
QuestDB 是用于时间序列数据的高性能开源 SQL 数据库。它使用面向列的方法、大量并行向量化执行、SIMD 指令以及一系列低延迟技术。整个代码库是从头开始构建的,没有依赖关系,并且 100% 没有垃圾回收。QuestDB 实现了SQL,并使用本地扩展对其进行了时间序列扩展。
它公开了 PostgreSQL 有线协议、高性能 REST API,并支持InfluxDB Line Protocol 的提取。QuestDB 使用具有免维护方案的关系模型。关系和时间序列联接使随时间推移的数据关联变得容易。写入会持久地提交到磁盘,这意味着数据是安全的,但可以立即访问。

性能表现
- 每个线程每秒的操作数。写入是持久的,并已写入磁盘。在具有 6 个内存通道的 CPU 上,QuestDB 可以每秒扫描 117GB 的数据
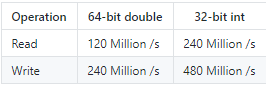
- 使用 96 个可用线程中的 16个 在 c5.metal 实例上的执行时间
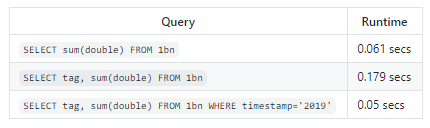
-
QuestDB在Docker Hub上有Linux/macOS和Windows的镜像。 安装Docker 在我们开始之前,您需要安装Docker。您可以在官方文档中找到有关平台的指南。 QuestDB镜像 一旦安装了Docker,你需要从Docker Hub中提取QuestDB的镜像并创建一个容器。你可以使用docker run在一个命令中完成这两个操作: docker run -p 9000:9
-
如今随着云计算、物联网、以及机器学习对于时序数据需求的持续爆炸式增长,软件架构师们应该如何选择时序数据库呢?本文将综合比较市场上最为流行的三种TSDB–InfluxDB,TimescaleDB和QuestDB,以帮助您做出明智的选择。 【51CTO.com快译】在过去的十年间,我们亲历了关系型、非关系型、在线分析处理(OLAP)型、以及在线事务处理(OLTP)型数据库的市场之争,也注意到了诸如:S
-
这个页面描述了如何通过二进制文件安装和使用QuestDB。QuestDB提供了一个用于Linux/FreeBSD的脚本 questdb.sh 和一个用于Windows的可执行的questdb.exe。如果您正在寻找macOS,请检查我们的自制软件部分。 下载 您可以在Get QuestDB页面上找到最新的二进制文件。发布说明在我们的GitHub发布页面。 前期准备 “Any (no JVM)”版本
-
What is new ? Migrated to Java 11 (#272). Fixed #154 SQL: vectorized group by hour(timestamp) (#398) SQL: cancel active read-only queries on client disconnect; added resource constraints (#396) SQL: v
-
由于使用官网jdbc示例无法进行数据插入,可能问题为使用try with resource写法造成,具体原因未知。 改后示例: public static void main(String[] args) throws Exception{ Properties properties = new Properties(); properties.setProperty("user"
-
Apache Kafka 是一个经过实战考验的分布式流处理平台,在金融行业中很受欢迎,用于处理任务关键型事务工作负载。Kafka 处理大量实时市场数据的能力使其成为交易、风险管理和欺诈检测的核心基础设施组件。金融机构使用 Kafka 从市场数据源、交易数据和其他外部来源流式传输数据,以推动决策。 用于摄取和存储财务数据的常见数据管道涉及将实时数据发布到 Kafka,并利用 Kafka Connec
-
我正在尝试将数据迁移到 QuestDB 并插入历史记录,我将表创建为 create table records( type INT, interval INT, timestamp TIMESTAMP, name STRING) timestamp(timestamp) 并通过JDBC 插入数据。 一、问题详情 我收到错误“无法乱序插入行”。我读到 QuestDB 支持乱序,但不知何故我无法让它
-
最近被 questDB刷屏了, 就想着git源码调试下, 录了个视频,放到了B站, 需要一些知识 1. git的使用与github的使用 2. java的使用 3.使用idea调试 4.视频里面零碎的东西, 具体看视频吧 有硬币的投个币吧 【questDB源码下载调试-哔哩哔哩】 https://b23.tv/Ae71tQE
-
#拉取镜像 docker pull questdb/questdb #后台运行 docker run -d -p 9000:9000 questdb/questdb
-
问题内容: 我需要一些想法来实现Java的(真正)高性能内存数据库/存储机制。在存储20,000+个Java对象的范围内,每5秒钟左右更新一次。 我愿意接受的一些选择: 纯JDBC /数据库组合 JDO JPA / ORM /数据库组合 对象数据库 其他存储机制 我最好的选择是什么?你有什么经验? 编辑:我还需要能够查询这些对象 问题答案: 您可以尝试使用Prevayler之类的工具(基本上是一个
-
我们正在快速开发一个应用程序,其中我们需要一次获取超过50K行(在应用程序加载时执行),然后数据将用于应用程序的其他部分进行进一步计算。我们正在使用Firebase实时数据库,我们面临一些严重的性能问题。 它目前需要大约40秒才能加载50K行(目前使用的是免费数据库版本,不确定这是否是原因),但我们也观察到,当多个用户使用该应用程序时,加载50K行开始需要大约1分20秒,Peak达到100%。 您
-
问题内容: 我在公司中多次设计数据库。为了提高数据库的性能,我只寻找标准化和索引。 如果要求您提高数据库的性能,该数据库包含大约250个表以及一些具有数百万个记录的表,那么您将寻找什么不同的东西? 提前致谢。 问题答案: 优化逻辑设计 逻辑级别是关于查询和表本身的结构。首先尝试最大程度地发挥这一作用。目标是在逻辑级别上访问尽可能少的数据。 拥有最高效的SQL查询 设计支持应用程序需求的逻辑架构(例
-
Kdb+ 是来自 Kx Systems Inc 的高性能列式数据库。 kdb+ 旨在捕获,分析,比较和存储数据 - 所有这些都是高速和大量数据。
-
主要内容:一般业务系统运行流程图,一台 4 核 8G 的机器能扛多少并发量呢?,高并发来袭时数据库会先被打死吗?,8 核 16G 的数据库每秒大概可以抗多少并发压力?,数据库架构可以从哪些方面优化?,总结今天给大家分享一个知识点,是关于 MySQL 数据库架构演进的,因为很多兄弟天天基于 MySQL 做系统开发,但是写的系统都是那种低并发压力、小数据量的,所以哪怕上线了也就是这么正常跑着而已。 但是你知道你连接的这个 MySQL 数据库他到底能抗多大并发压力吗?如果 MySQL 数据库扛不住压力
-
但还是没有运气 它工作时没有参数,所以它不是完全错误的,但我在这里遗漏了一些东西。