
SHAP(SHapley Additive exPlanations)以一种统一的方法来解释任何机器学习模型的输出。 SHAP将博弈论与局部解释联系起来,将以前的几种方法结合起来,并根据预期表示唯一可能的一致且局部准确的加法特征归因方法(详见SHAP NIPS paper 论文)。
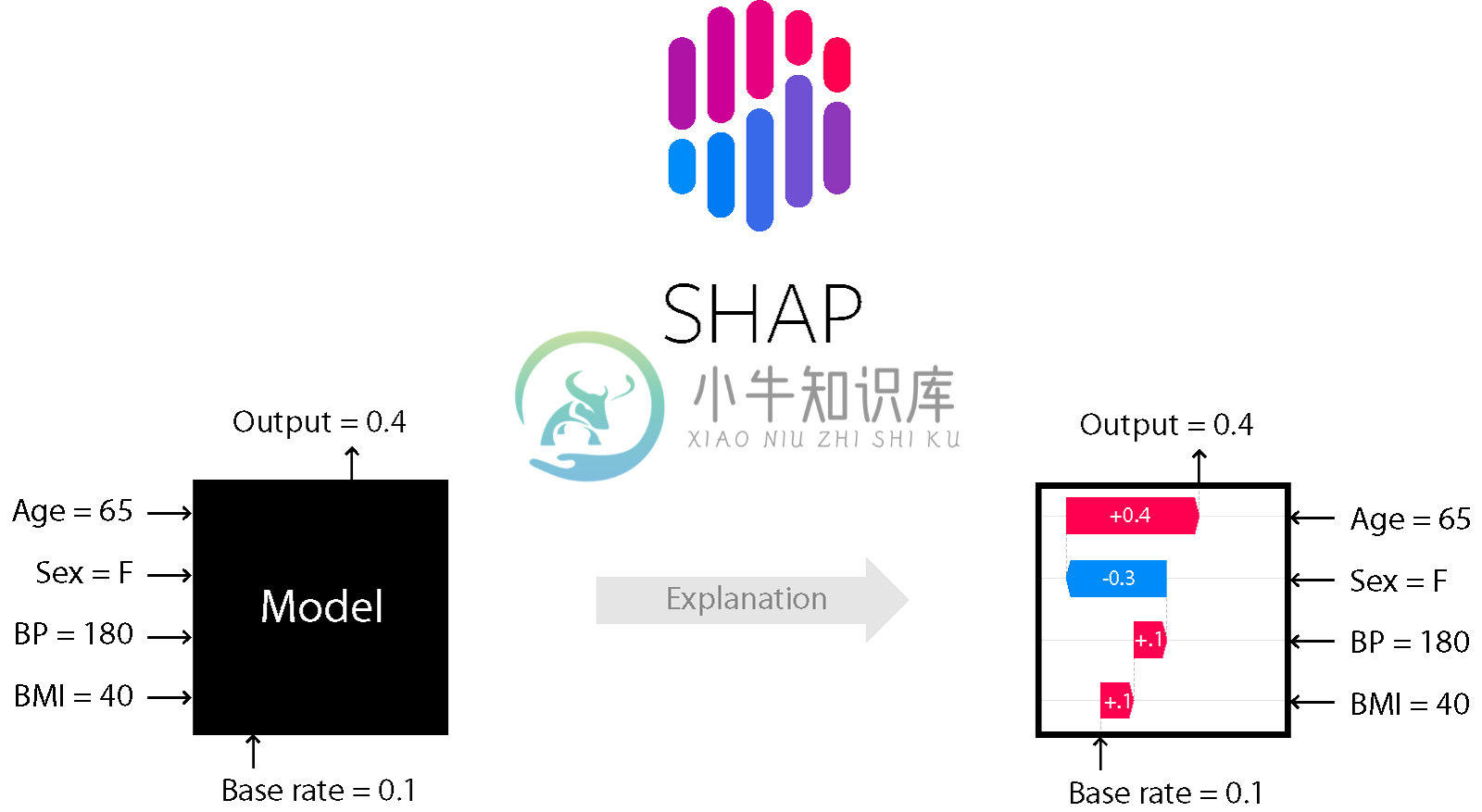
虽然SHAP值可以解释任何机器学习模型的输出,但我们已经开发了一种用于树集合方法的高速精确算法(Tree SHAP arXiv paper)。 XGBoost,LightGBM,CatBoost和scikit-learn树模型支持快速C ++实现:
import xgboost
import shap
# load JS visualization code to notebook
shap.initjs()
# train XGBoost model
X,y = shap.datasets.boston()
model = xgboost.train({"learning_rate": 0.01}, xgboost.DMatrix(X, label=y), 100)
# explain the model's predictions using SHAP values
# (same syntax works for LightGBM, CatBoost, and scikit-learn models)
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
# visualize the first prediction's explanation (use matplotlib=True to avoid Javascript)
shap.force_plot(explainer.expected_value, shap_values[0,:], X.iloc[0,:])
-
SHAP Tutorial 本文主要介绍: SHAP的原理 SHAP的应用方式 SHAP的介绍 SHAP的目标就是通过计算每个样本中每一个特征对prediction的贡献, 来对模型结果做解释。在合作博弈论的启发下SHAP构建一个加性的解释模型,所有的特征都视为“贡献者”。对于每个预测样本,模型都产生一个预测值,SHAP值就是该样本中每个特征所分配到的数值。 设第 i i i个样本为 x i x_
-
XAI之SHAP:SHAP算法(How—每个特征如何重要/解释单个样本的预测)的简介(背景/思想/作用/原理/核心技术点/优缺点)、常用工具库、应用案例之详细攻略 目录 SHAP的简介 0、SHAP算法相关文章 XAI之SHAP:机器学习可解释性之SH
-
本文向大家介绍机器学习:知道哪些传统机器学习模型相关面试题,主要包含被问及机器学习:知道哪些传统机器学习模型时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 常见的机器学习算法: 1).回归算法:回归算法是试图采用对误差的衡量来探索变量之间的关系的一类算法。回归算法是统计机器学习的利器。 常见的回归算法包括:最小二乘法(Ordinary Least Square),逐步式回归(Stepwis
-
当我用Theano或Tensorflow训练我的神经网络时,它们会每历元报告一个叫做“损失”的变量。 我该如何解释这个变量呢?更高的损耗是更好还是更差,或者这对我的神经网络的最终性能(准确性)意味着什么?
-
Python 有着海量的可用于数据分析、统计以及机器学习的库,这使得 Python 成为很多数据科学家所选择的语言。 下面我们列出了一些被广泛使用的机器学习及其他数据科学应用的 Python 包。 Scipy 技术栈 Scipy 技术栈由一大批在数据科学中被广泛使用的核心辅助包构成,可用于统计分析与数据可视化。由于其丰富的功能和简单易用的特性,这一技术栈已经被视作实现大多数数据科学应用的必备品了。
-
主要内容 前言 课程列表 推荐学习路线 数学基础初级 程序语言能力 机器学习课程初级 数学基础中级 机器学习课程中级 推荐书籍列表 机器学习专项领域学习 致谢 前言 我们要求把这些课程的所有Notes,Slides以及作者强烈推荐的论文看懂看明白,并完成所有的老师布置的习题,而推荐的书籍是不做要求的,如果有些书籍是需要看完的,我们会进行额外的说明。 课程列表 课程 机构 参考书 Notes等其他资
-
机器学习与人工智能学习笔记,包括机器学习、深度学习以及常用开源框架(Tensorflow、PyTorch)等。 机器学习算法 _图片来自scikit-learn_。 机器学习全景图 _图片来自http://www.shivonzilis.com/_。
-
机器学习与人工智能学习笔记,包括机器学习、深度学习以及常用开源框架(Tensorflow、PyTorch)等。
-
注: 内容翻译自 data model etcd设计用于可靠存储不频繁更新的数据,并提供可靠的观察查询。etcd暴露键值对的先前版本来支持不昂贵的快速和观察历史事件(“time travel queries”)。对于这些使用场景,持久化,多版本,并发控制的数据模型是非常适合的。 ectd使用多版本持久化键值存储来存储数据。当键值对的值被新的数据替代时,持久化键值存储保存先前版本的键值对。键值存储事
-
“三个臭皮匠顶个诸葛亮”。集成学习就是利用了这样的思想,通过把多分类器组合在一起的方式,构建出一个强分类器;这些被组合的分类器被称为基分类器。事实上,随机森林就属于集成学习的范畴。通常,集成学习具有更强的泛化能力,大量弱分类器的存在降低了分类错误率,也对于数据的噪声有很好的包容性。