
openGemini是华为云开源的一款云原生分布式时序数据库,可广泛应用于物联网、车联网、运维监控、工业互联网等业务场景,具备卓越的读写性能和高效的数据分析能力,采用类SQL查询语言,无第三方软件依赖、安装简单、部署灵活、运维便捷,鼓励社区贡献、合作。
特性
- 高性能读写
- 每秒千万级指标数据并发写入
- 万级传感器数据毫秒级响应
- 支持时序数据分析
- 内置AI数据分析算法
- 实时异常检测和预测
- 时序生态兼容
- 完全兼容InfluxDB line protocol 和 Influxql
- 兼容现有InfluxDB工具链
- 支持Prometheus远程数据存储
- 分布式
- 提供了水平扩展能力,支持数百节点集群规模
- 海量时序数据高效管理
- 支持亿级时间线管理
- 内置高效数据压缩算法,存储成本只有传统数据库的1/20
- 灵活部署
- 部署时只需运行编译生成的可执行文件,无需外部依赖
- 所有数据库配置参数均有合理的默认值,无需手动设置
- 支持单机和集群部署
第三方支持
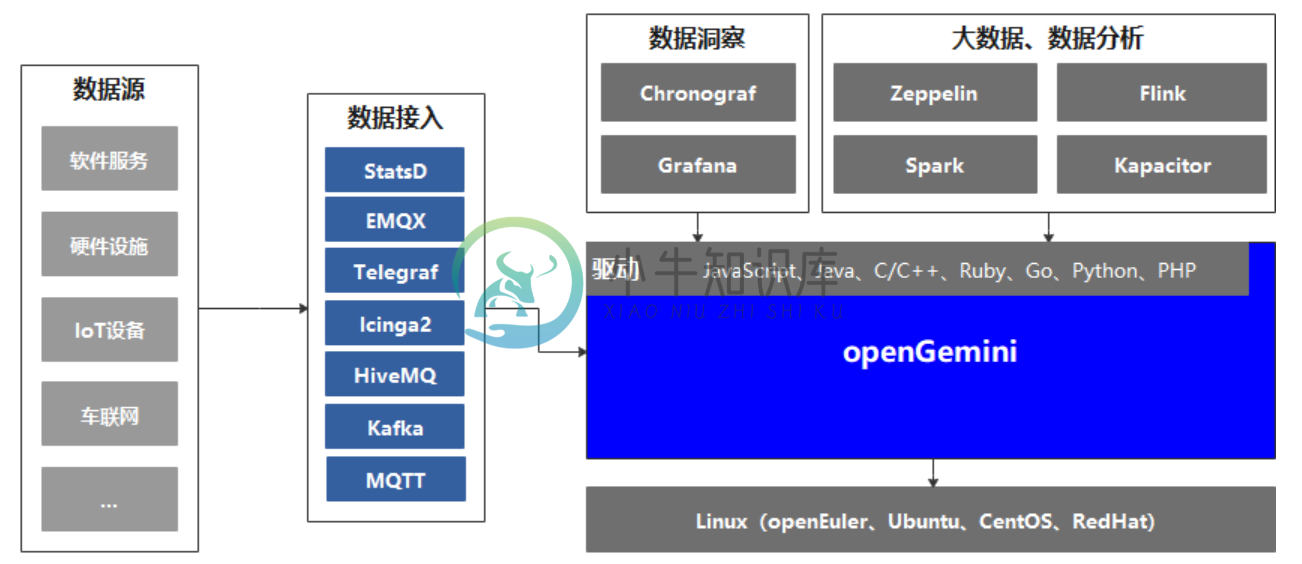
openGemini目前暂时只支持Linux操作系统,无缝支持InfluxDB生态工具链,比如:
主流开发语言驱动:JavaScript、Java、C/C++、Ruby、Go、Python、PHP
客户端:Influx
数据接入工具:StatsD、EMQX、Telegraf、Icinga2、HiveMQ、Kafka、MQTT
数据洞察工具:Chronograf、Grafana
大数据和数据分析系统:Zeppelin、Flink、Spark、Kapacitor等。
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
云原生是一种应用开发风格,鼓励在持续交付和价值驱动开发领域轻松采用最佳实践。相关的学科是建立12-factor Apps,其中开发实践与交付和运营目标相一致,例如通过使用声明式编程和管理和监控。Spring Cloud以多种具体方式促进这些开发风格,起点是一组功能,分布式系统中的所有组件都需要或需要时轻松访问。 许多这些功能都由Spring Boot覆盖,我们在Spring Cloud中建立。更多
-
一个成功的技术,现实的优先级必须高于公关,你可以糊弄别人,但糊弄不了自然规律。 ——罗杰斯委员会报告(1986) 在本书的第一部分中,我们讨论了数据系统的各个方面,但仅限于数据存储在单台机器上的情况。现在我们到了第二部分,进入更高的层次,并提出一个问题:如果多台机器参与数据的存储和检索,会发生什么? 你可能会出于各种各样的原因,希望将数据库分布到多台机器上: 可扩展性 如果你的数据量、读取负载、写
-
主要内容:1.UUID,2.数据库自增Id,3.基于数据库集群模式,4.基于数据库的号段模式,5.Redis,6.Snowflake,7.百度(uid-generator),8.Leaf,9.TinyId生成方式: 1.UUID 2.数据库自增ID 3.数据库多主模式 4.号段模式 5.Redis 6.雪花算法(SnowFlake) 7.滴滴出品(TinyID) 8.百度 (Uidgenerator) 9.美团(Leaf) 1.UUID UUID的生成简单到只有一行代码,输出结果 c2b8c2b
-
这里我的疑问是,如果我使用多个分布式数据库,cam如何在配置(application.properties)中提到不同的DB源URL?目前我正在使用以下结构来使用一个数据库, 就像上面那样。 所以,如果我使用多个DB用于多个区域,我如何在这里给出有条件的配置?我是微服务世界和分布式数据库设计模式的新手。
-
在前面我们已经掌握了Scrapy框架爬虫,虽然爬虫是异步多线程的,但是我们只能在一台主机上运行,爬取效率还是有限。 分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,将大大提高爬取的效率。 16.1 分布式爬虫架构 回顾Scrapy的架构: Scrapy单机爬虫中有一个本地爬取队列Queue,这个队列是利用deque模块实现的。 如果有新的Request产生,就会放到队列里面,随后Reque