
学习Java内存模型JMM心得

有时候编译器、处理器的优化会导致runtime与我们设想的不一样,为此Java对编译器和处理器做了一些限制,JAVA内存模型(JMM)将这些抽象出来,这样编写代码时就无需考虑那么多底层细节,并保证“只要遵循JMM的规则编写程序,其运行结果一定是正确的”。
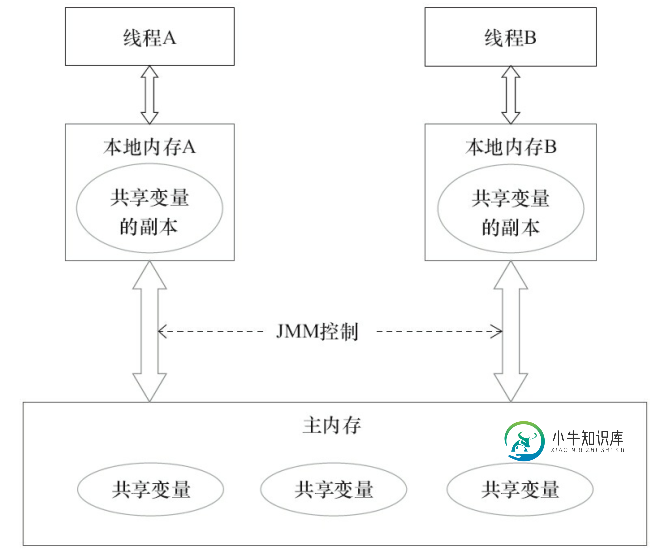
JMM的抽象结构
在Java中,所有的实例、静态变量存储在堆内存中,堆内存是可以在线程间共享的,这部分也称为共享变量。而局部变量、方法定义参数、异常处理参数是在栈中的,栈内存不在线程间共享。
而由于编译器、处理器的优化,会导致共享变量出现可见性问题,像在多核处理器中(multi-processor),线程可以在不同的处理器上执行,而处理器之间缓存不一致,会使共享变量出现可见性问题,有可能两个线程看到同一个变量不同值。
JMM将这些硬件做的优化抽象成每个线程都有一个本地内存。需要读写共享变量时,从主内存中拷贝一份到本地内存。当写共享变量时,先写到本地内存中去,在将来某个时间再刷新到主内存中。当再次读共享变量时,则只会从本地内存中读取。
这样线程间通讯就需要经过两步:
写线程:刷新本地内存到主内存中去读线程:从主内存读取更新后的值
这样在写-读之间就有一个延迟:本地内存什么时候刷新到主内存中去?导致可见性问题,不同线程可能看到的共享变量不一样。
happens-before
从字面上看happens-before的意思是“发生在此之前”。这是java对程序执行顺序制定的规则,实现同步必须遵循该规则。这样程序员只需要写出正确的同步程序,happens-before保证运行结果不会错。
A happens-before B,不仅仅表示A在B之前执行,还意味着A的执行结果对B可见,这保证了可见性。
A happens-before B,A也不一定要在B之前执行,如果AB交替,执行结果任然正确,则允许编译器、处理器进行优化重排序。所以只要程序结果正确,编译器、处理器怎么优化,怎么重排序都没问题,都是好的。
happens-before规则
程序顺序规则:在一个线程中,前面的操作happens-before后面的操作锁规则:对同一个锁,解锁happens-before加锁 volatile域规则:写volatile变量,happens-before后面任意一个读这个volatile变量的操作传递性:A happens-before B,B happens-before C,则A happens-before C start()规则:如果线程A执行ThreadB.start() 那么ThreadB.start() happens-before 线程B中任何操作 join()规则:如果线程A执行ThreadB.join(),那么线程B中的所有操作happens-before ThreadB.join()
下面这个示例有助于理解happens-before
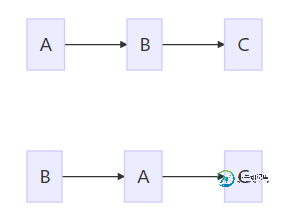
double pi = 3.14; //A double r = 1.0; //B double area = pi * r *r; //C
这里有三个happens-before关系,规则1、2是程序顺序规则,规则3是传递性规则推导出来的:
A happens-before B B happens-before C A happens-before C
C依赖于A、B,但是A和B谁也不依赖。所以即使A和B重排序,执行结果也不会发生变化,这种重排序,JMM是运行的。
下面两种执行顺序的结果都是正确的。
以上就是我们给大家整理的关于Java内存模型JMM学习心得的全部内容,更多问题大家可以在下方留言讨论,感谢你对小牛知识库的支持。
-
本文向大家介绍Java内存模型JMM详解,包括了Java内存模型JMM详解的使用技巧和注意事项,需要的朋友参考一下 Java Memory Model简称JMM, 是一系列的Java虚拟机平台对开发者提供的多线程环境下的内存可见性、是否可以重排序等问题的无关具体平台的统一的保证。(可能在术语上与Java运行时内存分布有歧义,后者指堆、方法区、线程栈等内存区域)。 并发编程有多种风格,除了CSP(通
-
规范了Java虚拟机与计算机内存是如何协调工作的,规定了一个线程如何及何时能看到其他线程修改过的共享变量,在必须时如何同步地访问共享变量,控制线程本地内容和共享内容之间的同步。 2. 同步八种操作 操作 定义 lock(锁定) unlock(解锁) read(读取) load(载入) use(使用) assign(赋值) store(存储) write(写入) 3. 同步规则 Read和Load之
-
决策树(decision tree)是一种基本的分类与回归方法。决策树模型呈树形结构。通常包含3个步骤:特征选择、决策树的生成和决策树的修剪。 决策树模型 分类决策树树模型是一种描述对实例进行分类的树形结构。决策树由节点(node)和有向边(directed edge)组成。节点有两种类型:内部节点(internal node)和叶节点。内部节点表示一个特征或属性,叶节点表示一个类。 用决策树分类
-
使用包含Scala和Akka在内的Typesafe平台的主要好处是它简化了并发软件的编写过程。本文将讨论Typesafe平台,尤其是Akka是如何在并发应用中访问共享内存的。 Java内存模型 在Java 5之前,Java内存模型(JMM)定义是有问题的。当多个线程访问共享内存时很可能得到各种奇怪的结果,例如: 一个线程看不到其它线程所写入的值:可见性问题 由于指令没有按期望的顺序执行,一个线程观
-
本文向大家介绍MySql学习心得之存储过程,包括了MySql学习心得之存储过程的使用技巧和注意事项,需要的朋友参考一下 先来看段mysql查询文章回复语句: #技术点1:MySql5.1不支持LIMIT参数(MySql5.5就支持了),如果编写存储过程时使用LIMIT做变量,那是需要用动态SQL来构建的,而这样做性能肯定没有静态SQL好。主要代码如下: #技术点2:如果同时需要返回受影响行数需要在
-
一、Java内存区域 方法区(公有): 用户存储已被虚拟机加载的类信息,常量,静态常量,即时编译器编译后的代码等数据。异常状态 OutOfMemoryError 其中包含常量池:用户存放编译器生成的各种字面量和符号引用。 堆(公有): 是JVM所管理的内存中最大的一块。唯一目的就是存放实例对象,几乎所有的对象实例都在这里分配。Java堆是垃圾收集器管理的主要区域,因此很多时候也被称为“GC堆”。异