
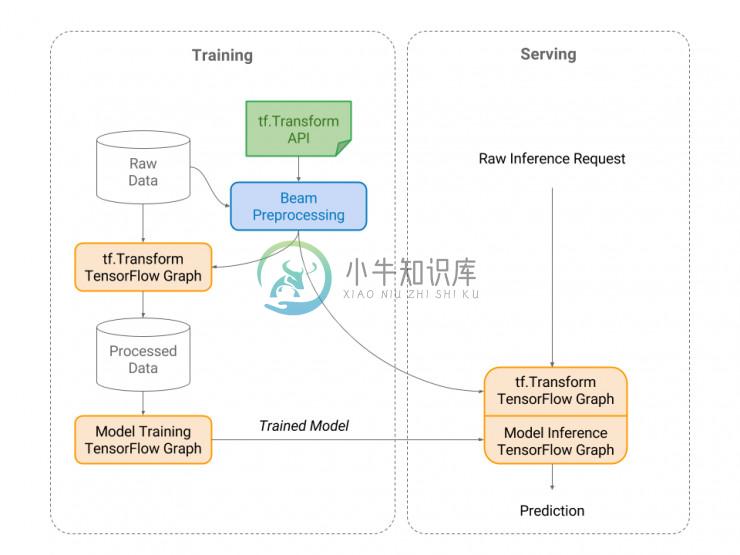
tf.Transform 是一个使用 TensorFlow 进行数据预处理的库。它允许用户结合各种数据处理框架(目前支持 Apache Beam,但是可以扩展 tf.Transform 以支持其他框架),使用 TensorFlow 来转换数据。 因为 tf.Transform 是基于 TensorFlow 构建的,所以它允许用户导出一个计算图(graph),用户随后可以将导出的 TensorFlow 计算图(TensorFlow graph)合并到它们的服务模型中,从而避免服务模型和训练数据之间的偏差。
-
摘自:https://my.oschina.net/u/4288583/blog/3413736 如何使用tf::transform进行简单的不同frame间的pose转换 osc_22to9se2 2019/08/27 15:57 阅读数 315 tf转换,分为两部分:broadcaster和listener。前者是tf的发布者,后者是接收者。我们如果要建立一个完整的tf体系,需要自己先生成tf
-
skimage文档是这样说的 skimage.transform.resize( image , output_shape , order=None , mode=‘reflect’ , cval=0 , clip=True , preserve_range=False , anti_aliasing=None , anti_aliasing_sigma=None ) Performs inter
-
TF介绍(三) tf in python tf中有C++接口,也有Python接口,tf在Python中的具体实现相对比较简单。 数据类型: TF的相关数据类型,向量、点、四元数。矩阵的=都可以表示成类似于数组的形式(Tuple、List、Numpy Array表示)。 如: t = (1.0,1.5,1.0) #平移 q = [1,0,0,0] #四元数 m = numpy.identity(3
-
这今天在生成XML文件和svg文件的时候遇到的问题,现在已经解决了。在网上找了好多方法,终于找到一个可行的,记录一下,防止以后在遇到。 之前的写法(只粘贴部分代码): // 创建TransformerFactory对象 TransformerFactory tff = TransformerFactory.newInstance(); // 创建 Transformer对象
-
在用dataset读取tfrecord的时候,看到别人的代码里面基本都有tf.data.Dataset.map()这个部分,而且前面定义了解析tfrecord的函数decord_example(example)之后,在后面的的map里面直接就dataset.map(decord_example)这样使用,并没有给example赋值。 具体代码在这里: def decode_example(exam
-
一,准备csv文件 import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import sklearn import pandas as pd import os import sys import time import tensorflow as tf from tensorflow import
-
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理解,而且能够帮助新手快速入门。 本文主要介绍了tf第十讲:TFRecord(tf
-
很多东西自己只是查了、用了,但却没有去总结吸收,还是需要一个个的去积累记录 目录 tf.data.TFRecordDataset 含义 Dataset 函数解析 tf.data.Dataset.batch 、map、shuffle、repeat tf.data.Dataset.make_one_shot_iterator().get_next() 一个几乎通用tfrecord 的数据解
-
Stefan答案中的图像中心似乎不正确,下面是他的代码的正确版本from skimage import transform import numpy as np import matplotlib.pyplot as plt image = np.zeros([21, 21]) image[10,:] = 1 image[10,10] = 5 image[7, 10] = 1 shift_y, s
-
最近深度学习用到的数据集比较大,如果一次性将数据集读入内存,那服务器是顶不住的,所以需要分批进行读取,这里就用到了tf.data.Dataset构建数据集,先看一个博文,入入门: https://www.jianshu.com/p/f580f4fc2ba0 概括一下,tf.data.Dataset主要有几个部分最重要: 构建生成器函数 使用tf.data.Dataset的from_generat
-
官方原话: class TextLineDataset(dataset_ops.Dataset): """A `Dataset` comprising lines from one or more text files.""" def __init__(self, filenames, compression_type=None, buffer_size=None):
-
Estimator类代表了一个模型,以及如何对这个模型进行训练和评估, class Estimator(builtins.object) 可以按照下面方式创建一个E def resnet_v1_10_1(features, labels, mode, params): learn
-
原文:https://blog.csdn.net/u014061630/article/details/80728694 导入数据(Reading data) TensorFlow读取数据的四种方法:tf.data、Feeding、QueueRunner、Preloaded data。 本篇的内容主要介绍 tf.data API的使用 目录 导入数据(Reading data) 1. Datas
-
TensorFlow2.0跑1.0代码出现tf.contrib找不到的问题) TensorFlow2.0跑1.0代码出现tf.contrib找不到的问题) tf.contrib在tf2.0已经弃用,换用1.0代码又不太好,可以对模块进行替换 如果是tf.contrib.tpu出现问题,可以将tf.contrib.tpu改成tf.compat.v1.estimator.tpu 其他模块出现问题 可以
-
tensorflow中tf.contrib.image.transform函数可对图像做透视变换,用法如下 #读取图像 img=cv2.imread('/home/xp1/Pictures/004545.jpg') input=tf.placeholder(dtype=np.uint8,shape=[375,500,3]) #高,宽,通道 src_points = np.array([[165
-
不见源码navigation-stack里面的tf_.transform(robot_pose, global_pose, costmap->getGlobalFrameID());很容易让人误解。 实际上这是一个模版类,类中是这样的tf2::doTransform(in, out, lookupTransform(target_frame, tf2::getFrameId(in), tf2::g
-
Data Preparation You must pre-process your raw data before you model your problem. The specific preparation may depend on the data that you have available and the machine learning algorithms you want
-
在输入的JSON数据中,v的值越高,粒子越亮,并且它们从出发国家到目的国家的运行越快。 (请查阅Michael Chang的文章来 了解他是如何提出这个想法的)。Gio.js库会自动缩放输入数据的范围以便于更好的数据可视化。作为开发人员,您还可以定义自己的预处理数据的方式。
-
校验者: @if only 翻译者: @Trembleguy sklearn.preprocessing 包提供了几个常见的实用功能和变换器类型,用来将原始特征向量更改为更适合机器学习模型的形式。 一般来说,机器学习算法受益于数据集的标准化。如果数据集中存在一些离群值,那么稳定的缩放或转换更合适。不同缩放、转换以及归一在一个包含边缘离群值的数据集中的表现在 Compare the effect o
-
本文向大家介绍python数据预处理 :数据共线性处理详解,包括了python数据预处理 :数据共线性处理详解的使用技巧和注意事项,需要的朋友参考一下 何为共线性: 共线性问题指的是输入的自变量之间存在较高的线性相关度。共线性问题会导致回归模型的稳定性和准确性大大降低,另外,过多无关的维度计算也很浪费时间 共线性产生原因: 变量出现共线性的原因: 数据样本不够,导致共线性存在偶然性,这其实反映了缺
-
本文向大家介绍Python----数据预处理代码实例,包括了Python----数据预处理代码实例的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Python数据预处理的具体代码,供大家参考,具体内容如下 1.导入标准库 2.导入数据集 3.缺失数据 4.分类数据 5.将数据集分为训练集和测试集 6.特征缩放 7.数据预处理模板 (1)导入标准库 (2)导入数据集 (3)缺失和分类很
-
本文向大家介绍python数据预处理之数据标准化的几种处理方式,包括了python数据预处理之数据标准化的几种处理方式的使用技巧和注意事项,需要的朋友参考一下 何为标准化: 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同
-
WebGL着色器语言和C语言一样提供了一些用于预处理的命令#define、#include、#if等以#号开头的命令。 宏定义#define 注意宏定义和着色器声明的变量不同,着色器程序执行前需要进行编译处理,着色器程序编译处理之后程序才会在GPU上执行,宏定义主要是在编译处理阶段起作用。比如宏定义#define PI 3.14,PI符号表示圆周率3.14,如果在代码return float f
-
在Webpack中,所有预处理器都需要应用相应的加载器。 vue-loader允许你使用其他Webpack加载器处理Vue组件的一部分。它将从语言块的lang属性自动推断出要使用的正确加载器。 CSS 例如,让我们用SASS编译我们的<style>标签: npm install sass-loader node-sass --save-dev <style lang="sass"> /* 在