
TimescaleDB 是基于 PostgreSQL 数据库开发的一款时序数据库,以插件化的形式打包提供,随着 PostgreSQL 的版本升级而升级,不会因为另立分支带来麻烦。
TimescaleDB 架构
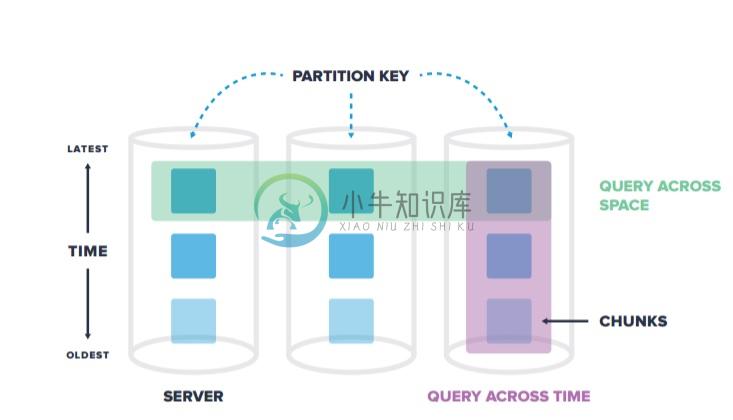
数据自动按时间和空间分片(chunk)
TimescaleDB 具有以下特点
1. 基于时序优化
2. 自动分片(自动按时间、空间分片(chunk))
3. 全 SQL 接口
4. 支持垂直于横向扩展
5. 支持时间维度、空间维度自动分区。空间维度指属性字段(例如传感器 ID,用户 ID 等)
6. 支持多个 SERVER,多个 CHUNK 的并行查询。分区在 TimescaleDB 中被称为 chunk。
7. 自动调整 CHUNK 的大小
8. 内部写优化(批量提交、内存索引、事务支持、数据倒灌)。
内存索引,因为 chunk size 比较适中,所以索引基本上都不会被交换出去,写性能比较好。
数据倒灌,因为有些传感器的数据可能写入延迟,导致需要写以前的 chunk,timescaleDB 允许这样的事情发生(可配置)。
9. 复杂查询优化(根据查询条件自动选择 chunk,最近值获取优化(最小化的扫描,类似递归收敛),limit 子句 pushdown 到不同的 server,chunks,并行的聚合操作)
10. 利用已有的 PostgreSQL 特性(支持 GIS,JOIN 等),方便的管理(流复制、PITR)
11. 支持自动的按时间保留策略(自动删除过旧数据)
示例代码
Creating a hypertable
-- We start by creating a regular SQL table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);
-- Then we convert it into a hypertable that is partitioned by time
SELECT create_hypertable('conditions', 'time');-
介绍 TimescaleDB在许多方面的行为都类似于标准PostgreSQL数据库。如下: 与PostgreSQL服务器上的其他TimescaleDB和PostgreSQL数据库共存。 使用SQL作为其接口语言。包含标准数据库对象,例如表,索引和触发器。 使用通用的PostgreSQL连接器连接第三方工具。 数据库实现这种同步的方式是通过将其打包为PostgreSQL扩展,从而将标准Postgre
-
时序数据库操作 创建时序数据库hypertable 1、创建一个标准表(PostgreSQL docs)。 CREATE TABLE conditions ( time TIMESTAMPTZ NOT NULL, location TEXT NOT NULL, temperature DOUBLE PRECISION NULL );
-
随笔 笔记 TimescaleDB l 什么是TimescaleDB? TimescaleDB是唯一支持完整SQL的开放源代码时间序列数据库。为快速摄取和复杂查询优化,TimescaleDB易于使用,如传统的关系数据库,但按以前为NoSQL数据库保留的方式进行缩放。特别是,这使得TimescaleDB是操作分析的理想候选者。TimescaleDB是在Apache 2许可证下分发的。 l 为什么要创
-
1、时序数据库分析 - TimescaleDB时序数据库介绍 2、时序数据库-Timescale 在Windows上的安装 3、TimescaleDB的结构初识 4、TimescaleDB数据库的介绍 5、TimescaleDB数据库 6、PostGIS 入门 7、Hypertable Basics 超表基础 8、TimescaleDB Overview TimescaleDB 概述 9、What
-
时序数据库操作 创建时序数据库hypertable 1、创建一个标准表(PostgreSQL docs)。 CREATE TABLE data ( ts tsSTAMPTZ NOT NULL, point TEXT NOT NULL, value DOUBLE PRECISION NULL ); 2.转换为hypertab
-
官网:https://www.zabbix.com/documentation/current/zh/manual/appendix/install/timescaledb TimescaleDB 配置 概述 Zabbix支持TimescaleDB,这是一种基于PostgreSQL的数据库解决方案,可自动将数据分为基于时间的块,以支持更快的大规模性能。 目前,Zabbix代理不支持 Timesca
-
1、准备 操作系统: CentOS 7 64位操作系统 安装程序: postgresql-10.2.tar.gz Timescale: timescaledb(只支持pgsql9.x和10.x) Timescale release_tag: 1.0.0 cmake: cmake-3.10.2.tar(Timescale要求CMake 3.4或更高版本) 安装TimescaleDB时序数据库需要提前
-
关于超表 超表(hypertable)是具有特殊功能的PostgreSQL表,可以很容易地处理时间序列数据。与它们交互就像与普通PostgreSQL表交互一样,但在幕后,超表会自动按时间将数据划分为块。 在TimescaleDB中,超表与普通PostgreSQL表可以一起存在。超表用来存储时序数据,这样可以提高插入和查询的性能,而且可以访问一些有用的时间序列特性。普通PostgreSQL表用来存储
-
寻找TimeScaleDB镜像 Docker Hub 查找官方镜像 下载TimeScaleDB镜像 下载最新版TimeScaleDB镜像 docker pull timescale/timescaledb-ha:pg14-latest 检查当前所有Docker下载的镜像 docker images 创建文件 存储数据库文件的目录( /data/docker/postgres/pgdata/da
-
一些时序数据库: [时序]TimescaleDB, 基于 PostgreSQL, 支持 SQL. [时序]KairosDB, 基于 Cassandra, 不支持 SQL. [通用]CrateDB, 基于 Elastic Search, 但支持ANSI SQL [时序]InfluxDB, 是 db-engines 上排名第一的时序数据库, 最新版中集群功能不开源了, 商业版支持, 另外并发查询性能
-
本文向大家介绍postgresql 数据库 与TimescaleDB 时序库 join 在一起,包括了postgresql 数据库 与TimescaleDB 时序库 join 在一起的使用技巧和注意事项,需要的朋友参考一下 之前在CSDN阅读资料时,发现有人问怎么把 postgresql数据库 的表 跟TimescaleDB 时序库的表 join在一起,正好我在查询数据的时候遇到过这个问题 ,我说
-
本文向大家介绍postgresql数据库 timescaledb 时序库 把大数据量表转换为超表的问题,包括了postgresql数据库 timescaledb 时序库 把大数据量表转换为超表的问题的使用技巧和注意事项,需要的朋友参考一下 前言 这几天工作的时候发现在 timescaledb 时序库 中有部分大数据量的表不是超表,估计是当时建库的时候没有改 影响插入,查询效率 ,因此需要改成超表
-
本文向大家介绍开源数据库,包括了开源数据库的使用技巧和注意事项,需要的朋友参考一下 开源数据库是具有开源代码的数据库,即任何人都可以查看,研究甚至修改代码。开源数据库可以是关系(SQL)或非关系(NoSQL)。 为什么要使用开源数据库? 为任何公司创建和维护数据库都非常昂贵。在软件总支出中,很大一部分用于处理数据库。因此,切换到低成本开源数据库是可行的。从长远来看,这可以为公司节省很多钱。 使用中
-
本文向大家介绍MongoDB开源数据库开发工具dbKoda,包括了MongoDB开源数据库开发工具dbKoda的使用技巧和注意事项,需要的朋友参考一下 Southbank Software公司最近发布了 dbKoda 0.6.0 ,这是该软件的 首个发布版 。dbKoda是一款开源的 MongoDB 开发工具,采用JavaScript、 React 和 Electron 开发。下图显示了dbKod
-
主要内容:1.开源OLAP综述,2.开源数仓解决方案1.开源OLAP综述 如今的开源数据引擎多种多样,不同种类的引擎满足了我们不同的需求。现在ROLAP计算存储一体的数据仓库主要有三种,即StarRocks(DorisDB),ClickHouse和Apache Doris。应用最广的数据查询系统主要有Druid,Kylin和HBase。MPP引擎主要有Trino,PrestoDB和Impala。这些引擎在行业内有着广泛的应用。 在云资源层,主要有E
-
如 动态 Inventory 所介绍,ansible可以从一个动态的数据源获取到inventory信息,包含云端数据源 怎么写一个自己的数据源? 很简单!我们仅仅需要创建一个在适当参数下,能够返回正确JSON格式数据的脚本或者程序,你可以使用任何语言来实现. 脚本规范 当我们在外部使用``–list``参数调用这个脚本时,这个脚本必须返回一个JSON散列/字典,它包含所管理的所有组.每个组的val