
CeresDB 是一款高性能、分布式的云原生时序数据库,采用 Rust 编写。
CeresDB 架构介绍
CeresDB 是一个时序数据库,与经典时序数据库相比,CeresDB 的目标是能够同时处理时序型和分析型两种模式的数据,并提供高效的读写。
在经典的时序数据库中,Tag列(InfluxDB称之为Tag,Prometheus称之为Label)通常会对其生成倒排索引,但在实际使用中,Tag的基数在不同的场景中是不一样的 ———— 在某些场景下,Tag的基数非常高(这种场景下的数据,我们称之为分析型数据),而基于倒排索引的读写要为此付出很高的代价。而另一方面,分析型数据库常用的扫描 + 剪枝方法,可以比较高效地处理这样的分析型数据。
因此 CeresDB 的基本设计理念是采用混合存储格式和相应的查询方法,从而达到能够同时高效处理时序型数据和分析型数据。
下图展示了 CeresDB 单机版本的架构
┌──────────────────────────────────────────┐
│ RPC Layer (HTTP/gRPC/MySQL) │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ SQL Layer │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Parser │ │ Planner │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌───────────────────┐ ┌───────────────────┐
│ Interpreter │ │ Catalog │
└───────────────────┘ └───────────────────┘
┌──────────────────────────────────────────┐
│ Query Engine │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Optimizer │ │ Executor │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ Pluggable Table Engine │
│ ┌────────────────────────────────────┐ │
│ │ Analytic │ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Wal ││ Memtable ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Flush ││ Compaction ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Manifest ││ Object Store ││ │
│ │└────────────────┘└────────────────┘│ │
│ └────────────────────────────────────┘ │
│ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ Another Table Engine │ │
│ └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
└──────────────────────────────────────────┘
性能优化与实验结果
CeresDB 组合使用了列式混合存储、数据分区、剪枝、高效扫描等技术,解决海量时间线(high cardinality)下写入查询性能变差的问题。
写入优化
CeresDB 采用类 LSM(Log-structured merge-tree)写入模型,无需在写入时处理复杂的倒排索引,因此写入性能上较好。
查询优化
主要采用以下技术手段提高查询性能:
剪枝:
-
min/max 剪枝:构建代价比较低,在特定场景,性能较好
-
XOR 过滤器:提高对 parquet 文件中的 row group 的筛选精度
高效扫描:
-
多个 SST 间并发:同时扫描多个 SST 文件
-
单个 SST 内部并发:支持 Parquet 层并行拉取多个 row group
-
合并小 IO:针对 OSS 上的文件,合并小 IO 请求,提高拉取效率
-
本地 cache:缓存 OSS 拉取文件,支持内存和磁盘缓存
性能测试结果
采用 TSBS 进行性能测试。压测参数如下:
-
10 个 Tag
-
10 个 Field
-
时间线(Tags 组合数)100w 量级
压测机器配置:24c90g
InfluxDB 版本:1.8.5
CeresDB 版本:1.0.0
写入性能对比
InfluxDB 写入性能随着时间下降较多。CeresDB 在写入稳定后,写入速率趋于平稳,并且总体写入性能表现为 InfluxDB 的 1.5 倍以上(一段时间后可达 2 倍以上差距)
下图中,单行 row 包含 10 个 Field。
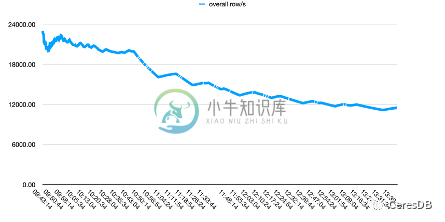
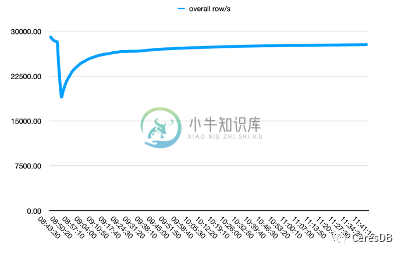
上图为 Influxdb,下图为 CeresDB
查询性能对比
低筛选度条件(条件:os=Ubuntu15.10),CeresDB 比 InfluxDB 快 26 倍,具体数据如下:
-
CeresDB 查询耗时:15s
-
InfluxDB 查询耗时:6m43s
高筛选度条件(命中的数据较少,条件:hostname=[8 个],此时理论上传统倒排索引会更有效),这是 InfluxDB 更有优势的场景,此时在预热完成条件下,CeresDB 比 InfluxDB 慢 5 倍。
-
CeresDB:85ms
-
InfluxDB:15ms
快速开始
获取代码
通过 git 克隆代码仓库并进入代码目录:
git clone git@github.com:CeresDB/ceresdb.git
cd ceresdb
通过 Docker 运行
确保开发环境安装了 docker,通过仓库中的提供的 Dockerfile 进行镜像的构建:
docker build -t ceresdb .
使用编译好的镜像,启动服务:
docker run -d -t --name ceresdb -p 5440:5440 -p 8831:8831 ceresdb
通过源码编译运行
安装依赖
目前为了编译 CeresDB,需要安装相关依赖,以及 Rust 工具链。
开发依赖(Ubuntu20.04)
开发环境这里以 Ubuntu20.04 为例,执行如下的命令,即可安装好所需的依赖:
apt install git curl gcc g++ libssl-dev pkg-config cmake
需要注意的是,项目的编译对 cmake、gcc、g++ 等实际上都是有版本要求的,如果开发环境使用的是较老的 Linux 发行版的话,一般需要手动安装较高版本的这些依赖。
Rust
Rust 的安装建议通过 rustup,安装了 rustup 之后,进入到 CeresDB 项目的时候,会自动根据 rust-toolchain 文件下载指定的 Rust 版本。
理论上执行了之后,需要添加环境变量,才能使用 Rust 工具链,一般会把下面的命令放入到自己的 ~/.bashrc 或者 ~/.bash_profile 中:
source $HOME/.cargo/env
编译和运行
编译 Release 版本,执行如下命令:
cargo build --release
使用下载的代码中提供的默认配置文件,即可启动:
./target/ceresdb-server --config ./docs/example.toml
进行数据读写
CeresDB 支持自定义扩展的 SQL 协议,目前可以通过 http 服务以 SQL 语句进行数据的读写、表的创建。
建表
curl --location --request POST 'http://127.0.0.1:5440/sql' \ --header 'Content-Type: application/json' \ --data-raw '{ "query": "CREATE TABLE `demo` (`name` string TAG, `value` double NOT NULL, `t` timestamp NOT NULL, TIMESTAMP KEY(t)) ENGINE=Analytic with (enable_ttl='\''false'\'')" }'
插入数据
curl --location --request POST 'http://127.0.0.1:5440/sql' \ --header 'Content-Type: application/json' \ --data-raw '{ "query": "INSERT INTO demo(t, name, value) VALUES(1651737067000, '\''ceresdb'\'', 100)" }'
查询数据
curl --location --request POST 'http://127.0.0.1:5440/sql' \ --header 'Content-Type: application/json' \ --data-raw '{ "query": "select * from demo" }'
查看建表信息
curl --location --request POST 'http://127.0.0.1:5440/sql' \ --header 'Content-Type: application/json' \ --data-raw '{ "query": "show create table demo" }'
删除表
curl --location --request POST 'http://127.0.0.1:5440/sql' \ --header 'Content-Type: application/json' \ --data-raw '{ "query": "DROP TABLE demo" }'
-
CeresDB 是一款高性能、分布式的云原生时序数据库,采用 Rust 编写。 CeresDB 架构介绍 CeresDB 是一个时序数据库,与经典时序数据库相比,CeresDB 的目标是能够同时处理时序型和分析型两种模式的数据,并提供高效的读写。 在经典的时序数据库中,Tag列(InfluxDB称之为Tag,Prometheus称之为Label)通常会对其生成倒排索引,但在实际使用中,Tag的基数
-
问题内容: 我需要一些想法来实现Java的(真正)高性能内存数据库/存储机制。在存储20,000+个Java对象的范围内,每5秒钟左右更新一次。 我愿意接受的一些选择: 纯JDBC /数据库组合 JDO JPA / ORM /数据库组合 对象数据库 其他存储机制 我最好的选择是什么?你有什么经验? 编辑:我还需要能够查询这些对象 问题答案: 您可以尝试使用Prevayler之类的工具(基本上是一个
-
我们正在快速开发一个应用程序,其中我们需要一次获取超过50K行(在应用程序加载时执行),然后数据将用于应用程序的其他部分进行进一步计算。我们正在使用Firebase实时数据库,我们面临一些严重的性能问题。 它目前需要大约40秒才能加载50K行(目前使用的是免费数据库版本,不确定这是否是原因),但我们也观察到,当多个用户使用该应用程序时,加载50K行开始需要大约1分20秒,Peak达到100%。 您
-
云原生是一种应用开发风格,鼓励在持续交付和价值驱动开发领域轻松采用最佳实践。相关的学科是建立12-factor Apps,其中开发实践与交付和运营目标相一致,例如通过使用声明式编程和管理和监控。Spring Cloud以多种具体方式促进这些开发风格,起点是一组功能,分布式系统中的所有组件都需要或需要时轻松访问。 许多这些功能都由Spring Boot覆盖,我们在Spring Cloud中建立。更多
-
问题内容: 我在公司中多次设计数据库。为了提高数据库的性能,我只寻找标准化和索引。 如果要求您提高数据库的性能,该数据库包含大约250个表以及一些具有数百万个记录的表,那么您将寻找什么不同的东西? 提前致谢。 问题答案: 优化逻辑设计 逻辑级别是关于查询和表本身的结构。首先尝试最大程度地发挥这一作用。目标是在逻辑级别上访问尽可能少的数据。 拥有最高效的SQL查询 设计支持应用程序需求的逻辑架构(例
-
我试图用Cloud Dataflow(Beam Python SDK)将它读写到BigQuery。 读写2000万条记录(约80 MBs)几乎需要30分钟。 查看dataflow DAG,我可以看到将每个CSV行转换为BQ行花费了大部分时间。
-
本文向大家介绍kafka高性能原因是什么?相关面试题,主要包含被问及kafka高性能原因是什么?时的应答技巧和注意事项,需要的朋友参考一下 零拷贝、利用操作系统页缓存、磁盘顺序写 kafka零拷贝原理 分区、分段、建立索引 生产者、消费者批处理
-
我有一个firebase云函数(http请求),我想在其中更新firestore数据库中的文档 函数正在部署,正确,但每当我调用它不再打印任何内容。评论该部分打印“promise已解决”,我觉得我无法访问或使用错误的语法访问Firestore db,但我不明白为什么? Firebase日志正在打印: 函数执行开始 tr_。。。。。。。。(id) db调用前测试 函数执行耗时1103毫秒,完成状态代
-
楼主研一,但是误投了暑期实习,所以顺便就面了 1.在滴滴工作做的内容 2.做短视频后端的背景是什么?为什么要做? 3.这个项目做了哪些东西? 4.关注的表是怎么设计的?关注和被关注者关系存储在一行么?存储在一行又什么问题?不存在一行又有什么问题?(没搞懂什么意思)(回答的不好) 5.项目中rabbitmq用在哪些场景?(关注和点赞) 6.rabbitmq的架构说一下 7.rabbitmq是否有消息