
在自然语言处理领域中,预训练语言模型(Pre-trained Language Model, PLM)已成为重要的基础技术,在多语言的研究中,预训练模型的使用也愈加普遍。为了促进中国少数民族语言信息处理的研究与发展,哈工大讯飞联合实验室(HFL)发布少数民族语言预训练模型CINO (Chinese mINOrity PLM)。
中文LERT | 中英文PERT | 中文MacBERT | 中文ELECTRA | 中文XLNet | 中文BERT | 知识蒸馏工具TextBrewer | 模型裁剪工具TextPruner
本项工作的主要贡献:
-
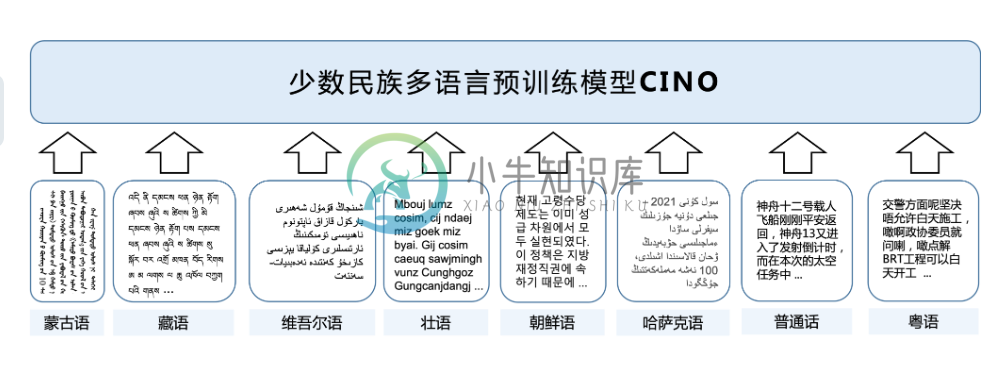
CINO (Chinese mINOrity PLM) 基于多语言预训练模型XLM-R,在多种国内少数民族语言语料上进行了二次预训练。该模型提供了藏语、蒙语(回鹘体)、维吾尔语、哈萨克语(阿拉伯体)、朝鲜语、壮语、粤语等少数民族语言与方言的理解能力。
-
为了便于评价包括CINO在内的各个多语言预训练模型性能,我们构建了基于维基百科的少数民族语言分类任务数据集Wiki-Chinese-Minority(WCM)。具体见少数民族语言分类数据集。
-
通过实验证明,CINO在Wiki-Chinese-Minority(WCM)以及其他少数民族语言数据集:藏语新闻分类 Tibetan News Classification Corpus (TNCC) 、朝鲜语新闻分类 KLUE-TC (YNAT) 上获得了最好的效果。相关结果详见实验结果。
该模型涵盖:
- Chinese,中文(zh)
- Tibetan,藏语(bo)
- Mongolian (Uighur form),蒙语(mn)
- Uyghur,维吾尔语(ug)
- Kazakh (Arabic form),哈萨克语(kk)
- Korean,朝鲜语(ko)
- Zhuang,壮语
- Cantonese,粤语(yue)
-
网速真是够慢的了,本来最近就有好些郁闷的事情,烦的很,。。 cino蓝牙扫描仪 一.连接WINDOWS系统:安装软件(SL-BA10.rar) 打开SumlungScanPC打开文件夹 找到这个程序。 (1)点击setting : 配对的时候会分配一个传出端口 选那个传出的就行 刚刚setting最后一步会提示传入传出端口是多少 如果你没注意 可以在蓝牙设备属性里查看到
-
ASR语言模型在线训练 分词 文本清洗 语言模型目前不支持英文,阿拉伯数字,标点符号以及特殊字符,所以需要将训练文本中英文剔除,阿拉伯数字转换成相应的中文表示,删除标点符号和特殊字符。 文本分词 一般先用结巴或清华分词器分词,再人工矫正,分词的原则是它需要具有独立的实体意义。比如,刘德华, 张学友,这些人名;还有一些地名,张家港,黑龙江等;专有名词,中国,迪士尼等.对于我们需要训练的文本,要保证分
-
我希望使用AWS Sagemaker工作流部署一个预训练的模型,用于实时行人和/或车辆检测,我特别想使用Sagemaker Neo编译模型并将其部署在边缘。我想从他们的模型动物园中使用OpenVino的预构建模型之一,但是当我下载模型时,它已经是他们自己的优化器的中间表示(IR)格式。 > 如果没有,是否有任何免费的预训练模型(使用任何流行的框架,如pytorch,tenorflow,ONXX等)
-
在之前的描述中,我们通常把机器学习模型和训练算法当作黑箱子来处理。如果你实践过前几章的一些示例,你惊奇的发现你可以优化回归系统,改进数字图像的分类器,你甚至可以零基础搭建一个垃圾邮件的分类器,但是你却对它们内部的工作流程一无所知。事实上,许多场合你都不需要知道这些黑箱子的内部有什么,干了什么。 然而,如果你对其内部的工作流程有一定了解的话,当面对一个机器学习任务时候,这些理论可以帮助你快速的找到恰
-
在之前的描述中,我们通常把机器学习模型和训练算法当作黑箱子来处理。如果你实践过前几章的一些示例,你惊奇的发现你可以优化回归系统,改进数字图像的分类器,你甚至可以零基础搭建一个垃圾邮件的分类器,但是你却对它们内部的工作流程一无所知。事实上,许多场合你都不需要知道这些黑箱子的内部有什么,干了什么。 然而,如果你对其内部的工作流程有一定了解的话,当面对一个机器学习任务时候,这些理论可以帮助你快速的找到恰
-
问题内容: 我像这样使用scikit-learn的SVM: 我的问题是,当我使用分类器预测训练集成员的班级时,即使在scikit- learns实现中,分类器也可能是错误的。(例如) 问题答案: 是的,可以运行以下代码,例如: 分数是0.61,因此将近40%的训练数据被错误分类。部分原因是,即使默认内核是(理论上也应该能够对任何训练数据集进行完美分类,只要您没有两个带有不同标签的相同训练点),也可
-
本文向大家介绍Pytorch加载部分预训练模型的参数实例,包括了Pytorch加载部分预训练模型的参数实例的使用技巧和注意事项,需要的朋友参考一下 前言 自从从深度学习框架caffe转到Pytorch之后,感觉Pytorch的优点妙不可言,各种设计简洁,方便研究网络结构修改,容易上手,比TensorFlow的臃肿好多了。对于深度学习的初学者,Pytorch值得推荐。今天主要主要谈谈Pytorch是
-
本文向大家介绍python PyTorch预训练示例,包括了python PyTorch预训练示例的使用技巧和注意事项,需要的朋友参考一下 前言 最近使用PyTorch感觉妙不可言,有种当初使用Keras的快感,而且速度还不慢。各种设计直接简洁,方便研究,比tensorflow的臃肿好多了。今天让我们来谈谈PyTorch的预训练,主要是自己写代码的经验以及论坛PyTorch Forums上的一些回
-
本文向大家介绍Keras使用ImageNet上预训练的模型方式,包括了Keras使用ImageNet上预训练的模型方式的使用技巧和注意事项,需要的朋友参考一下 我就废话不多说了,大家还是直接看代码吧! 在以上代码中,我们首先import各种模型对应的module,然后load模型,并用ImageNet的参数初始化模型的参数。 如果不想使用ImageNet上预训练到的权重初始话模型,可以将各语句的中