
Scalable 表格 (SFrame, SArray) 和图形 (SGraph) 数据结构用于数据分析。SFrame 提供下列结构的完整实现:
SFrame
SArray
SGraph
C++ SDK surface area (gl_sframe, gl_sarray, gl_sgraph)
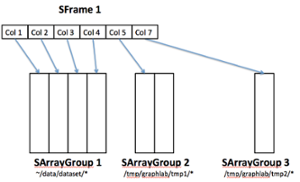
SFrame 包含来自 Dato 的开源组件 GraphLab Create 。
SFrame 关键特性:
一个可伸缩的列压缩,基于磁盘后端存储的数据帧,为机器学习和数据科学研究优化.
主要为表格和图形数据而设计
支持强类型化的数据列和弱类型列
统一支持数据丢失处理
查询优化以及延迟仿真
A C++ API (gl_sarray, gl_sframe, gl_sgraph) with direct native access via the C++ SDK.
A Python API (SArray, SFrame, SGraph) with an indirect access via an interprocess layer.
环境要求:
SFrame 要求 64 位操作系统
操作系统
Mac OS X: 10.8+
Linux: Any distribution with GLIBC >= 2.11
Ubuntu >= 11.04
Debian >= 6
RHEL >= 6
SLES >= 11
Windows (7, 8, 10, Server 2012 R2)
Python
Python 2.7.x
Note: Unfortunately, Python 3.x is currently not supported.
-
一套分布式服务器有若干个节点构成,所以对于分布式服务器框架来说,首先必须解决服务的调度和服务间通信这两个至关重要的问题。上篇文章已经大概介绍了sframe的整体思想。在本篇文章中,我将继续介绍sframe的服务调度和服务间通信。 服务调度 前面已经提到过sframe将服务器节点抽象成了服务节点。在sframe中,所有的服务必须继承sframe::Service类,
-
开发游戏服务器,肯定会有大量的配置数据,什么等级配置、关卡配置等等。对于这些静态数据,我们一般都是采取文件的方式来存储的。策划事先配置好这些数据文件,服务器启动后便将其加载到内存,由配置管理模块统一管理。对于配置文件,有各种各样的格式,CSV、JSON、XML、LUA等等都很流行。但是对于程序来说,我们希望无论配置文件采用什么格式,数据加载到内存后都是一样的存在形式。
-
对于服务器业务开发来说,主要的任务便是处理各种消息——服务间消息、客户端的消息等等。一般的开发模式都是将每一类消息都映射到与其对应的一个处理函数。服务器收到该消息后,找到与其对应的处理函数,再将消息进行解码,最后调用处理函数。这些步骤都是通用的,所以大多数服务器框架都有一套消息映射机制。实际开发中,一套系统的业务往往是非常复杂的,这也就意味着我们要处理的消息是非常多的,几百、几千种
-
安装 https://turi.com/download/install-graphlab-create.html 快速使用 import graphlab 项目 价格 Importing and parsing data url=https://static.turi.com/datasets/millionsong/song_data.csv’ songs = graphlab.SFrame.
-
软件链接 https://turi.com/download/install-graphlab-create.html 常见函数 import graphlab Importing and parsing data url=https://static.turi.com/datasets/millionsong/song_data.csv’ songs = graphlab.SFrame.read
-
sframe包包含与graphlab包相同的聚合模块,因此您不需要求助于numpy. import sframe import sframe.aggregate as agg sf = sframe.SFrame({'user_id': [1, 1, 2], 'rating': [3.3, 3.6, 4.1]}) grp = sf.groupby('user_id', {'mean_rating'
-
参考文档: https://turi.com/products/create/docs/generated/graphlab.SFrame.join.html?highlight=join#graphlab.SFrame.join SFrame.join(right, on=None, how='inner') Merge two SFrames. Merges the current (left
-
序列化和反序列化是我们在实际开发经常用到的东西。一套好的序列化和反序列化的解决方案,往往会起到事半功倍的效果。sframe拥有一套很方便高效的序列化和反序列化机制。在本篇文章中,我将主要介绍这套机制的实现原理。 序列化和反序列化已经是非常成熟的技术了,网上也有着一大堆不一样的实现。已有现成的各种各样的开源库供我们选择。很多较为流行的库都比较大,并且大多都是基于代码生
-
class graphlab.SFrame(data=list(), format='auto') 一个列数可变的表格型数据框架对象,可以适应大数据。SFrame中的数据在GraphLabServer 中以列优先的方式存储,并且存储在持久性存储媒介(例如磁盘)中,避免了被内存大小所限制。SFrame中的每一列都是一个大小不可变的SArray,但是SFrame可以通过增加或者减少列来轻松地改变。一个
-
异常记录 import graphlab sf = graphlab.SFrame('xxxx.csv') 报错 AttributeError: 'module' object has no attribute 'SFrame' 你应该是使用了下面的一句代码安装了某些内容 graphlab.get_dependencies() downloading xz extracting xz 解决
-
类名: SFrame,框架核心类 功能: 1.加载第三方类库 2.定义默认加载程序 3.引入全局函数库 4.初始化系统配置类 5.根据是否是调试模式调整是否显示错误信息 6.根据是否是命令行模式,决定是否开启输出缓存 7.路由解析,并派发 说明: 本类不被开发者使用 禁止实例化,非单例 要求PHP版本5.5或以上 使用到 $mcaName 模块/控制器/动作参数的名称 会被SRouter使用 $i
-
我有一个场景,文件有不同的类型。文件分为页眉、正文和页脚三部分。标题可以是2类型dipend,根据标题大小,我需要使用标记器和范围来解析内容。 页脚也一样,这取决于正文大小和页脚长度,需要解析页脚内容。 我查看了PatternMatchingCompositeLineMapper和fixedlenghttokenizer,但没有找到为范围指定条件的方法,也没有找到在页脚中共享正文内容以检查长度的方
-
let num = 600; num是最大数为600,然后根据arr数组里面的test的值之和(5+4+5+6)为20, 600 / 20 = 30; 希望得到下面的格式: 图片第一列5个输入框对应数组arr里面下标为0的test的值为5 图片第二列4个输入框对应数组arr里面下标为1的test的值为4 ... 控制1-30之间的随机数里面的输入框修改的时候只能输入1-30的数, 控制31-60之
-
js 数组的数据处理 这个2数字不是固定的, 如果a这个值是2 我需要得到arr为 arr = [9] 如果a这个值是4 我需要得到arr为 arr = [7,8,9] 大佬们帮我看看
-
在现实世界中,我们经常遇到大量原始数据,这些数据不适合机器学习算法。 我们需要在将原始数据输入各种机器学习算法之前对其进行预处理。 本章讨论在Python机器学习中预处理数据的各种技术。 数据预处理 在本节中,让我们了解如何在Python中预处理数据。 最初,在文本编辑器(如记事本)中打开扩展名为.py文件,例如prefoo.py文件。 然后,将以下代码添加到此文件中 - import numpy
-
一、创建索引: 在SQLite中,创建索引的SQL语法和其他大多数关系型数据库基本相同,因为这里也仅仅是给出示例用法: sqlite> CREATE TABLE testtable (first_col integer,second_col integer); --创建最简单的索引,该索引基于某个表的一个字段。 sqlite> CREATE INDEX testtable_idx ON test
-
本文向大家介绍springmvc处理响应数据的解析,包括了springmvc处理响应数据的解析的使用技巧和注意事项,需要的朋友参考一下 1. ModelAndView 相关的成员变量和方法 private Object view; 描述视图信息 private ModelMap model 描述模型数据(响应数据) public void setViewName(String viewName)