
LinDB 是一个开源时间序列数据库,提供高性能,高可用性和水平可扩展性。
LinDB 存储饿了吗公司的所有监控数据,每天有 88TB 增量写入和 2.7PB 总原始数据。
高性能
LinDB 采用了很多 TSDB 的最佳实践,并根据时间序列数据的特征实现了一些优化。与为 InfluxDB 编写大量 Continuous-Query 不同,LinDB 在创建数据库后会自动支持特定时间间隔的汇总。此外,LinDB 对于分布式时间序列数据的并行查询和计算来说非常快。
多活动 IDC
LinDB 旨在在多活动 IDC 云架构下运行。 LinDB 的计算层(称为代理)支持高效的 Multi-IDC 聚合查询。
高可用性
LinDB 使用 ETCD 集群来确保元数据高度可用且安全存储。如果发生故障,WAL 的多通道复制协议将避免数据不一致的问题:
1)。每个复制通道中只有一个人负责数据的权限,因此不会发生冲突;
2)。数据可靠性得到保证:只要未在旧的领导者中复制的数据没有丢失,它就会被复制到其他复制,而旧的领导者再次在线;
水平可扩展性
LinDB 中基于标签的分片策略解决了热点问题,只需添加新的代理和存储节点即可实现水平扩展。
指标的治理能力
为了确保系统的健壮性,LinDB 不假设用户已经理解使用度量的最佳实践,因此,LinDB 提供了基于度量标准粒度和标记粒度来限制不友好用户的能力。
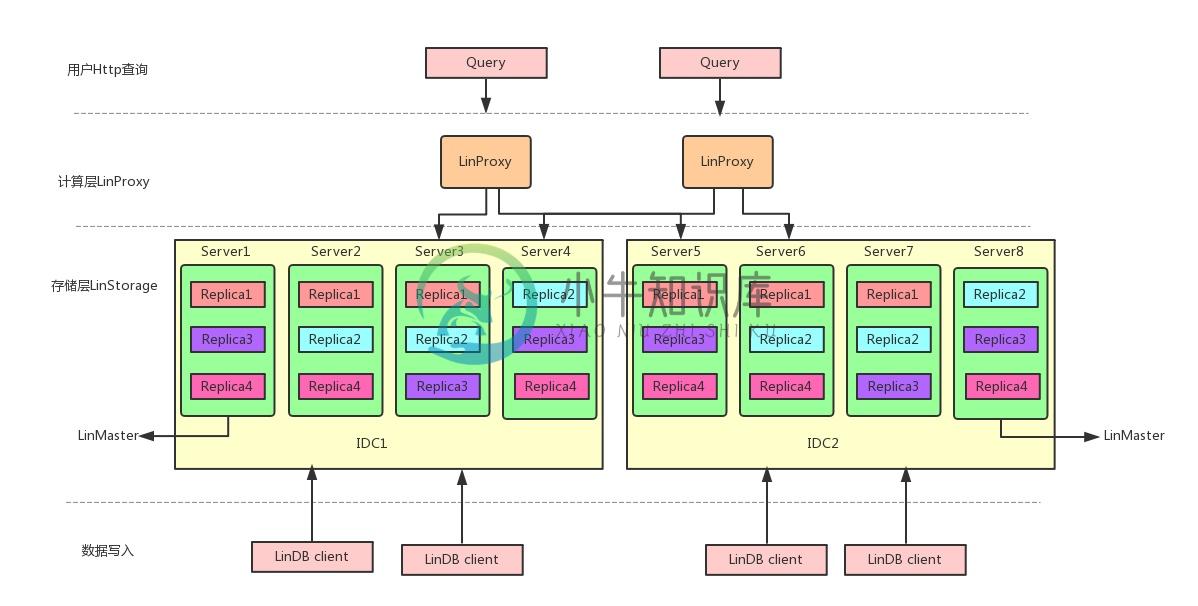
LinDB 架构
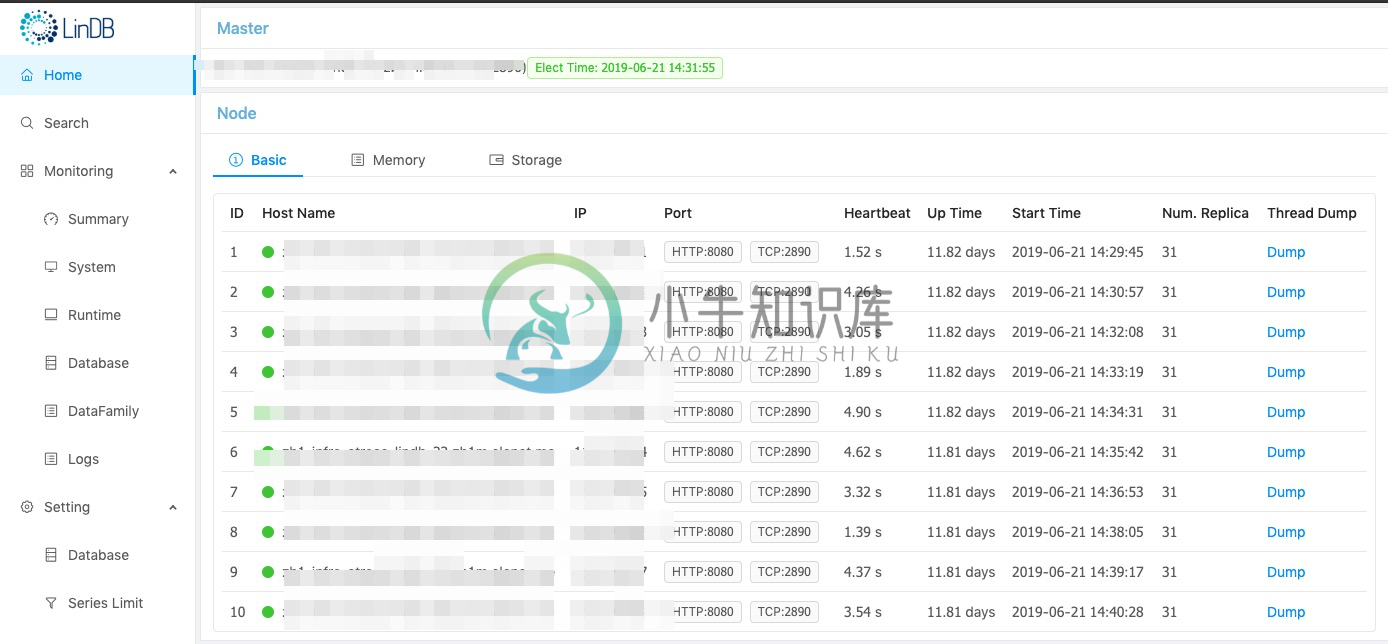
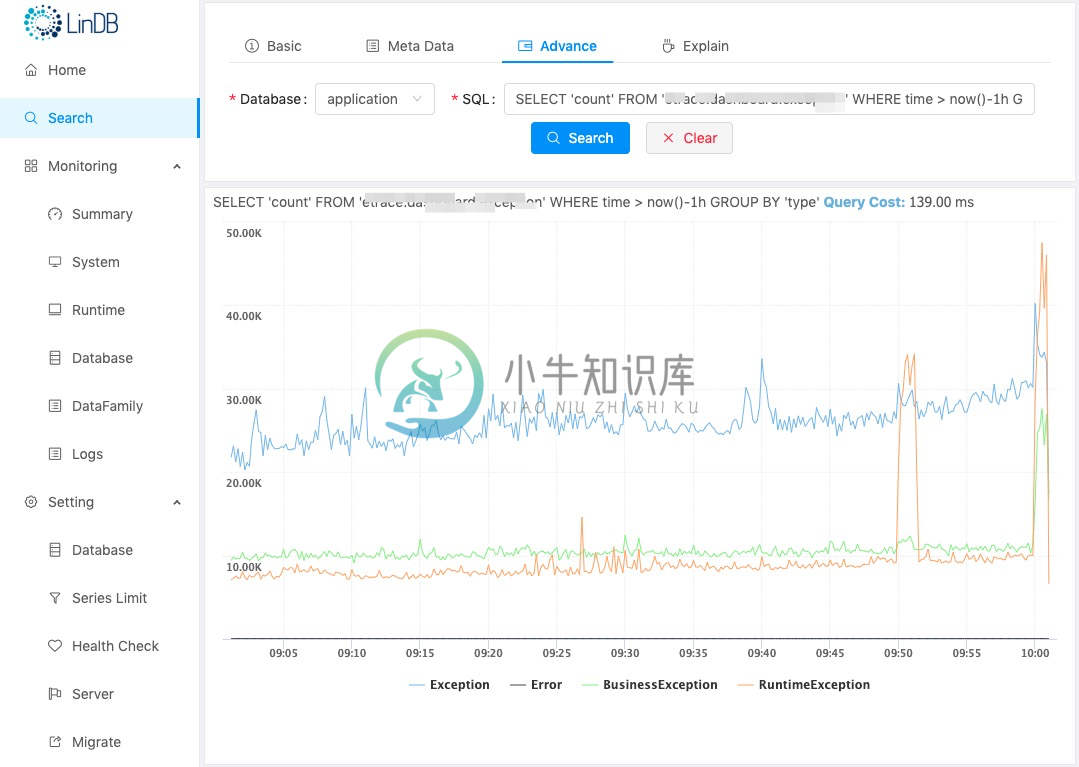
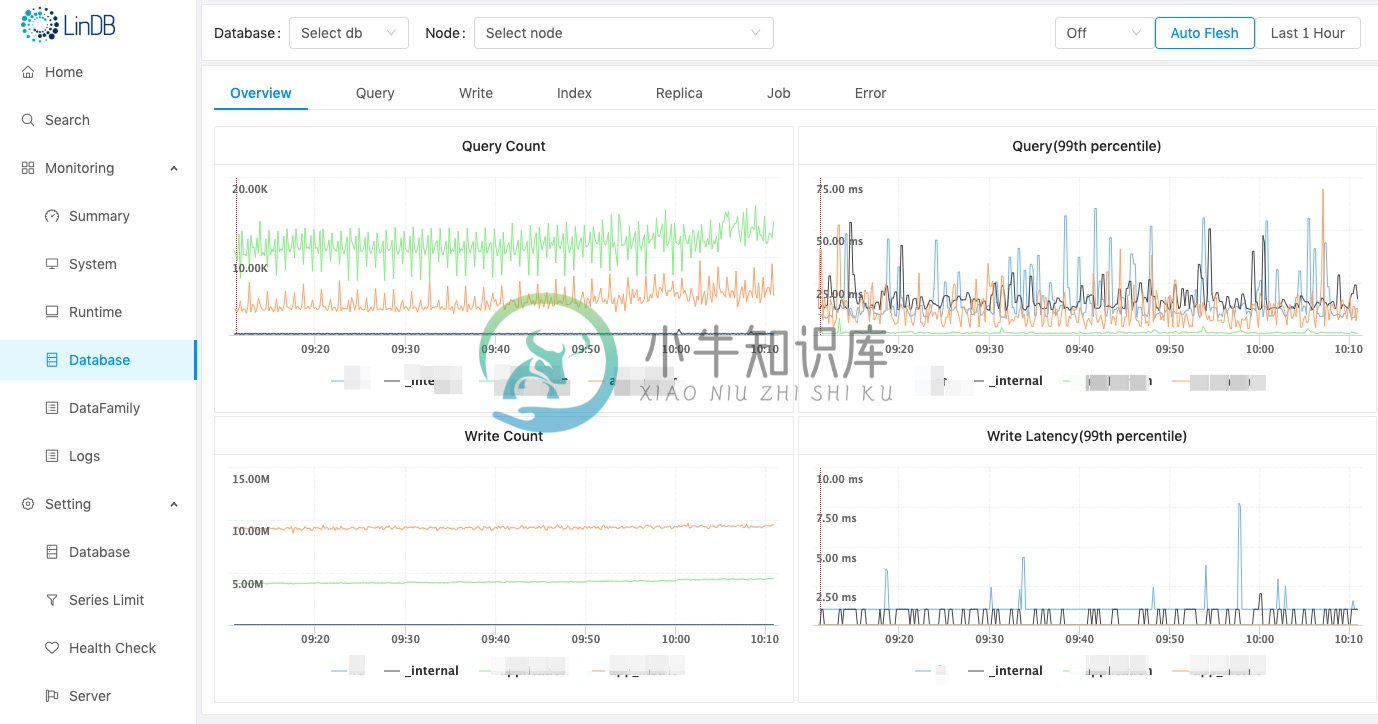
界面截图:
-
database-shard-replica(leader,follower) 计算和存储分离 查询 http-linproxy(sql解析,生成执行计划,多机查询下发,多机结果聚合,linclient具体查询)-linstorage(内部查询和计算出中间结果) 写入 linclient-linstorage linMaster 主控节点(shard,replica的分配,各linstorage的
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
一个成功的技术,现实的优先级必须高于公关,你可以糊弄别人,但糊弄不了自然规律。 ——罗杰斯委员会报告(1986) 在本书的第一部分中,我们讨论了数据系统的各个方面,但仅限于数据存储在单台机器上的情况。现在我们到了第二部分,进入更高的层次,并提出一个问题:如果多台机器参与数据的存储和检索,会发生什么? 你可能会出于各种各样的原因,希望将数据库分布到多台机器上: 可扩展性 如果你的数据量、读取负载、写
-
这里我的疑问是,如果我使用多个分布式数据库,cam如何在配置(application.properties)中提到不同的DB源URL?目前我正在使用以下结构来使用一个数据库, 就像上面那样。 所以,如果我使用多个DB用于多个区域,我如何在这里给出有条件的配置?我是微服务世界和分布式数据库设计模式的新手。
-
我将hazelcast服务器分布在多个节点上。我假设hazelcast将在集群中分发任何IMap数据,这样每个节点都将拥有属于映射的数据。这是建立集群后默认情况下应该发生的事情,还是需要在hazelcast.xml中设置代码或配置?
-
雪花算法 类型:SNOWFLAKE 可配置属性: 属性名称 数据类型 说明 默认值 worker-id (?) long 工作机器唯一标识 0 max-vibration-offset (?) int 最大抖动上限值,范围[0, 4096)。注:若使用此算法生成值作分片值,建议配置此属性。此算法在不同毫秒内所生成的 key 取模 2^n (2^n一般为分库或分表数) 之后结果总为 0 或 1。为防
-
本文向大家介绍NoSQL数据库的分布式算法详解,包括了NoSQL数据库的分布式算法详解的使用技巧和注意事项,需要的朋友参考一下 今天,我们将研究一些分布式策略,比如故障检测中的复制,这些策略用黑体字标出,被分为三段: 数据一致性。NoSQL需要在分布式系统的一致性,容错性和性能,低延迟及高可用之间作出权衡,一般来说,数据一致性是一个必选项,所以这一节主要是关于 数据复制 和 数据恢复 。 数据放置