
DCMP是分布式配置管理平台。提供了一个etcd的管理界面,可通过界面修改配置信息,借助confd可实现配置文件的同步。
安装 && 启动
> go get github.com/silenceper/dcmp > ./service.sh
界面预览
访问 http://127.0.0.1:8000/
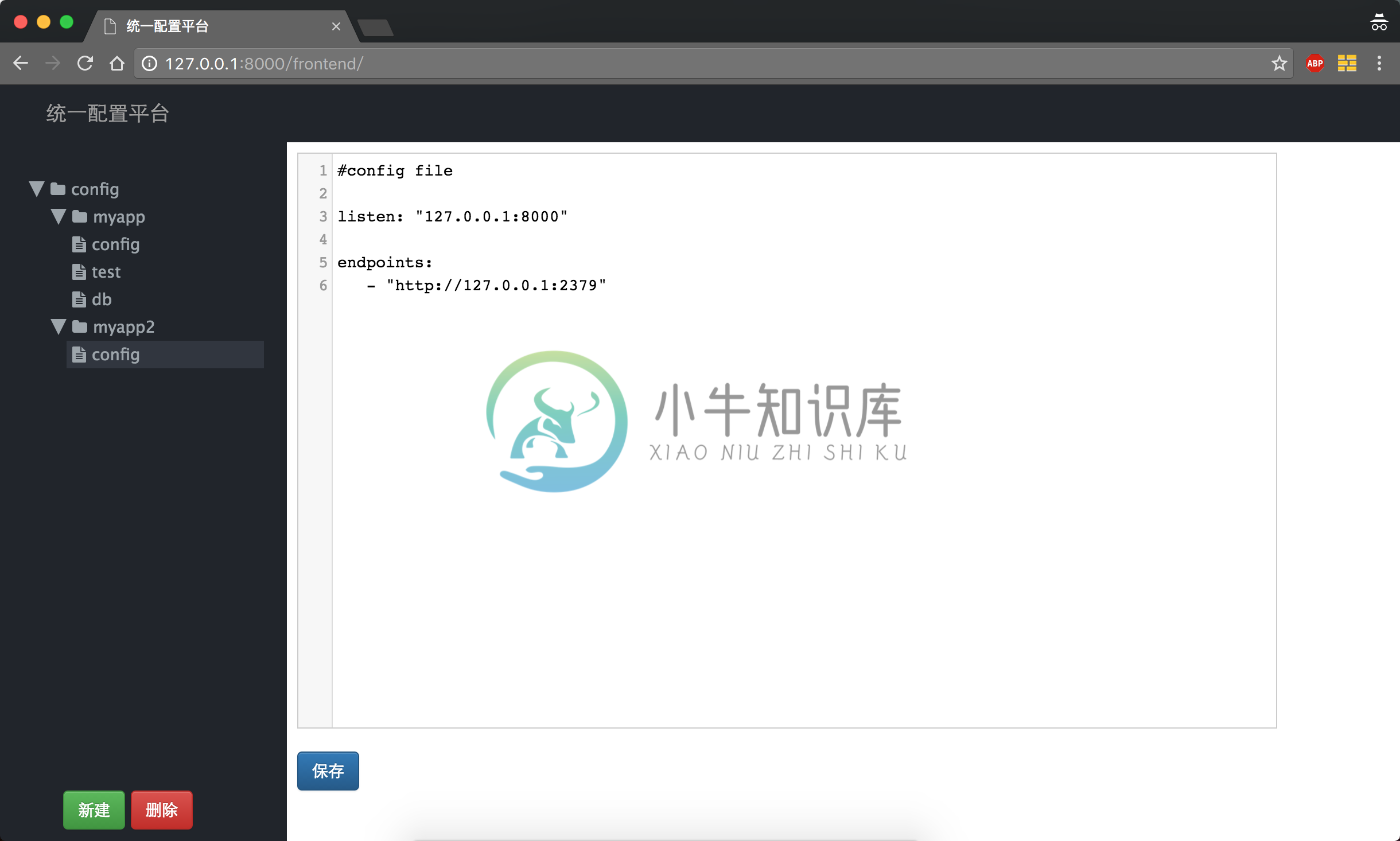
-
一、简介: tcpdump 是一款灵活、功能强大的抓包工具,能有效地帮助排查网络故障问题。 tcpdump官网详细介绍 二、安装 在 Linux 中安装 tcpdump(centos) $ sudo yum install -y tcpdump $ which tcpdump /usr/sbin/tcpdump 三、语法 tcpdump [-adeflnNOpqStvx][-c<数据包数目>]
-
在分布式系统中,常困扰我们的还有上线问题。虽然目前有一些优雅重启方案,但实际应用中可能受限于我们系统内部的运行情况而没有办法做到真正的“优雅”。比如我们为了对去下游的流量进行限制,在内存中堆积一些数据,并对堆积设定时间或总量的阈值。在任意阈值达到之后将数据统一发送给下游,以避免频繁的请求超出下游的承载能力而将下游打垮。这种情况下重启要做到优雅就比较难了。 所以我们的目标还是尽量避免采用或者绕过上线
-
差不多70MIN 面试官人很帅,而且上来就介绍面试流程,整个面试下来感觉很舒服,写算法题的时候也在和面试官沟通确定一些特殊情况 1.自我介绍 2.集中管理平台是什么#面经# 3.发布是怎样实现的 4.Exporter是怎么采集到数据的 (没答好 确实没了解过) 5.交付相关 6.Prometheus规则是怎样的 具体存储在哪里 7.仪表盘数据是哪里来的 Prometheus支持多少台机器 8.怎么
-
Import Path # site_import_path.py import sys import os import site if 'Windows' in sys.platform: SUFFIXES = [ '', 'lib/site-packages', ] else: SUFFIXES = [ 'lib/py
-
Zookeeper提供了一个分层命名空间,允许客户端存储任意数据,如配置数据。Spring Cloud Zookeeper Config是Config Server和Client的替代方案。在特殊的“引导”阶段,配置被加载到Spring环境中。默认情况下,配置存储在/config命名空间中。根据应用程序的名称和模拟解析属性的Spring Cloud Config顺序的活动配置文件,创建多个Prop
-
我希望产品化并部署我的Kafka Connect应用程序。然而,我对任务有两个问题。最大值设置,这是必需的,非常重要,但具体设置该值的具体内容很模糊。 如果我有一个包含n个分区的主题,我希望从中使用数据并将其写入某个接收器(在我的情况下,我正在写入S3),那么我应该设置什么任务。最大值到?我应该把它设置为n吗?我应该把它设置为2n吗?直觉上,我似乎想将值设置为n,这就是我一直在做的。 如果我更改我
-
我想在不同的 VM 上配置 Ehcache 实例,并在主机上运行 servlet,将这些缓存用作数据存储。缓存服务器必须形成一个集群,用于分布式缓存。 我搜索了任何地方(谷歌、stackoverflow、Ehachep留档)。但是,我找不到任何足够的“如何”文章。此外,我不可能使用企业产品(Terracotta BigMemory等)。 可以随意假设元素包含如上所述的客户信息。我只需要知道如何通过