
第7章 一个极致的项目
如果说第5章的WeTime项目是对现有新功能进行的开发,第6章的Family 2.0 项目是对过去既有代码的重写,那么这一章我们将会学习的是,如何为未来编写开发一个极致的项目。可以说,这一章讲述的主要是如何设计、规划和研发大型的项目。
7.1 项目背景
对于大型项目,其开发流程更为正式,规范更为细致。除了从技术方面会涵盖数以百计的接口服务,运行在强大阵容的服务器集群,以及每时每刻都处理着高并发的请求外,在人员与沟通方面会涉及开发人员,测试人员,运维人员,DBA,架构师,项目经理,发布组,产品人员等。有了这么多项目干涉人员之后,自然就会有基于跨部门团队协作的各种流程,单纯是各种评审与审计工作就有:需求评审,设计评审,变更评审,安全评审,代码评审,架构评审。从一个需求被提出来,到最终上线发布,其间通常会经历的环节包括但不限于:需求评审,项目排期,开发与自测,前、后端联调,系统联调,提测,进行测试阶段,回归测试,灰度发布,线上发布,验收。
为此,开发大型项目的方式与以往开发中、小项目的方式不一样,因为前者所涉及的人员、技术和流程更为复杂,任何一行改动的代码,需要发布并运行在线上环境,有一段漫长的路要走,从而需要维护的成本就更大。项目背景不一样,决定了开发方式的不同。那对于大型项目,我们又应该怎样进行开发呢?
下面,让我们一起来探讨。因为这一章更多是讨论开发大型项目所推荐的规范与标准,所以本次极致的项目名称取名为Forever,对应的接口系统域名假设为:api.forever.com。
7.2 Api接口层的规范
7.2.1 一个接口服务,一个文件
对于Api接口层,一种极端做法是,把全部的接口服务都放在同一个文件。显然,这会造就庞然大物,也不会有人这么做(如果真的有,请记得把源代码分享我膜拜一下)。而另一种极端做法是,对于每一个接口服务,都单独放在一个文件中。这样的话,不用担心在修改其他接口服务时,哪怕是在同一个接口类中的不同方法,也不用再担心会影响其他接口服务。
以常见的用户模块的接口服务为例,登录接口层源代码单独放置在Api/User/Login.php这一文件里。
// Forever$ vim ./Demo/Api/User/Login.php
<?php
class Api_User_Login extends PhalApi_Api {
}
对于用户注册接口服务,则单独放置在Api/User/Register.php这一文件里。
// Forever$ vim ./Demo/Api/User/Register.php
<?php
class Api_User_Register extends PhalApi_Api {
}
对于用户登录态检测接口服务,则单独放置在Api/User/Check.php这一文件里。
// Forever$ vim ./Demo/Api/User/Check.php
<?php
class Api_User_Check extends PhalApi_Api {
}
其他接口服务,依此类推。就上面用户模块的三个接口服务而言,对应的文件如下:
Forever$ tree ./Demo/Api/
./Demo/Api/
└── User
├── Check.php
├── Login.php
└── Register.php
7.2.2 更简单请求的形式
如果按照每个接口服务一个文件划分后,接着就会引发一个新的问题:如何为接口服务的类方法命名?为了减轻后端开发人员命名的压力,同时保持高度一致性,可以统一使用相同的类方法名。此方法名应该是简短、有活力、贴切的,例如统一使用go()方法名,那么对于上面的用户模块,那三个接口服务的源代码就会变成这样:
// Forever$ vim ./Demo/Api/User/Login.php
class Api_User_Login extends PhalApi_Api {
public function go() {
}
}
// Forever$ vim ./Demo/Api/User/Register.php
class Api_User_Register extends PhalApi_Api {
public function go() {
}
}
// Forever$ vim ./Demo/Api/User/Check.php
class Api_User_Check extends PhalApi_Api {
public function go() {
}
}
那么,便可以得到默认请求接口服务的URI,但明显可以看到在接口服务名称service参数中,每次请求时都需要重复加上“.Go”这一后缀,不仅影响美观,而且显得冗余。解决的方法很简单,可以使用前面所学的知识,定制我们自己专属的service格式。同时,结合Nginx的Rewrite规则,可以定制一种更简单的请求方式。先来看下最终的请求效果。
表7-1 请求用户模块接口服务的URI
| 接口服务 | 默认的URI | 定制后更精简的URI |
|---|---|---|
| 用户登录 | /demo/?service=User_Login.Go | /demo/user_login |
| 用户注册 | /demo/?service=User_Register.Go | demo/user_register |
| 会话检测 | /demo/?service=User_Check.Go | demo/user_check |
可以看到,定制后请求接口服务的URI更为精简,并且也更符合URI的格式,即全部使用小写字母,并用下划线分割。
要达到这样的效果,需要结合Nginx的Rewrite规则和service格式的定制。首先,对于Nginx,需要添加下面这样的Rewrite规则:
if (!-e $request_filename) {
rewrite ^/demo/(.*) /demo/?service=$1;
}
配置后,记得需要重启Nginx。
接下来,是对service格式的定制。这里需要继承请求量PhalApi_Request,然后重写PhalApi_Request::getService()方法,实现定制化的工作。代码实现如下:
// Forever$ vim ./Demo/Common/Request.php
<?php
class Common_Request extends PhalApi_Request {
public function getService() {
$service = parent::getService();
// 兼容默认格式
if (strpos($service, '.')) {
return $service;
}
// 定制后的格式:大写转换 + 后缀
$className = preg_replace("/(?:^|_)([a-z])/e", "strtoupper('\\0')", $service);
$newService = $className . '.Go';
return $newService;
}
}
实现好扩展的子类后,别忘了要在入口文件合适的地方进行注册。如下所示:
// Forever$ vim ./Public/demo/index.php
DI()->loader->addDirs(array('Demo'));
DI()->request = 'Common_Request';
此时,在浏览器使用新定制后的service格式访问,便能达到与默认形式同样的访问效果。
7.2.3 参数规则配置
大部分接口服务都会需要接口参数,在一个接口服务,一个文件的情况下,对于参数规则的配置,主要区别在于代码排版方面。不同于之前把全部配置写在一行的做法,在这里更倾向于将配置写成多行,从而提供更统一、更整洁的写法。例如上面登录接口服务User_Login.Go中所需要的登录账号与登录密码这两个参数,写法如下:
class Api_User_Login extends PhalApi_Api {
public function getRules() {
return array(
'go' => array(
'user' => array(
'name' => 'user',
'require' => true,
'min' => '1',
'desc' => '登录账号',
),
'pass' => array(
'name' => 'pass',
'require' => true,
'min' => '6',
'desc' => '登录密码',
),
),
);
}
... ...
并且,对于各个参数规则,通用配置项的顺序,从上到下,分别是:
- 参数名称 name
- 是否必须 require
- 默认值 default
- 最小值 min
- 最大值 max
- 不同类型参数的扩展配置项,如:regex,range,format,ext等
- 数据源 source
- 说明信息 desc
7.2.4 接口实现与返回规范
在实现Api接口层时,通常来说,分为以下这些步骤:
- 1、定义返回结果的顶级字段结构
- 2、初始化Domain实例并调用
- 3、将结果依次进行赋值
- 4、返回结果
例如,在实现用户登录时,其代码片段为:
class Api_User_Login extends PhalApi_Api {
public function go() {
$rs = array('code' => 1, 'user_id' => 0, 'token' => '', 'tips' => '');
$domain = new Domain_User();
$userId = $domain->login($this->user, $this->pass);
if ($userId <= 0) {
$rs['tips'] = '登录失败,用户名或密码错误!';
return $rs;
}
$token = DI()->userLite->generateSession($userId);
$rs['code'] = 0;
$rs['user_id'] = $userId;
$rs['token'] = $token;
return $rs;
}
}
为了方便开发人员明确所返回的结构字段,在函数的第一行可定义结果的顶级字段,并使用默认值进行填充。结合上面的代码,可以看到,这里定义了返回结果的字段中有操作码、用户ID、登录凭证和提示信息。
$rs = array('code' => 1, 'user_id' => 0, 'token' => '', 'tips' => '');
然后初始化了Domain_User领域业务类的实例,并传入登录账号和登录密码尝试进行登录。如果登录失败,则使用卫语句直接失败返回,并进行相应的提示。如果登录成功,则通过User扩展生成一个新的会话凭证。
$domain = new Domain_User();
$userId = $domain->login($this->user, $this->pass);
... ...
$token = DI()->userLite->generateSession($userId);
调用领域业务类的实例完成业务功能后,接下来需要把获得的结果以及客户端需要的数据赋值给返回结果变量中。并且,最初定义结果的字段顺序,与实现过程中的获取顺序,以及最后赋值的顺序应该是保持一致的。如这里,依次是赋值了操作码、用户ID和登录凭证。对于不需要进行赋值的结果字段,则可以忽略路过,如这里的tips错误提示字段。
$rs['code'] = 0;
$rs['user_id'] = $userId;
$rs['token'] = $token;
最后一步,非常简单,直接返回结果即可。
虽然PhalApi框架在返回结果的最外层提供了状态码ret字段,但这个字段是技术框架层面的,并且错误时的最外层的msg错误信息字段也是针对技术开发人员,而非面向最终使用用户的。因此,有必要在业务返回结果中再定义自己的业务操作码,以及业务提示文案信息。例如,这里统一定义了业务操作码为code,为0时表示成功,非0时表示失败,并且不同的业务操作码对应不同的业务场景。而业务提示文案信息则用tips字段表示。
7.2.5 注释规范与自动生成文档
完成Api接口层代码的编写后,还有一个非常关键并且重要的事情,就是添加必要的注释,以便能自动生成对应的在线接口文档,提供给客户端开发同学查看使用。
简单地回顾一下,在接口类中的注释主要有以下三部分。第一部分是接口服务类的文档注释,对应在线接口列表文档的菜单说明。例如:
<?php
/**
* 用户登录
* @author dogstar 20170622
*/
class Api_User_Login extends PhalApi_Api {
... ...
第二部分是接口服务方法的注释,这部分包含接口服务的名称以及描述说明。例如:
class Api_User_Login extends PhalApi_Api {
/**
* 用户登录接口
* @desc 根据账号和密码进行登录,成功后返回凭证
*/
public function go() {
... ...
第三部分,是各返回结果字段的说明,以及错误异常码的说明。例如,添加返回结果字段说明的注释后:
/**
* 用户登录接口
* @desc 根据账号和密码进行登录,成功后返回凭证
*
* @return int code 业务操作码,为0时表示成功,非0时表示登录失败
* @return int user_id 用户ID
* @return string token 登录凭证
* @return string tips 文案提示信息
*/
public function go() {
... ...
补充完整注释后,便可以查看对应自动生成的在线文档。例如,上面登录接口服务的注释,生成的在线文档,效果如下:
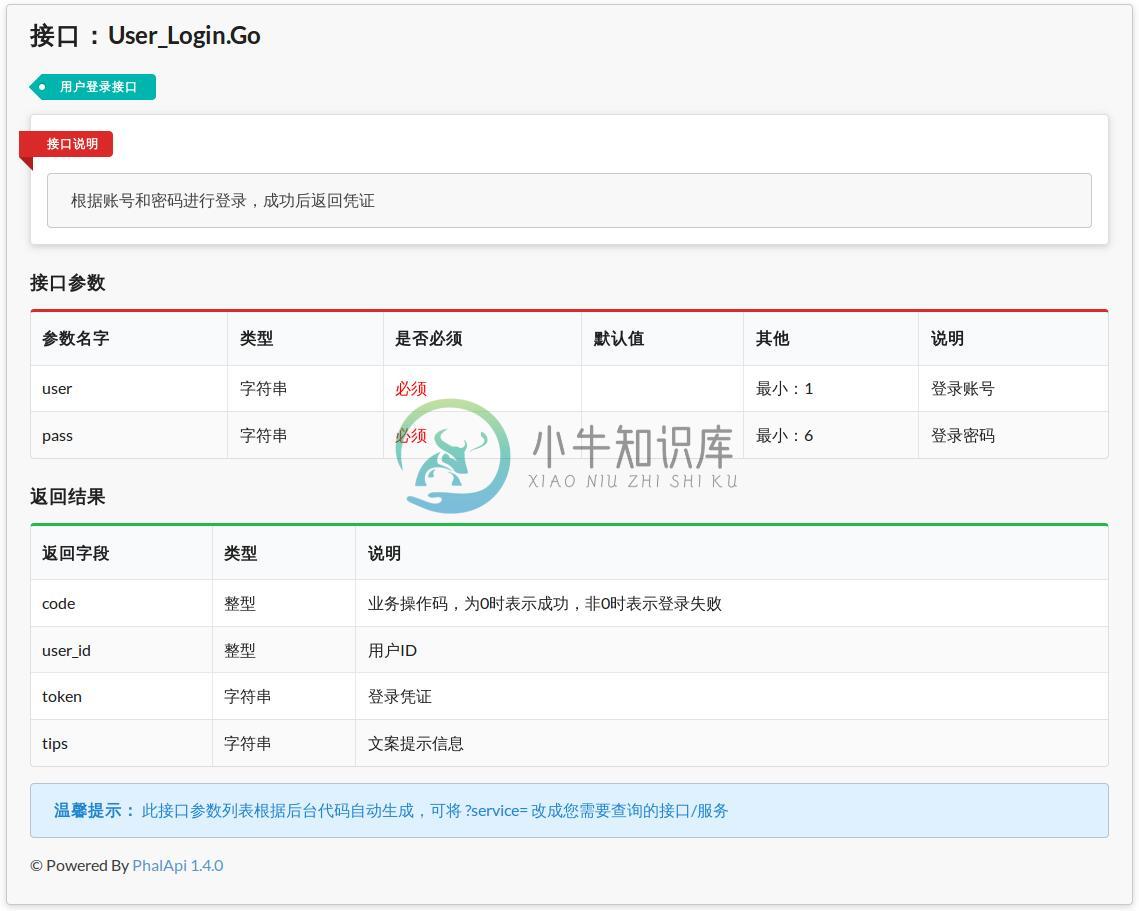
图7-1 自动生成的登录接口服务在线文档
7.3 Domain领域层的规范
PhalApi框架主要的分层模式是ADM,其中最为重要的是Domain领域业务层,它承载着最核心的领域业务的实现,特别对于大型项目,所面临的业务复杂性更高。软件开发的本质就是要尽量降低复杂度,因此有必要在此再对Domain领域业务层进行说明与探讨。系统中的复杂度又往往集中在各对象动态运行时的依赖关系,如果处理不当,就会引起混乱,诱发代码异味。在领域业务中,对这些对象一个很好的划分就是分为实体、值对象和服务。理解这三个概念,对于项目开发是大有禆益的。
7.3.1 实体
实体是最为常见的对象,它们主要特点是有存储在数据仓库的数据属性,以及基于这些属性的行为操作,是有状态的。实体与实体之间的区别,不仅表现在数据属性上的不同,还可以表现在唯一标识上的不同。数据仓库的实现机制不限,可以是常用的数据库,也可以是NoSQL,或者是简单的文件。实体与数据仓库是需要进行双向交互的,不仅需要从数据仓库中获取数据,还需要将添加或更新、删除的数据同步到数据仓库。
继续以用户登录为例,Domain_User领域业务类可以说是一个实体,因为它需要依赖数据仓库获取用户数据,进而与客户端提供的参数进行比较。以下是实现代码片段:
// Forever$ vim ./Demo/Domain/User.php
<?php
class Domain_User {
public function login($user, $pass) {
$servicePass = new Domain_Password();
$encryptPass = $servicePass->encrypt($pass);
$model = new Model_User();
return $model->login($user, $encryptPass);
}
}
在后半部分,通过Model层,根据用户名与加密后的密码获取相应的用户ID。
实体类的对象通常是上层Api层的访问入口,在其内部,又会涉及到服务对象与值对象的协同工作。例如上面登录操作中就使用了密码加密服务类Domain_Password。接下来,让我们来了解一下领域业务中的服务。
7.3.2 服务
实体是有状态的,而服务是无状态的。服务是一组通用的功能集合,实例化一个服务对象后,便可以使用它进行重复的操作。如上面所说的密码加密服务类,一旦实例化后,它可以对各种密码进行加密操作,并且前面的加密与后面的加密是无任何联系的。
我们先来看下对于Domain_Password的最终使用,再来看下它内部的实现。实例化Domain_Password类的对象很简单,因为它不需要任何参数,然后便可多次进行密码的加密。例如:
<?php
$servicePass = new Domain_Password();
// 对密码“123456”进行加密
$pass1 = $servicePass->encrypt('123456');
// 对密码“i_am_18”进行加密
$pass2 = $servicePass->encrypt('i_am_18');
// 对密码“who_am_i”进行加密
$pass3 = $servicePass->encrypt('who_am_i');
服务是不依赖于数据存储的,但它通常会依赖于一些公共的基础设施。这些基础设施可以是PhalApi框架的基础模块,也可以是扩展类库,还可以是自己封装的与业务无关的组件。例如这里就使用了加密技术。因此就不难理解此加密服务的实现细节了。
// Forever$ vim ./Demo/Domain/Password.php
<?php
class Domain_Password {
const CRYPT_KEY = '06633f94d3';
protected $mcrypt;
public function __construct() {
$iv = DI()->config->get('sys.crypt.mcrypt_iv');
$this->mcrypt = new PhalApi_Crypt_MultiMcrypt($iv);
}
public function encrypt($pass) {
return $this->mcrypt->encrypt($pass, self::CRYPT_KEY);
}
public function decrypt($encryptPass) {
return $this->mcrypt->decrypt($encryptPass, self::CRYPT_KEY);
}
}
虽然服务不需要持久化数据,但会有各自的配置选项,以满足不同场景下的使用。这也是为什么我们在使用扩展类库时需要进行配置的原因。又例如这里,配置了8位的加密向量sys.crypt.mcrypt_iv,此配置位于./Config/sys.php配置文件中,如下所示:
/**
* 加密
*/
'crypt' => array(
'mcrypt_iv' => '12345678', //8位
),
服务可以是与业务有关的,也可以是与业务无关的。上面的密码加密就是与业务有关的,因为它是专门针对密码进行的加解密操作。而PHPMailer邮件扩展则是与业务无关的,因为它可以用来发送任何类型的业务邮件。当然,也可以在业务无关的服务上,再封装业务有关的服务,以便上面应用更快地重用,并且保证业务的一致性。
7.3.3 值对象
在领域业务中,还有一种不可或缺的对象是值对象。尤其在大型系统中,值对象可以说是一种简化设计,减少缺陷的一种有效途径。值对象一个很重要的物质是不可变性,即一旦创建后就不能再修改。所以,在实现值对象时,可以不提供任何setter方法,也不提供任何修改成员属性的方法,只允许在构造函数时进行传参初始化。
值对象可以是基本的数据类型,如整数、布尔值、浮点数,也可以是自定义类类型。关于值对象,鉴于前面已有介绍说明,这里不再赘述。
7.4 Model数据层的规范
最后到了Model数据层,前面已经多次说到,PhalApi框架中的Model层是广义上的数据源层,它的数据不仅仅局限于数据库。特别在大型项目中,其数据来源更为丰富多样,也更为复杂。
小结一下,对于Model层,其数据存储方式可分为以下四大类。
- 关系型数据库
- NoSQL
- 远程系统
- 文件
下面分别进行说明。
7.4.1 常见的关系型数据库对接
绝大部分的系统都会使用到关系型数据库,例如MySQL、Microsoft SQL Servcer、Oracle、SQLite、PostgreSQL等。在使用数据库构建大型系统时,有以下几个方面需要注意的。
对于数据量大的表,考虑分表存储
在我职业生涯中,不止一次看到公司因需要进行数据库迁移而大动干戈,小则在夜深人静,用户酣睡时进行迁移操作,大则在迁移前进行动员大会、模拟演练、发布停站升级公告,然后暂停各大系统之间的通讯并按计划严谨进行迁移,连每一个时间点哪个人需要做什么都要细无巨细进行统筹。需要迁移的一个很大原因是,受限于单台服务器的硬盘空间以及数据库本身的存储限制,不能满足业务系统日益膨胀的数据规模。
当然,我也曾非常有幸,在任职过的一家游戏公司中,了解并实践了水平分库分表这一思想。这不仅隔离了数据上的风险,还为可预见的海量数据打下了坚实的基础。因此,在设计之初就避免了日后迁移的维护成本。
需要注意的是,对于数据量大的表,应该考虑分表存储,而不是一定要使用分表存储。进行分表存储一个很大的缺点就是,难以进行数据库表之间的关联查询。如果考虑使用分表策略,那么此数据库表是否不需要关联查询,或者说可以通过其他方式弥补这一点?这些都是需要权衡的点。
在PhalApi进行分表存储时,其实现方式很简单,主要分别:配置、实现和使用这三步。
- 分表配置 首先,在数据库配置文件Config/dbs.php中进行分表的配置。
- 分表实现 其次,在Model实现子类中,重载获取表名方法实现分表的方式。
- 分表使用 最后,便可以使用分表存储了。
让我们通过User扩展类库中的用户会话分表,再来回顾一下这三个步骤。首先,分表配置主要是通过map选项来指定,如下所示,对于用户会话表phalapi_user_session,共分了10张表,分别是:phalapi_user_session_0、phalapi_user_session_1、……、phalapi_user_session_9,以及默认缺省表phalapi_user_session。
return array(
'tables' => array(
'user_session' => array(
'prefix' => 'phalapi_',
'key' => 'id',
'map' => array(
array('db' => 'db_demo'),
array('start' => 0, 'end' => 9, 'db' => 'db_demo'),
),
),
)
);
其次,在Model实现子类中,重载PhalApi_Model_NotORM::getTableName($id)方法,指定分表名称。通常做法是,根据参照ID进行求余,然后将余数作为分表的后缀标识。
class Model_User_UserSession extends PhalApi_Model_NotORM {
const TABLE_NUM = 10;
protected function getTableName($id) {
$tableName = 'user_session';
if ($id !== null) {
$tableName .= '_' . ($id % self::TABLE_NUM);
}
return $tableName;
}
... ...
最后,便可使用分表存储了。使用的方式又可以分为两大类,当使用全局的访问方式时,可直接手动指定分表名称,如:
// 使用phalapi_user_session_0分表
$session0 = DI()->notorm->user_session_0;
// 使用phalapi_user_session_1分表
$session1 = DI()->notorm->user_session_1;
// ... ....
// 使用phalapi_user_session_9分表
$session9 = DI()->notorm->user_session_9;
若是直接使用原生SQL拼接时,则还需要手动加上表前缀,例如:
$sql = 'SELECT count(*) as num FROM phalapi_user_session_0';
当使用局部的访问方式时,对于基本的已封装的CURD操作,可以通过参数ID指定对应的分表,例如:
$model = new Model_User_UserSession();
// 查询phalapi_user_session_0分表
$row = model->get(10);
// 查询phalapi_user_session_1分表
$row = model->get(1);
// ... ....
// 查询phalapi_user_session_9分表
$rsow = model->get(9);
若是在Model实现子类内部时,则可以使用PhalApi_Model_NotORM::getORM($id)方法,传入参数ID并获取对应的分表实例。例如:
class Model_User_UserSession extends PhalApi_Model_NotORM {
public function doSth() {
// 获取phalapi_user_session_1分表实例
$session1 = $this->getORM(1);
}
}
因此在使用时,可根据业务的需要,自行选择合适的方式。值得注意的是,当没有对应的分表时,将会回退使用默认的主表。
对于高并发的查询,使用缓存
在大型系统中,应对高并发访问的一个行之有效的方案是使用高效缓存来提高系统的响应时间与高可用性。适合使用缓存的场景可以有:
- 幂等查询
- 允许一定的延时
- 计算成本高或耗时的操作结果
对于大型项目中复杂的数据查询,PhalApi提供了一种经验作法。以下这个示例很好地演示了如何使用此经验做法。
首先,实现PhalApi_ModelProxy接口,并实现具体的源数据获取的过程,并指定缓存的键值和缓存时间。
class ModelProxy_UserBaseInfo extends PhalApi_ModelProxy {
protected function doGetData($query) {
$model = new Model_User();
return $model->getByUserId($query->id);
}
protected function getKey($query) {
return 'userbaseinfo_' . $query->id;
}
protected function getExpire($query) {
return 600;
}
}
随后,通过查询值对象,获取相应的数据。
class Domain_User {
public function getBaseInfo($userId) {
$rs = array();
$query = new PhalApi_ModelQuery();
$query->id = $userId;
$modelProxy = new ModelProxy_UserBaseInfo();
$rs = $modelProxy->getData($query);
return $rs;
}
}
这样,一来可以把每个数据单独实现在职责单一的代理类中,二来可以避免重复对缓存的公共操作。
对于耗时的更新和写入操作,移至后台异步计划任务
虽然查询类的数据结果可以缓存,但对于需要写入或者更新的数据,因为要存储到数据库,其做法又会有所差异。当对数据库进行大量的写入和更新操作时,将会导致数据库负载过高,严重时将会阻塞整个系统的响应。一个较好的做法是,先将等插入或更新的数据保存在高效缓存队列中,然后通过后台异步计划任务进行消费。计划任务,不仅适用于用户在与系统进行交互而产生的业务数据,同时也适用于系统基于已有数据而分析产生的二代数据。
PhalApi框架已经提供了Task计划任务扩展类库,当需要使用到后台计划任务时,这是一个非常值得尝试的类库。
7.4.2 NoSQL阵容
随着非关系型数据库的兴起,出现了越来越多的NoSQL,形成了一个强大的阵容。常用的有键值对存储型,如Memcache/Memcached,和文档存储型,如MongoDB。
在PhalApi中,封装的缓存有:PhalApi_Cache_Memcache/PhalApi_Cache_Memcached,PhalApi_Cache_Redis,而扩展类库中则有Redis扩展,这些在开发项目都可结合业务的情况,选择使用。
如果需要更强大的NoSQL操作,则可考虑自行封装和延伸。
7.4.3 远程接口的调用
当系统项目还很幼小时,很多事情都是堆积在一起实现的。你可以看到,用户的登录验证,数据库查询,核心基础业务数据的处理,推送功能等都是高度耦合的。随着项目的不断演变以及系统的不断壮大,这些功能会慢慢划分到职责更为明确的模块中,进而渐渐形成一个个相对独立的子系统。从以前直接调用一个类的方法,到调用另外一个子系统的某个接口。再到最后,这些子系统又会独立出来,部署成一个新的系统,肩负着更专注的使命。这时,接口之间的通讯,就从本地通讯变成了分布式的远程通讯。
对于这些接口系统,又可分为两大类,一类是内部系统的接口,另一类是外部第三方开放平台接口。
内部系统接口,是同一个公司或组织内部开发的系统接口,只允许内网内的其他授权系统进行调用。例如内部的推送系统,单点登录系统。第三方开放平台,则很好理解,国外已知的开放平台就有Facebook开放平台、Twitter开放平台API、亚马逊开发者平台等,国内的有微信开放平台、腾讯开放平台、新浪微博开放平台、优酷开放平台等。
不管是与内部系统还是外部第三方开放平台进行对接时,都需要进行远程调用。根据对接的系统,可以有多种调用方式。有些会提供不同语言的SDK开发包,有些则通过curl发起HTTP/HTTPS请求,或者通过socket进行通讯。不管何种方式,在调用远程接口时,应该做好超时设置、重试机制以及日志纪录,保证自身系统的稳定性和可用性。
7.4.4 一切皆文件
在计算机中,对于持久化的存储,其实最终都可归为文件存储。Unix“一切皆文件”这一模型理念,可以说是非常值得借鉴与学习的。在我所参与开发的项目中,就有两个项目就是使用文件进行存储的。至今回想起来,依然让人印象颇为深刻。
其中一个项目是一个对局域网进行流量控制的产品,它有一个运行在特定硬件设备上的管理系统,而在设备之上则是Linux系统。受Unix“一切皆文件”模型的影响,自然而然,底层开发人员在存储数据时也是首选文件,并且只用文件。这不仅遵循了“一切皆文件”理念,而且也为内存和存储空间受限的硬件节省了不必要的开支。
例如,当需要存放各种类型的流量时,它对应的文件数据为:
# $ vim /path/to/net_limit.dat
video 2048 5120
download 0 10240
web 5120 5120
上面数据的意思是,第一列为类型名称,第二列为上行最大流量,第三列为下行最大流量,单位均为KB。例如第一行,在线视频类的上行最大流量为2M,下行最大流量为5M;第二行,下载上行最大流量为0,下行最大流量为10M;第三行,网上冲浪上行和下行的最大流量都是5M。
当需要获取某个类型对应的流量限制时,则可以这样实现:
<?php
class Model_NetLimit {
public function get($type) {
$rs = array();
$shell = 'cat /path/to/net_limit.dat | grep video';
$output = shell_exec($shell);
if (empty($output)) {
return $rs;
}
$arr = explode(' ', trim($output));
$rs['type'] = $arr[0];
$rs['up_limit'] = intval($arr[1]);
$rs['down_limit'] = intval($arr[2]);
return $rs;
}
}
随后,若需要查询视频类的流量限制,则可以:
$model = new Model_NetLimit();
$rs = $model->get('video');
var_dump($rs);
结果会输出:
array(3) {
'type' =>
string(5) "video"
'up_limit' =>
int(2048)
'down_limit' =>
int(5120)
}
使用文件存储的方式简单而实用,结合shell操作,可快速进行相应的查询操作。
7.5 这只个开始
在这一章,我们对大型项目有了更细致的了解。对ADM模式进行剖析后,得到了更清晰的划分和概念模型。
对于Api接口层,“一个接口服务,一个文件”的做法是细分到极致这一理念的体现。通过定制化,可实现更简单的请求形式。接口服务的参数规则配置,可以写成多行,方便查看。接口实现主要分为:定义返回结果字段、初始化并调用领域业务实例、结果赋值与返回这些步骤。在返回给客户端的结果中,除了有业务数据外,通常还会包含业务级别的操作状态码以及提示文案信息。在编写好Api层的代码后,还可以添加相应的注释,以便自动生成在线文档。
在Domain领域业务层中,需要特别区分的三个重要概念是:实体、服务与值对象。实体是具有内部状态、唯一标志并需要与数据仓库进行交互,服务则是无状态、可重复使用的通用功能集合,值对象则是一旦创建后便不可修改。在开发接口服务前,先把待协议的对象按实体、服务和值对象进行划分,会得到一个更加清晰的系统设计。如果发现,实体里有服务,或者服务里有值对象的职责,这时就需要注意,及时进行拆分重构。
PhalApi框架中的Model层与传统Model层最大的不同就是,Model是广义上的数据层,它的数据可以存储在多种媒介,包括但不限于关系型数据库,NoSQL,远程接口系统,文件。根据所存放位置的不同,其实现的方式又会有所不同,需要注意的事项又不相同。例如,对于远程接口的调用,需要设置超时,实现重试机制;对于文件存储,需要约定文件的数据格式。
然而,也正如你所经历的,项目开发中不仅仅是编码、编码只是项目开发中的一个环节。除了编码之外,我们还有很多事情要做,还有很多问题要解决,还有很多领域要涉及。每日构建,单元测试,持续集成,一键发布,线上监控等等,这些都是我们需要面对的。但不管怎样,编写优质的代码是我们迈向出色项目的起点。代码虽小,影响甚大。同时,我们也应意识到,在项目开发过程中,除了编写代码外,还有很多其他事情要做。这,只是个开始。