扩展定制访问的方式,这时则适合采用代理模式。
具体的做法是,先把原来的PhalApi实例作为代理类的内部变量成员,再重新实现response()方法,并在里面进行相应的预处理,最终调用原来的response()方法并返回结果。
回顾一下SOAP扩展的实现代码的核心片段。
<?php
class SOAP_PhalApi {
protected $phalapi;
public function __construct($phalapi = NULL) {
if ($phalapi === NULL) {
$phalapi = new PhalApi();
}
$this->phalapi = $phalapi;
}
public function response($params = NULL) {
... ...
$rs = $this->phalapi->response();
return $rs->getResult();
}
}
在上面SOAP_PhalApi的构造函数中,就创建了原来PhalApi类的实例,并保存到类变量成员SOAP_PhalApi::$phalapi中。随后重新实现了response()方法,进行预处理后,通过PhalApi::getResult()返回原来的结果。
PHPRPC扩展的实现方式与此类似,这里不再赘述。感兴趣的读者可以查阅一下对应的源代码。
当需要类似这样提供新的访问入口时,可以参考上面的实现方式,采用代理模式。这是一个有活力的设计,得益于设计模式的正确应用,通过结合不同的护展类库,我们可以在不改动已有接口服务代码基础上迅速超越HTTP/HTTPS访问方式。
但不管是何种访问方式,使用何种协议,最终我们都会得到一致的响应处理。下面一起来快速重温下不同访问方式下入口文件的实现细节,以印证这点。
先来稍微看下默认入口文件。
... ...
$api = new PhalApi();
$rs = $api->response();
$rs->output();
通过phprpc协议访问接口服务的入口文件。
... ...
$server = new PHPRPC_Lite();
$server->response();
通过SOAP协议访问接口服务的入口文件。
... ...
$server = new SOAP_Lite();
$server->response();
CLI命令行项目提供的入口文件。
... ...
$cli = new CLI_Lite();
$cli->response();
上面入口文件中,前面省略的代码都是和默认的入口文件中的代码是相同的。多么一致的实现和设计啊!
4.2.4 在PhalApi框架中的应用
了解PhalApi框架中所用的的设计模式,对于项目进行定制、二次开发,有很大的帮助。借鉴其中的思想,对于如何设计接口开发框架也有一定的启发。
只用一次的单例模式
知道何时应该使用设计模式很重要,知道何不应该使用也同样重要。在项目开发过程中, 不加考虑就使用设计模式(为了使用设计模式而使用设计模式)的话,最终效果往往会适得其反。其中,较为明显的是对单例模式的滥用。
单例模式是一个使用起来很容易的设计模式,正因为其易用性,开发人员通常会不加思索就写出单例模式的实现代码,而不管是否真的需要。当很多类在实现时都这样“盲目”地实例单例模式时,项目就会到处充斥着重复的代码。编写这些代码的开发人员可能会觉得,使用模式总是会有好处的。但别忘了有一个前提:正确地使用。实际上,不恰当地使用单例模式所带来的影响有:
- 缺少扩展性,代码因缺乏多态而散发着僵硬性
- 不利于进行有效的单元测试
- 暗示着伪重复代码的到来
在我曾经就职的公司,最初内部架构组提供的开发框架的代码里就有随处可见的单例模式。稍微对源代码搜索一下单例模式获取单例的方法名称“getInstance”,可以看到一堆实现的代码,缓存有单例,配置有单例,日志有单例,请求有单例,响应有单例……基本上你能想得到的,都有单例,累计有20多个单例类。这是一个活生生误用、滥用单例模式的真实例子。
我记得,在某本书中较为全面地讲明了何时应该采用单例模式。印象中,以下是适宜采用的场景。
- 为全局提供统一的访问入口
- 为了提高系统性能,避免重复创建相同的实例
- 若实例存在两个或两个以上,业务规则不能保持一致性或与现实情况不符(如有一个班级有两个班主任)
在开发框架中,为了较好地解决和减少后期重复的开发,可以引入专门的服务容器对这些资源进行统一的维护和管理,一如使用依赖注入(Dependency Injection)。PhalApi框架正是这么做的。
如果你也对PhalApi框架的源代码寻找单例模式的实现代码,会发现只有一个地方,那就是PhalApi_DI依赖注入类。其实现方法与普通的单例模式没有太大不同,唯一区别是获取单例方法是PhalApi_DI::one(),而不是PhalApi_DI::getInstance(),并且构造函数是public而不是protected。但又与普通的单例模式有着重大的区别,因为只需要在DI实现一次单例模式,其他需要使用到单例的类就可以不用重复编写单例模式的代码直接通过DI内部机制获得同样的能力。这是因为在DI中注册的每个资源服务,本质上就是单例的。
以下是相关的代码片段。
class PhalApi_DI implements ArrayAccess {
/**
* @var PhalApi_DI $instance 单例
*/
protected static $instance = NULL;
public function __construct() {
}
public static function one() {
if (static::$instance == NULL) {
static::$instance = new PhalApi_DI();
static::$instance->onConstruct();
}
return static::$instance;
}
这里,细心的读者会发现,在使用PhalApi框架进行编码时,最常用到的DI()快速函数实际上就是对此获取单例方法PhalApi_DI::one()的调用。
// 通过快速函数获取DI单例
$di = DI();
// 等效于
$di = PhalApi_DI::one();
// 相当于经典的(但框架未实现)
// $di = PhalApi_DI::getInstance();
// 还可以手动New创建新的DI实例
$anotherDI = new PhalApi_DI();
在上面实现单元例的代码中,显然会使用到static静态方法,但静态方法会阻碍单元测试和抵制代码灵活性,所以PhalApi很少使用静态方法。除了上面单例模式用到static和工具类外,还有一个地方就是——
致力于创建与使用分离的工厂方法模式
上面谈到,创建接口类实例的工厂方法PhalApi_ApiFactory::generateService($isInitialize = TRUE)是PhalApi中使用了静态类方法为数不多的类之一。但这不是重点,重点在于工厂方法模式给我们带来了什么。
Api层的接口类是外界访问的入口,也是返回结果给客户端的地方。它负责接口服务内部的调试与实现,扮演着非常重要的角色。虽然接口类的使用很简单,基本上都是由框架进行调度的,开发人员甚至不需要直接使用,只需要完成接口类的功能开发即可。但是接口类的实例的创建却不是一件容易的事。根据接口参数提供的service参数,到最后创建对应的接口类实例,这中间有一条很长的路要走。
创建接口类实例的艰辛过程主要有:
- 1、是否缺少接口类名或缺少接口类方法名?若缺少,抛出异常
- 2、接口类是否存在?若不存在,抛出异常
- 3、接口类是否为PhalApi_Api的子类?若不是,抛出异常
- 4、接口类的方法是否可调用?若不可调用,抛出异常
- 5、按需要进行初始化,最后返回创建好的实例
上面创建过程对应框架的代码片段如下所示,请注意为突出对应关系代码已作精简。
class PhalApi_ApiFactory {
static function generateService($isInitialize = TRUE) {
... ...
if (empty($api) || empty($action)) {
throw new PhalApi_Exception_BadRequest();
}
... ...
if (!class_exists($apiClass)) {
throw new PhalApi_Exception_BadRequest();
}
... ...
if (!is_subclass_of($api, 'PhalApi_Api')) {
throw new PhalApi_Exception_InternalServerError();
}
if (!method_exists($api, $action) || !is_callable(array($api, $action))) {
throw new PhalApi_Exception_BadRequest( );
}
if ($isInitialize) {
$api->init();
}
return $api;
}
}
最后,通过封装好的工厂方法,客户端只消一行代码就可以创建一个功能完备的接口类实例了。
$api = PhalApi_ApiFactory::generateService();
这不得不说是人类的一大进步啊! 这样以后,在进行单元测试,生成在线接口文档,以及在护展类库中进行定制化时,都能通过此一致的方式地获取到对应的接口类实例。 规则出现一次且仅此一次。
可以看出,创建接口类的过程步骤繁琐,并且非常严格。这是非常适合使用工厂方法模式的场景。推而广之,经总结,我们发现以下这些场景适合使用工厂方法创建自定义类实例。
待创建的实例由动态配置或动态参数决定 例如这里的根据service参数创建接口类实例;也可以是根据配置文件中的配置映射表进行动态创建,有进行活动促销时经常会有这种情况,即根据某段时间内配置的活动名称创建对应的活动实例;还可以是根据运营人员在管理后台编辑或下拉选择的类型,进行动态实例化。总而言之,不管动态的标记值来源于哪里,对于此类根据动态值创建实例的场景,应该考虑应用工厂方法模式来封装。
存在基本版本和升级版本的区分情况,或不同的执行路径 在很多系统和网站中,经常会用到A/B测试,便于对新功能进行灰度分流测试,从而和已有的功能进行对比,若效果良好再全量开放。这样的话,可能不同的人群会看到不同的页面功能,也就是说同一个场景,可能需要创建基本版本,也有可能需要创建升级版本。在传统的实现中,一个直观(但并不是最好的)方案是在要差异功能点添加很多if判断。
if (abTest() == 'A') {
// 功能点A1
}
// 功能点C
if (abTest() == 'B') {
// 功能点B1
}
if (abTest() == 'A') {
// 功能点A2
}
// 功能点D
if (abTest() == 'B') {
// 功能点B2
}
上面的很有趣的代码,是模拟了A/B测试的页面的实现示例代码。不难发现,功能点A1、A2只适用A人群,功能点B1、B2只适用于B人群,而功能点C和D适合于任何人群。这就是传统的实现方式,不好的原因是因为耦合性太强,对A人群的功能修改很可能会影响到B人群的功能,因为逻辑上明显独立的功能却没有在代码实现上很好的进行隔离。更好的方案是使用工厂方法封装根据不同人群创建对应的功能实现类,最后再统一进行响应处理。即可实现相互独立,各自变化。
根据复杂的逻辑创建实例 在某些场景中,最终呈现的功能可能是叠加性的。对应代码实现的细节是,我们有一个带有基本构造函数的类,它可以甚至在无参数的情况下快速实例化,然后再根据不同的判断条件丰富初始化状态。举个例子,我们在游戏中有个普通的战士,当发现他有衣服时就给他穿上,当发现他有装备时就给他佩戴上,当发现他有很高的荣誉和称号时就给他加上一些特权……到最后得到的将是一个炫酷无比的超级战士。
根据完整性的业务规则创建实例 熟悉数据库事务概念的开发人员,对于这一种场景应该会很好理解。和事务一样,创建一个实例时,它需要同时满足多个条件,并同时完成全部的初始化操作,要么这些条件和操作全部都通过完成,若有任意一个失败都会导致最终实例创建失败。如果不用工厂方法把这些强内聚的创建过程封装起来,而是让开发人员手动去创建时,就很难保证创建时的初始化顺序以及业务规则 的概念完整性。
除此之外,工厂方法还可以进行更多的控制。包括但不限于:
- 进行数量的控制
- 进行访问权限的控制
- 进行日记纪录和统计
- 处理异常情况
与此同时,在实现工厂方法时,在处理失败时的返回值上,有着微妙的区别。通常,当未能成功创建实例返回时,可以使用下面这些处理方式。
- 抛出异常,通知上层并由上层决定如何处理
- 返回NULL,采用静默式提示错误,容易导致空指针引发的崩溃
- 返回一个默认实例,保障正常流程基本的可用性,但可能并不是最终业务想要的效果
- 返回空对象,即返回实际无作为的假对象
具体应用使用何种策略,具体可视业务场景而定。这里再回顾重温一下,曾经教科书里中肯的建议:
要么构造和管理其他对象,要么使用对象,不应兼而有之。
相信有了实际项目的开发经验后,对于这句话我们会更有体会。
多级缓存背后的组合模式
在前面学习缓存时,曾经介绍了多级缓存,其中简单地提到多级缓存是使用组合模式而实现的。让我们再来重温一下当时设计的精静态结构。
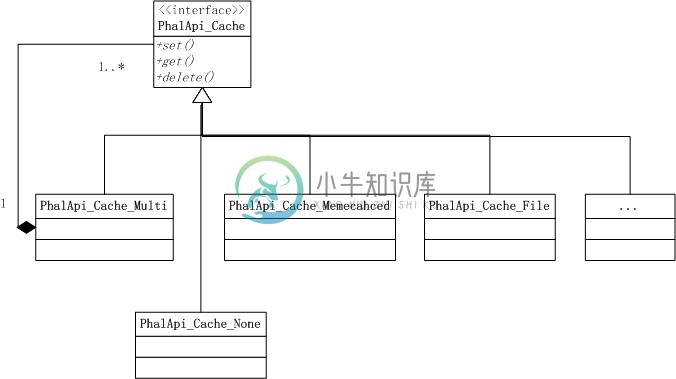
图4-5 多级缓存背后的组合模式
在上图的最左边,是PhalApi_Cache_Multi多级缓存类,它主要作用是添加实现了PhalApi_Cache接口的对象,并把对于缓存的相关操作全部作用在这些已添加的对象之上,从而实现多级缓存的功能。这里并没有抛开已有的设计,重新单独设计一个多级缓存类,因为如果这样做的话,不可避免重复的代码,除此之外对于开发人员还需要学习另一套缓存的使用方式,而仅仅是单级缓存和多级缓存这一区别。恰恰相反,设计的实现多级缓存这一过程,是以逐步的、不否定已有的方式创建进一步的功能。每一个步骤,每一次变化与以往既有的结构能保持和谐。这才是使用了组合模式更深层次的初衷。
就上面的静态类结构图而言,并抛开图中各子类在PhalApi框架中的实现细节,当需要组合一个多级缓存的方案时,我们不难推断出使用的方式正是按我们所想的那般简单。
$multiCache = new PhalApi_Cache_Multi();
// Memcached + 文件缓存
$memcached = new PhalApi_Cache_Memcached();
$multiCache->add($memcached);
$file = new PhalApi_Cache_File();
$multiCache->add($file);
// 使用和原来单级缓存一样
$multiCache->set('name', 'dogstar', 600);
var_dump($multiCache->get('name'));
“优先使用对象组合而浊类继承”,这一原则在这里又一次得到了很好的体现。
用代理模式巧妙实现数据库分表
PhalApi对数据库的操作是基于NotORM实现的,NotORM是一个优秀的开源类库,但它只专注于数据库的处理上。对于数据库分表,它没有任何支持。但使用PhalApi进行接口服务的开发,最初一个主要目的是能开发应对海量数据的接口系统。那么,如何优雅地解决亟待实现的数据库分表与NotORM未提供分表支持这一脱节的现象呢?
经过一番思索,我们最终采用了代理模式。把数据库分表的处理控制在这一代理类上,然后把数据库的操作继续分发给专注于数据库的NotORM进行处理。具体的做法是,在获取表实例时进行拦截,根据待获取的表实例,结合数据库的表路由配置,使用对应的配置进行初始化,最后才返回表实例。文字表达上不好直观地理解,让我们来看下代码吧。
例如,对于获取数据库表user的表实例,NotORM原始的实现方式是:
include "NotORM.php";
$pdo = new PDO("mysql:dbname=phalapi");
$db = new NotORM($pdo);
$user = $db->user;
上面四行代码,其作用分别是引入NotORM入口文件,创建PDO实例,初始化NotORM,获取表实例。对于非正式的项目开发,这样使用是没问题的,但对于正式的商业项目开发的话,这样是有问题的。
问题在于,每次都需要开发人员重复这些步骤。更好的方式将这些创建过程封装起来,并通过修改配置文件实现数据库的连接。统一封装并实现的数据库分表功能后,最终获取user表实例的代码将会是简化成只有一行代码。
$user = DI()->notorm->user;
不要小看这一行代码,这行代码背后可有着大文章。它实现的功能包括但不限于:仅当需要用到时才创建NotORM表实例,并且这些实例最多有且只有一个实例,根据配置连接不同的数据库、设置表前缀和主键,数据库分表,异常处理。
对于需要进行获取分表的实例,在配置好相应的表路由规则后,可能的调用代码是在表后面追加作为分表标志的数值。
// user的10张分表对应的表实例
$user0 = DI()->notorm->user_0;
$user1 = DI()->notorm->user_1;
... ...
$user9 = DI()->notorm->user_9;
4.2.5 优先考虑最终使用的方式
在应用设计模式之前,优先考虑最终代码的使用方式,将会大有裨益和启发性。使用的方式越简单,它就越受欢迎,出现错误的可能性就越小。根据CVA和三层视角,先分析对象必须完成哪些操作,再确定如何调用它们。明确了概念,也约定好规约后,再结合测试驱动开发,无疑将会是一次富有创造性的编码过程。
当初,在利用工厂方法模式实现对接口类实例创建时,其编码过程就是一次令人难忘的经历。一开始,我就在高层定义创建实例的接口签名为PhalApi_ApiFactory::generateService(),这就界定了最终使用的方式。以下就是测试正常创建默认接口服务实例的用例,那时当然还没有任何产品代码。
public function testGenerateNormalClientService()
{
$data['service'] = 'Default.Index';
DI()->request = new PhalApi_Request($data);
$rs = PhalApi_ApiFactory::generateService();
$this->assertNotNull($rs);
$this->assertInstanceOf('PhalApi_Api', $rs);
$this->assertInstanceOf('Api_Default', $rs);
}
我端详着这段代码,看它是否是以最简单的方式就能完成对实例的创建,是否会存在令项目开发人员迷惑、容易误解甚至误用的地方。显然,它是最简单的,简单到甚至不需要任何参数(实际上是依赖于传递的service参数)。既然如此简单明了,自然被错误使用的可能性就很低,除非不小心拼写了方法名。
这时为了让测试通过,实现的代码很简单。
static function generateService() {
$api = DI()->request->getServiceApi();
$apiClass = 'Api_' . ucfirst($api);
$api = new $apiClass();
return $api;
}
当然,故事并没有就此结束。如果世界是这么简单的话,那么到些结束也是可以的。但编写的代码不会运行在童话世界里,因此我们还需要处理一些非法的场景。如果所创建的接口类不存在时怎么办呢?我第一时间想到了这一点,继而补充了相应的单元测试用例。
/**
* @expectedException PhalApi_Exception_BadRequest
*/
public function testGenerateIllegalApiService()
{
$data['service'] = 'NoThisService.Index';
DI()->request = new PhalApi_Request($data);
$rs = PhalApi_ApiFactory::generateService();
}
跑一下单元测试,失败了。很好,要的就是失败。知道要做什么,剩下的就好办了,只消用上高中自学的编程能力都能让这个测试通过。增加代码在创建实例前先判断一下类是否存在。
$apiClass = 'Api_' . ucfirst($api);
if (!class_exists($apiClass)) {
throw new PhalApi_Exception_BadRequest('类不存在');
}
$api = new $apiClass();
类似地,我还逐渐考虑了诸如缺少service接口参数、参数非法、接口类方法不可调用等这些异常场景。在先补充失败的测试用例,再完善代码,慢慢地,浮现出了一个设计良好、功能强大而稳定的工厂方法。再到后来,随着框架的不断升级,我又补充根需要进行初始化,扩展的接口签名验证,以及接口服务白名单配置等功能。这样的演进过程更符合敏捷迭代的节奏。这是一次富有创造性的过程,通过仔细观察最终使用的方式,我们不断在原有的基础上创新、优化,最终产生了项目开发人员喜欢的功能接口。
让我们来看下最终真正的使用场景吧。对于一直在使用的接口服务响应,其内部实现代码片段是:
class PhalApi {
public function response() {
... ...
try {
// 接口调度与响应
$api = PhalApi_ApiFactory::generateService();
$action = DI()->request->getServiceAction();
$data = call_user_func(array($api, $action));
... ...
} catch (PhalApi_Exception $ex) {
... ...
}
}
在辅助类测试调度类中的模拟请求接口服务的方法实现中,同样用到了创建接口类的方法。
class PhalApi_Helper_TestRunner {
public static function go($url, $params = array()) {
... ...
$apiObj = PhalApi_ApiFactory::generateService(true);
$action = DI()->request->getServiceAction();
... ...;
}
}
在生成在线接口详情文档时,也可以看到调用的身影。
class PhalApi_Helper_ApiDesc {
public function render() {
... ...
try {
$api = PhalApi_ApiFactory::generateService(false);
$rules = $api->getApiRules();
} catch (PhalApi_Exception $ex){
... ...
}
这些不同的使用场景,最终都是按我们一致简单的方式进行调用,并且能在各种恶劣的情况下正常工作。这得益于我们一开始考虑的使用方式,包括了正常的使用方式和异常的使用方式。做正确的事,比把事情做正确更重要。
4.2.6 小结
市面上关于设计模式的资料已经有很多,所以这节不打算再重复进行理论上的讲解,而是重点讲述了设计模式的具体应用。这里假设你已经熟悉各个设计模式的相关知识,包括模式名称、问题、解决方案、效果等。如果尚未了解,请参考GOF的经典著作及其他学习资料。
即便不采用设计模式,也是可以开发实现业务功能的。但若细细观察这些项目,往往更容易找到主观性很强的代码, 以至于后来阅读代码的人不明白为什么要这样命名,为什么要放置在这里,也不明确类之间的关系,甚至包括代码的作者。可想而知,这类项目的维护过程势必是步履维艰的,因为深奥得像天书,复杂得像迷团。又或许,虽然已经在项目中使用了设计模式却并不知道为什么需要这样做,更有甚者,根本不知道已经在使用了。
设计模式对于有序地组合代码,起着不可忽视的作用。我看过很多表面上设计得很漂亮的网站,但实际上其内部实现的代码却是不堪入目。为什么设计人员都可以把UI设计得如此有序不紊,而我们作为开发人员却未能有效地组织代码?难道是因为可视化的UI更容易编排,而处理严谨逻辑的代码更枯燥乏味?还是因为藏在背后的代码没有最终用户能直接看到就放任之?对于一件事情,不仅要完成它,还要把它做好。作为开发工程师,我们可能会抱怨需求变化太快,代码远跟不上市场变化的脚步,想说“拥抱变化”不容易。但有没想过为什么我们的代码跟不上变化的节奏?或者,答案就隐藏在设计模式中。除此之外,我们也应追求能存活更久的代码。编写适用于一个月的代码很容易,编写能生存一年的代码稍微难一点,编写五年、十年后仍然能很好工作、支撑各种变化的代码,则需要我们合理的设计与精湛的实现。其技巧和秘诀也隐藏在设计模式中。
学习设计模式在项目开发中的应用,可以帮助我们在遇到类似的业务场景和问题时采用对应的设计模式。Api接口层通常不需要用到设计模式;而Domain领域层对于复杂领域的业务,对于有着公共固化的流程又有独具特色的定制处理的场景,可以使用模板方法模式;在Model数据层,对于存在多种不同技术实现的数据提取与交互,使用策略模式可以实现轻松切换,而对于在纵向需要升级迁移的接口调用,可以考虑使用适配者模式,以便在线上出现问题时可以快速切换到原来的访问方式。
学习设计模式在扩展类库的应用,可以帮助我们更好的理解扩展类库背后的微架构,并且为编写开发新的扩展类库提供帮助和参考。对于需要集成第三方类库的场景,可以使用外观模式进行封装。如果需要提供新的访问入口,可以通过代理模式。
学习设计模式在PhalApi框架的应用,可以帮助我们了解框架的核心设计,对于项目进行定制、二次开发、如何设计接口开发框架会有一定的启发。例如只用一次的单例模式、致力于创建与使用分离的工厂方法模式、多级缓存背后的组合模式、用代理模式巧妙实现数据库分表。
这里尚未列出全部设计模式的应用示例,不是因为其他设计模式不重要或不适用,而是因为由于篇幅有限只是列出了在项目开发、在扩展类库、在框架中常用的设计模式。并且值得一提的是,各个设计模式,都能应用在项目、扩展类库和框架中,例如工厂方法,可以用在项目中创建复杂的对象。这里只是为了避免重复讲解,才划分到了某一小节中,但并不代表只适用于此小节的场景。
最后,在应用设计模式之前,优先考虑最终代码的使用方式,将会大有裨益和启发性。
4.3 小步重构
4.3.1 对过去代码的优化,对将来代码的雕琢
在Martin Fowler先生那本《重构》的书中,我们可以学到很多关于整理代码有用的手法。我觉得不必要刻意去记住这些细致,有点呆板的重构手法,而是在平时时而用之,慢慢就会得心应手了。这里面有一个很值得借鉴的童子军原则:让军营比你来时更干净!
这让我想到了破窗理论,我曾经在一次分享中也提到这点。对于已有的项目,如果先前的代码是整洁的,那么后面的开发同学也会自然而然继续保持整洁,如果原来的代码是混乱不堪的,那么后面开发的同学往往也会继续放而任之。虽然也许同样面临项目交付压力、同样是这位开发人员,但不同的代码风格真的会在潜意识上影响后面的代码风格。在我实际的工作中,我不止一次发现了这个规律。对于我精心开发的代码,后面参与进来的团队开发成员也会尽量精心开发维护,因为他们说怕把我已有的代码不小心“弄脏”了。 那我是怎么做到精心开发的呢?
软件开发有时是艺术,有时是科学,而这里正是科学的重构指导了我进行编写精心的代码。
对于过去已有的代码,可以使用重构进行小步优化,从而慢慢成更灵活、更具可读性、更容易维护的代码。当然,这个过程需要一定时间,也许会很漫长。但方向对了,只要我们努力,总会得到一个好的结果的。但要坚持、敢于持续小步重构。要想得到好的代码,不是因为我们今天做了什么,而在于我们过去一直在做了什么。
而对于新的项目,对于未来投入到生产环境、成为产品的代码,我则会在开发过程中粗糙完成功能后,再用重构慢慢雕琢,像工匠对待他的艺术作品一样慢慢雕琢。根据短而美、单一职责原则、开放-封闭原则、KISS等,我会用心慢慢把我觉得还不够完美的代码进行再调整,直到我认为这是一段好的代码,是一段别人容易理解的代码时,我才结束重构。
我们都熟悉在部队里叠得像豆腐块的棉被,都对它的形状和整齐惊叹不已,但也许并不是每个人都知道这些棉被是通过“三分叠,七分整”,慢慢整理出来的。如同这些方方正正的军用棉被,条理清晰的代码一样需要“三分写,七分整”。写出能实现功能的代码,这是最基本的要求,是一个起点,而非终点,更不是就此可以一劳永逸。而应该在编写完成初步代码后,进行有针对性地整理、优化和重构。不管是对于过去已有的代码,还是未来将投入到生产环境的代码,同样适用。
4.3.2 改善既有的代码
如果你才刚开始使用PhalApi开发接口服务,那么恭喜你,在开始之前就掌握了编写优雅代码的方式。如果你已经使用PhalApi有一段时间,并已经产生一些代码,并且项目中正散发着各种代码异味,那么也没关系,下面我们将来学习如何通过重构,改善既有的代码。
对臃肿Api层的重构
虽然PhalApi采用的是ADM分层模式,也不止一次讲解了各层的职责,但实际项目中不可避免地出现不符合ADM分层模式划分的代码。而最容易发生的情况,莫过于贪图方便,把全部的实现代码都塞在Api层,最后导致Api层过于臃肿。这里的臃肿包括了两层含义:一种是看得到的代码,这些代码长度往往会很长,100行到1000行都很常见,实现了各种功能;另一种是指逻辑上的复杂性或集中性,虽然实现代码很短,但却涵盖了概念视角、规约视角和实现视角多个维度,混淆了领域业务规则与技术实现细节。
回顾前面获取评论丑陋的实现代码,可以发现,有待重构的地方还有很多,其中一点就是在Api层实现了全部的逻辑。这里就以符合ADM分层模式为目标,进行相应的重构。注意,重构的幅度应该是小步的,并且在这过程中应该频繁执行单元测试,以便保证正确性。
首先,我们需要创建领域业务类,并将实现的细节下沉到底层。而在接口类Api_Comment中,只负责高层的决策和对领域业务类的调度。首先,调整接口类后,变成这样:
// $ vim ./Shop/Api/Comment.php
public function get() {
$domain = new Domain_Comment();
return $domain->get($this->id);
}
此时,再次运行单元测试,会提示找不到类Domain_Comment。失败不可怕,重要是知道失败在哪。既然没有Domain_Comment这个类,那么我们来创建它,并在其中完成具体业务规则的实现。这里主要是对数据模型层进行调用,暂时没有其他复杂的业务逻辑。
// $ vim ./Shop/Domain/Comment.php
<?php
class Domain_Comment {
public function get($id) {
$model = new Model_Comment();
return $model->get($id);
}
}
这时,再次运行单元测试,会发现错误已变成了找不到类Model_Comment。回想一下,曾经我们花费在调试的时间有多长,甚至有时为了解决一个空指针的问题都要调试半天,效率是如此的低!现在,有了单元测试的指导,我们可以很明确当前的意图,也很清晰当前的问题。例如这里的错误,会一直指引我们往最终的目标前进,而不会指引我们做必要的事情。
添加评论的Model子类非常简单,由于已经有封装好的Model基类,我们只需要简单地继承即可。
// $ vim ./Shop/Model/Comment.php
<?php
class Model_Comment extends PhalApi_Model_NotORM {
}
对于其他类似的Api接口类,也可以这样依法炮制。
对断层式调用的重构
如果说臃肿的Api层是最常见的问题,那么断层式调用则是第二大问题。那什么是断层式调用呢?
在分层架构里,按不同的职责或出于不同的关注点,会把代码在纵向上划分为多个相对独立的逻辑层。如在领域驱动设计中,Evan把系统分为:表示层、应用层、领域层和基础设施层。在这种情况下,通常分为高层和底层,且高级层依赖于更低的底层,但底层不依赖于高层。高层通常调用相依的底层,但不会对更低的底层进行超级跨层调用。在实际项目中,我经常会看到这种对底层超级跨层的调用,故将这种调用情况称为断层式调用。
领域业务层是一个不可或缺的层,尤其是在大型项目或在处理复杂的业务规则时,我们也不止一次对其进行了详细的介绍。但可能仍然会有开发人员对Domain层不了解,或者认为在简单的项目中,忽略Domain层而直接在Api层调用Model层也是没问题的。如果让这些开发人员来实现前面的获取接口评论接口服务,Api层的代码很可能会是这样。
class Api_Comment extends PhalApi_Api {
... ...
public function get() {
$model = new Model_Comment();
return $model->get($this->id);
}
上面代码中,在Api层直接调用了Model层,中间跳过了Domain层,这就是一个断层式调用的例子。
断层式调用,好不好呢?
在小项目里,更多是需要进行快速开发,为了赶项目进度而寻找便捷途径,开发人员通常会进行断层式调用。这种做法,我觉得对于小项目来说,短期内是有效的。但从长远来说,以及对于大项目来说,出于标准化和规范性,以及项目技术债务的维护角度来说,我则觉得这是不可取的。
为什么不好呢?
继续以上面为例。可以看到,在Api中对Model层进行调用,实际上这个调用过程就是一个实现过程,它可能很简单,也可能很复杂,可能是简单地根据某个参数获取数据即可,也有可能需要根据不同的条件组合处理多种情况。如果别的业务场景也需要同样的数据,那么在断层式调用的情况下,也就很容易导致了“复制-粘贴”编程。当这段调用过程因为业务需要发生变化时,其他调用的场景就需要重复相应更改。同样,如果是因为非功能性需要,在技术层面要在数据库获取前加一层高效缓存,就提升系统的吞吐性,那么也需要同样的大量重复调整。
既然不好,那该怎么进行重构呢?
答案,想必大家都知道了,那就是按PhalApi的ADM分层架构规定设计好的层级进行依次顺序调用,不要进行断层式调用。具体做法是补充Domain层,再在Api层进行调用。最终重构后的代码,可参考上一小节的代码。
很可能会有开发人员反对说,“这样完全没必要!一是因为多一层代码封装会增加开发量,还有就是多一层也会增加对系统的性能影响。”但现在计算机速度已越来越快,添加多这一层,不会造成什么性能上的影响。而对于所增加的开发量,是需要与规范性、项目维护成本进行权衡的,但从长远的角度来看,我认为这是值得的。
4.3.3 以模式为指导进行重构
掌握了重构的方法,也知道了何时应该进行重构,但如果没明确最终需要重构后的结构和目的的话,依然会让人不知所措。一个比较好的建议是,以模式为指导,进行重构。
面对键盘前,屏幕上的乱成一团的代码,就像拧成一团的结,要想把它解开并织成一张漂亮的网,需要有章法可循才行。仔细观察当前混乱的代码,观察它要解决的问题是什么,当知道其所在的问题背景,实现方式和关键点后,根据与之对应的设计模式,便可进行有规律的重构了。
我曾经遇到过这样一个相对复杂的需求,经过简化后,它主要的功能是在不同的页面场景,根据不同的用户类型,以及当前订单的状态,为用户展示不同的常见问题列表。这样是因为客服同事,希望用户能快速找到和他当前可能遇到的问题相关的答案。经过抽象后,它的核心概念是,根据页面场景、用户类型和订单状态这三个维度映射问题ID。其中,页面场景有首页、列表页、详情面,用户类型分A/B测试人群和VIP高级会员,订单状态有未支付、已支付、已签收等。而我一开始的实现方式是直接使用判断语句对各种可能的场景进行处理。下面是示意代码片段。
<?php
class Domain_FAQ {
public function retrieveOrderQuestions($scene, $userType, $orderStatus) {
$questionTag = NULL;
// 根据不同的判断,分配合适的问题标签
if ($scene == 'index' && $userType == 'A' && $orderStatus == ORDER_NOT_PAY) {
$questionTag = 'tag_x';
}
if ($scene == 'index' && $userType == 'B' && $orderStatus == ORDER_NOT_PAY) {
$questionTag = 'tag_y';
}
if ($scene == 'list' && ($userType == 'A' || $userType == 'B') && $orderStatus == ORDER_PAID) {
$questionTag = 'tag_z';
}
if ($scene == 'list' && $userType == 'VIP' && $orderStatus == ORDER_PAID) {
$questionTag = 'tag_m';
}
// ... ...
if ($scene == 'detail' && $orderStatus == ORDER_ARRIVED) {
$questionTag = 'tag_n';
}
// 根据问题标签获取相应的问题信息
$questions = $this->getQuestionsBy($questionTag);
return $questions;
}
}
上面是经过抽离的代码,即抛开了与我们要讲述的问题无关的代码,并且已适当进行整理。虽然如此,但它本身所表示的业务规则并没有清明地表达出来。此外,过多的判断条件,会导致测试在进行语句覆盖特别是状态覆盖时成本更大,也难以保证映射关系的正确性和完整性。最后,对于像最后在详情页并订单状态为已签收的情况,并没有判断人群类型,当别人在走查代码时不好将其定位为业务需要还是开发遗漏。
既然这里存在着一种映射关系,那么我们可以通过配置一份对照表来进行维护,以最简单的方式突显其业务规则。
<?php
class Domain_FAQ {
public function retrieveOrderQuestions($scene, $userType, $orderStatus) {
$questionTag = NULL;
$maps = array(
// (页面场景, 用户类型, 订单状态) --> 问题标签
array(array('index', 'A', ORDER_NOT_PAY), 'tag_x'),
array(array('index', 'B', ORDER_NOT_PAY), 'tag_y'),
array(array('list', 'A', ORDER_PAID), 'tag_z'),
array(array('list', 'B', ORDER_PAID), 'tag_z'),
array(array('list', 'VIP', ORDER_PAID), 'tag_m'),
// ... ...
array(array('detail', 'A', ORDER_ARRIVED), 'tag_n'),
array(array('detail', 'B', ORDER_ARRIVED), 'tag_n'),
array(array('detail', 'VIP', ORDER_ARRIVED), 'tag_n'),
);
foreach ($maps as $item) {
list($conditions, $tag) = $item;
if ($scene == $conditions[0] && $userType == $conditions[1] && $orderStatus == $conditions[2]) {
$questionTag = $tag;
break;
}
}
// 根据问题标签获取相应的问题信息
$questions = $this->getQuestionsBy($questionTag);
return $questions;
}
}
这一版的代码更加清晰,通过配置,我们指定了根据页面场景,用户类型和订单状态到问题标签之间的映射关系。相信很少人会对这种配置式的开发存在误解或者误用。除非不小心拼错单词或者看错需求说明,但这种低级的错误通常不会在有经验的开发人员身上出现。
可以说,重构到此就可以告一段落了。但对于具有工匠精神,追求更优雅代码的开发工程师来说,上面的代码还存在重构优化的空间。有两个问题,可进一步迭代完善,一个是:对于原来最后只需要一行判断的场景,换成配置后需要三行配置,当自变量维度较多时重复的配置就会越多;另一个是,对于其他类似的业务场景,需要重复实现,从而容易产生重复的代码。
让我们再来回头分析一下,上面这种场景的本质是什么。它更像是一棵决策树,根据配置的映射关系可以构建一棵多叉树。即以某个维度为根节点,以当前维度的可能值作为路径,连接到下一个节点维度,并继续以下个节点的可能值作为路径,依次连接下一个节点,赶到穷举为止。最终连接的节点是对应的因变量,它的值就是最终映射的值。把上面的配置表,转换成对应的多叉树,如下所示。
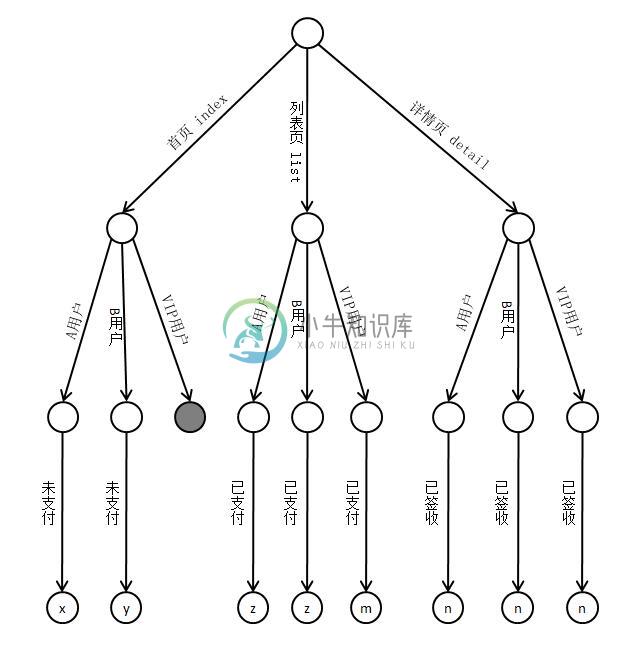
图4-6 根据配置构建的决策多叉树
注意,上图中,灰色的叶节点表示不存在此路径,为图简化,最终其他无效的叶节点未在图示中画出。并且,最终有效的叶节点中为对应的问题标签值,但全都省略了前缀“tag_”,即最左边的叶节点的值为“x”,实际上完整的标签值为“tag_x”。
这时,对于重复出现和问题,可以考虑采用设计模式来解决。我们可以先设计一个专门处理这样根据自变量寻找因变量的类,并约定使用星号表示通配自变量,例如若对任何用户类型都有效,则可将用户类型配置为“*”。下面是封装了这一实现的新的辅助类——决策类。
/**
* 决策类
*/
class Common_Decision {
protected $maps;
public function __construct($maps) {
$this->maps = $maps;
}
public function make() {
// 获取可变的匹配参数
$args = func_get_args();
// 循环穷举判断
foreach ($this->maps as $item) {
list($conditions, $result) = $item;
// 判断当前自变量是否全部匹配
$isMatch = TRUE;
foreach ($args as $key => $value) {
if (isset($conditions[$key]) && ($conditions[$key] == '*' || $conditions[$key] == $value)) {
continue;
} else {
$isMatch = FALSE;
break;
}
}
// 若路径命中,若返回
if ($isMatch) {
return $result;
}
}
return NULL;
}
}
上面的进行决策的Common_Decision::make()方法,会根据客户端提供的动态参数,结合构造函数提供的配置参数,进行映射匹配,最终返回命中的因变量。
有了这么一个公共的决策类后,以后需要在业务场景进行决策,就更容易了。以下是重构调整后的代码。
class Domain_FAQ {
public function retrieveOrderQuestions($scene, $userType, $orderStatus) {
$maps = array(
// (页面场景, 用户类型, 订单状态) --> 问题标签
array(array('index', 'A', ORDER_NOT_PAY), 'tag_x'),
array(array('index', 'B', ORDER_NOT_PAY), 'tag_y'),
array(array('list', 'A', ORDER_PAID), 'tag_z'),
array(array('list', 'B', ORDER_PAID), 'tag_z'),
array(array('list', 'VIP', ORDER_PAID), 'tag_m'),
// ... ...
array(array('detail', '*', ORDER_ARRIVED), 'tag_n'),
);
$decision = new Common_Decision($maps);
$questionTag = $decision->make($scene, $userType, $orderStatus);
... ...
}
}
从原来的决策实现,到现在的决策调度,开发人员只需要简单配置即可完成对应业务场景的功能,其他的则由经验丰富的开发人员在公共决策类中实现。例如这里的配置,但需要注意的是最后一行配置相当于原来的三行配置,因为使用了“*”通配符。
为了说明对此公共决策类的重用,假设现在另外有另一个业务场景也需要进行类似的判断,那就是在网站一般都会存在的功能:将技术开发用于区分性别的标记值转换成展示给最终用户的文案。在这个场景中,“male”转换为“男”,“female”转换为“女”,其他为“未知”。根据这些规则,便有了下面的代码。
class Domain_Sex {
public function turnToWorld($sex) {
$maps = array(
array(array('male'), '男'),
array(array('female'), '女'),
array(array('*'), '未知'),
);
$decision = new Common_Decision($maps);
return $decision->make($sex);
}
}
通过底层依赖于公共的决策类,并且配置好对应的关系后,我们得到了维护着性别领域业务规则的Domain_Sex类。随后,便可这样进行使用:
$domain = new Domain_Sex();
// 输出:男
echo $domain->turnToWorld('male'), "\n";
// 输出:女
echo $domain->turnToWorld('female'), "\n";
// 输出:未知
echo $domain->turnToWorld(''), "\n";
这里演示的场景,当然也可以使用简单地判断进行实现,可能你会觉得使用决策类实现会有点大材小用,但请别误会,这里仅是为了说明在其他类似的场景可以复用抽离的公共决策类。除此之外,对于通配的规则,需要其优先级顺序,应该把带有“*”号的规则放在最后,以便前面优先匹配具体特定的规则。如果对于不想使用通配符,或者想重新定制配置规则的格式,都是可以的。同样,在这里实现决策类只是为了演示如何通过模式作为指导抽离与业务无关的公共类,进而通过重构得到架构明显的编程风格。
用模式作为指导进行重构吧!你将会得到浮现式的设计。
4.3.4 重构这条路
可以说,前面所介绍的关于重构的技巧或者方法,适用于小型的,局部的重构。当要重构的代码是出自你之手,或者是你正在编写的新代码,又或者是虽然不是你写的但只是一小块代码有异味,这时使用上面的技巧和方法是可以解决的。然而,项目开发就像一盒巧克力,你永远不会知道下一个遇到的会是什么项目。什么项目最难开发?历史遗留系统。什么项目最难重构?历史遗留系统,尤其是辗转交接几个团队、历史悠久、无文档、线上问题众多却依然仍在运行、承载着重要流程业务的系统。这里,如果需要重构,需要的不仅仅是针对局部的技巧或方法,还需要总揽全局的策略和可行的计划。
痛苦的历史遗留系统
曾经我接手过一个系统,它是我当时自毕业参加工作以来遇到过最棘手的历史遗留系统,没有之一。它之所以复杂、维护成本高昂、到处充斥着难以忍受的代码异味,不在于本身所负责的业务功能,更多在于所依附的主体 – – 它的前生。它的问题,通常包括但不限于:
- 无文档,基本是零文档
- 很多是没用的代码,只有少量有用的代码
- 前后辗转交接了多个个开发团队
- 到处是意大利面条式代码,混乱不堪,充斥着多种编程风格
- 线上问题众多,如各种遗留BUG
然而,历史遗留系统却仍在支撑着某些重要的业务功能。或者说,是在苦苦支撑着。鉴于它在很长一段时间内还会承载着重要的业务。为此,是时候做出改变了!我们要优化它,不仅了为了解决当前所遇到的问题,更是为了从长远角度考虑,为今后的维护和业务发展做好最充足的准备。就这样,故事开始了。艰难的征途,也开始了。在接手半年左右后,我们团队花了近 3 个月的时候对这个庞然大物进行了大步的重构和清理,在此过程中,付出和投入的时间精力是巨大的,同时还面对很高的风险、充斥着新需求、线上故障排查、历史问题优化、安全部门介入等其他事宜。这是一段艰难的岁月。我们都担心着,如果清理重构后出了什么问题而使得这个域越来越糟的话,恐怕我们就要引咎辞职了。
出于对商业信息的保密,我们暂且在这把这个项目称为:X系统,并且部分信息已省略。
一个隐喻
一个隐喻:维护一个项目,就像养一只宠物,你得要用心,用心,再用心。
养一只小宠物,我们都希望它除了能给自己带快乐,也希望它能为身边的其他人带来欢馨、愉悦。我们希望它听话,不惹事、不闯祸,得到别人的赞许和肯定,并且在每天照顾它的过程中,我们感受到的更多是轻松、愉悦。如同维护一个项目,我们也都希望自己会喜欢它、使用它,也希望它能为最终用户提供帮助、提供有价值的服务。我们希望它稳定,不出故障、不失控,能得到大家一致的认可,并且在每天开发、维护它的过程中,能应付自如,富有成就感和为此自豪。
但很多时候,现实都不是我们想象的那样。
一如X系统,它就像一只难以驯服的宠物,而且还到处惹事,处处给用户带来不好的体验,需要我们焦头烂额地跟在它后面修修补补。这也不是X系统本身的错。就像一只宠物出生后,最终是变好还是变坏,更多是受它的成长经历影响,要看下它曾经经历过什么事。
考虑到X系统包含着是长期重要的业务,我们决定在这最艰难的时候做出改变:对它进行清理、重构、优化。不管它现在是如何的糟糕,主要往好的方向慢慢调整,总有一天,它也会成为人见人爱的小宠物。只是,一开始的这刻,是非常痛苦的。
重构的计划与策略
在踏上重构这条路后,我们便可以制定可行的计划,在保证既有的功能不受影响的同时,又能保障新的业务需求可以并行开发。经过一番慎重的思考,结合X系统当前的情况,其重构的计划与策略是:
第1步、前期准备 在对X系统进行大改造、脱胎换骨之前,如同做重大的手术一样,我们需要先进行细腻的前期准备。特别对于刚接手不久的项目,需要对项目有了很透彻的了解后,方能做出更正确的操作。可通过查看源代码,熟悉业务,通过整理补充文档加深对业务的把握。总而言之,在改变它前,我们需要了解它。需注意的是,我们要进行的是一项高风险任务,任何一个细节的疏忽,都有可能导致大故障!
第2步、先清理,解耦;再重构,优化 好的代码都是相似的,而坏的代码却各有各的不同。根据《恰如其分的架构》,项目使用框架的情况主要有三类:架构无关、专注架构、提升架构。结合在这几年开发过的项目,我把这些分类再进行了细分,有:使用特定框架以满足荷刻的领域需求、使用外部开源框架、使用内部自主框架、不使用任何框架。很难断定哪种情况是最好或最坏,但显然最后那种没有任何框架的项目,因缺少约束和标准,势必会衍生出更丑陋、更不可控的代码。不幸的是,X系统正是这种情况。为了控制好风险,我们制定了拯救的策略:先清理、解耦;再重构、优化!清理是指删除那部分没用的代码,解耦是指解除X系统对其他系统无用的依赖关系,重构是对现有的代码异味根据重构的模式进行小步调整,优化是对过往不合理的地方进行改善,增强代码的生存能力。
第3步、强化在线调试模式 虽然原来也有调试模式,但调试的方法和实现不一致,而且也没能达到当前开发的需要。为此,我们重新定制了一套强大的组合调试模式。开启调试模式后(为安全起见,此调试模式仅能在开发、测试环境使用,在生产环境无法使用),还需要添加 debug 参数方能进行详细的调试。debug 是一个位组合开关,关于 debug 参数,使用说明如下:
表4-1 强化后的调试方式
| 位(从低位到高位) | 对应的 debug值 | 开关名 | 说明 | 示例 |
|---|---|---|---|---|
| 第 1 位 | 1 | 基本调试模式 | 通常需要开启,包括显示错误信息 | &debug=1 |
| 第 2 位 | 2 | 免缓存调试 | 主要是禁用缓存 | &debug=2 |
| 第 3 位 | 4 | 数据库调试 | 主要是用于打印所执行的数据库查询语句,以及异常信息 | &debug=4 |
| 第 4 位 | 8 | 接口调试 | 主要用于打印请求的底层接口,以及异常信息 | &debug=8 |
| 组合 | {以上值累加} | 万能调试模式 | 组合上面全部的调试 | &debug=15 |
- 第4步、纳入自动化单元测试 X系统代码僵硬、腐化、处处是代码异味,处处是反模式,需要往好的方面一点点、一步步调整、优化、迭代。在细心修正这些本来已有的问题,消除绝大部分的熵让项目趋于稳定状态后,再进一步,就是纳入自动化测试体系,提高项目的可测试性,为日后的新功能开发、旧业务维护、技术重构提供可靠的具有自我验证能力的安全网。但历史遗留系统要具备可测试性,是要付出相当大的成本的,在这里,我们需要做的就有:把面向过程的写法改成面向对象的写法,把全局变量换成从容器取资源,把 PHP 原生的底层函数使用包装模式封装成类。成功纳入自动化单元测试后。虽然一开始覆盖率还很低,但没关系,我们已经扫除了纳入自动化测试的障碍,完成了从0到1,下一步我们会逐步提升,完善这张 360 度的安全网。
站在历史的转折点上
经过几次上线后,解决了大部分遗留问题后,X系统终于慢慢步入了正轨。值得一提的是,在做了这么多工作后,我们上线的版本,虽然改动巨大,但从没出现过问题。另外,对于重要的问题,我们排查了大量的日记,并做了详细的纪录,以便给后面新来的项目成员参考、熟悉、了解。
慢慢地,我们逐渐收到了产品关于X系统良好的统计数据及效果评估,而不再是之前那种对现状不满、愤怒的邮件。X系统终于从一个历史遗留系统变成了一个乖巧的小宠物。现在的它,更小、更快、更稳健、更招人喜欢。
本章小结
重构、单元测试驱动和设计模式,这三者之间存在着微妙的关系。由于经常会重复提到重构、TDD和设计模式,我们暂且在这里把这三者称为:开发“三把斧”。经过总结后,我觉得他们之间的关系如下所示:
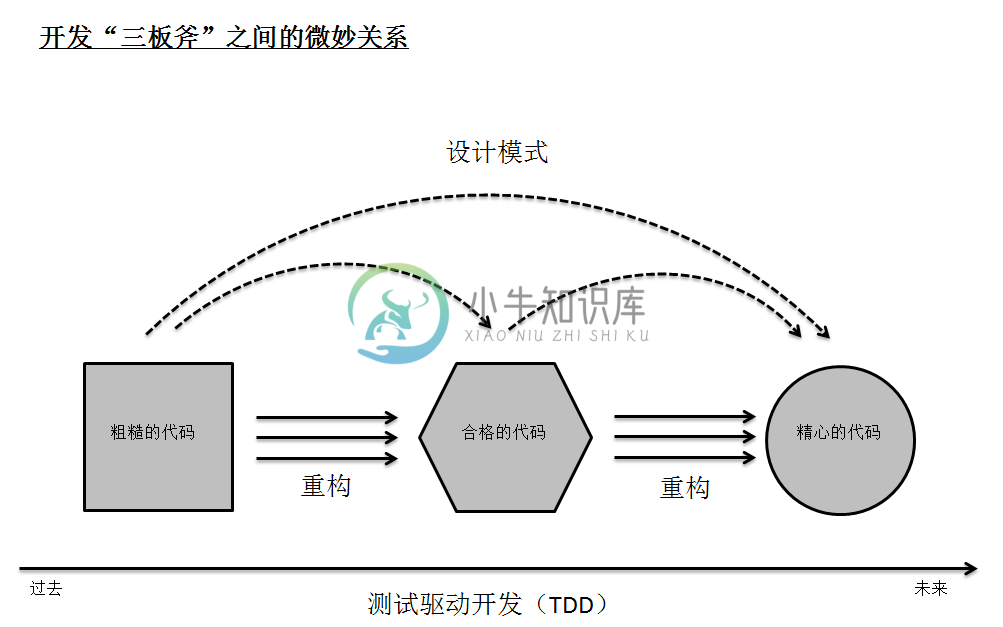
图4-7 开发“三把斧”之间的关系
从上图可以看出,最下面的是TDD,也就是说测试驱动开发是一项应该落地的实践,也是我们开发的基础。从头到尾,由始至终,我们都应该遵循测试驱动开发。说白一点,还没开始编写产品代码时,我们就应该编写测试代码,哪怕最后完成了产品代码,我们依然还要运行测试套件。
在中间,在三个层级的代码,从左到右,我们暂且命名为:粗糙的代码、合格的代码、精心的代码,分别代表坏代码、中等代码和好的代码。一般这些都是循序渐进的,即最初我们编写的是粗糙的代码,继而调整为合格的代码,最后雕琢成精心的代码。当然,也有一步到位的情况,但我们这里所讲的适用普通大众的情况。
而在这三等代码之间,要实现往上一级的转换,则需要使用到各种重构的手法。重构的手法多种多样,故而有多个箭头指向,这也就说明了不同的开发人员可以采用不同的重构方式,毕竟条条大路通罗马,代码没有绝对的表现形式。
再往上,即最顶上,则是我们的设计模式。注意,这里使用了虚线,即与实线的重构、实线的TDD不同,它是一种虚的东西。虽然设计模式也有其名称、实现步骤、成例和注意事项等具体的内容,但我觉得设计模式更像是高层的思想,正是它指导了我们往更好的方向前进。所以,在这里我把设计模式作为了我们最高的指导思想。
这三者应该是相互影响、相互促进的。缺少了TDD,我们就缺少了有力的保障,就没有了安全可靠的测试基础。缺少了重构,我们就会迷失于如何把代码变得更好的细节中。而缺少了设计模式,我们就会漫无目的地进行重构而不知所终,因为我们不知道最终该如何确切组织我们的代码。