
![]()
本项目基于golang开发,是一个开放的垂直领域的爬虫框架,框架中将各个功能模块区分开,方便使用者重新实现子模块,进而构建自己垂直方方向的爬虫。
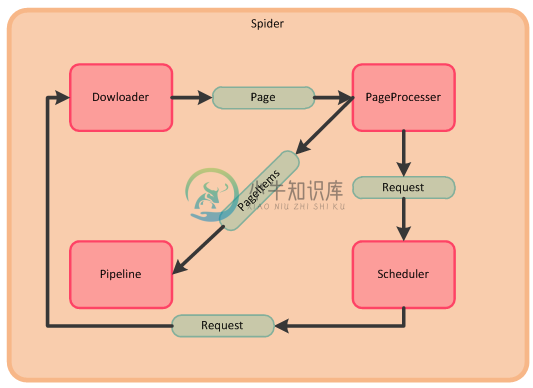
本项目将爬虫的各个功能流程区分成Spider模块(主控),Downloader模块(下载器),PageProcesser模块(页面分析),Scheduler模块(任务队列),Pipeline模块(结果输出);
执行过程简述:
- Spider模块从Scheduler模块中获取包含待抓取url的Request对象,启动一个协程,一个协程执行一次爬取过程,此处我们把协程也看成Spider,Spider把Request对象传入Downloader,Downloader下载该Request对象中url所对应的页面或者其他类型的数据,生成Page对象;
- Spider调用PageProcesser模块解析Page对象中的页面数据,并存入Page对象中的PageItems中(以Key-Value对的形式保存),同时存入解析结果中的待抓取链接,Spider会将待抓取链接存入Scheduler模块中的Request队列中;
- Spider调用Pipeline模块输出Page中的PageItems的结果;
- 执行步骤1,直至Scheduler中所有链接被处理完成,则Spider被挂起等待下一个待抓取链接或者终止。
执行过程相应的Spider核心代码,代码代表一次爬取过程:
// core processer func (this *Spider) pageProcess(req *request.Request) { // Get Page p := this.pDownloader.Download(req) if p == nil { return } // Parse Page this.pPageProcesser.Process(p) for _, req := range p.GetTargetRequests() { this.addRequest(req) } // Output if !p.GetSkip() { for _, pip := range this.pPiplelines { pip.Process(p.GetPageItems(), this) } } this.sleep() }
项目安装与示例执行
- 安装本包和依赖包
go get github.com/hu17889/go_spider go get github.com/PuerkitoBio/goquery go get github.com/bitly/go-simplejson
示例执行:
- 编译:go install github.com/hu17889/go_spider/example/github_repo_page_processor
- 执行:./bin/github_repo_page_processor
展示一个简单爬虫示例
示例的功能是爬取https://github.com/hu17889?tab=repositories下面的项目以及项目详情页的相关信息,并将内容输出到标准输出。
一般在自己的爬虫main包中需要实现爬虫创建,初始化,以及PageProcesser模块的继承实现。可以实现自己的子模块或者使用项目中已经存在的子模块,通过Spider对象中相应的Set或者Add函数将模块引入爬虫。本项目支持链式调用。
spider.NewSpider(NewMyPageProcesser(), "TaskName"). // 创建PageProcesser和Spider,设置任务名称 AddUrl("https://github.com/hu17889?tab=repositories", "html"). // 加入初始爬取链接,需要设置爬取结果类型,方便找到相应的解析器 AddPipeline(pipeline.NewPipelineConsole()). // 引入PipelineConsole输入结果到标准输出 SetThreadnum(3). // 设置爬取参数:并发个数 Run() // 开始执行
-
1.前情提要 作为一个根正苗红的php程序员(筑基前期的程序员),很容易不知道自己想做什么。庞大的系统搞不定,增删改查没意思。。。 在这个背景下,为了学习到php没有的特性(高性能,并发)接受到了公司老员工的火爆安利,对golang的兴趣很大。 2.代码实现 以下是完整代码 package main import ( "fmt" "log" "strings
-
前言 可能很多人都觉得爬虫是 Python 的专属技能,但其实使用 Go 语言可能会实现更加好的效果 爬虫 在开始实现爬虫之前我们必须明白一件事,那就是爬虫是什么。网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。 怎么撰写爬虫 写爬虫程序有以下几
-
python编程快速上手(持续更新中…) python爬虫热点项目(Flask ) 1 爬虫模块的需求 抓取各个免费代理ip网站上的免费代理IP,如果可用保存数据库中,需要抓取代理ip页面如下: 2 爬虫模块的设计思路 通用爬虫: 通过指定URL列表, 分组XPATH和组内XPATH, 来提取不同网站的代理IP 具体爬虫: 用于抓取具体代理IP网站,通过继承通用爬虫实现 爬虫运行模块: 启动爬虫,
-
https://www.xin3721.com/eschool/pythonxin3721/ 1. Spider Middleware Spider Middleware是介入到Scrapy的Spider处理机制的钩子框架。 当Downloader生成Response之后,Response会被发送给Spider,在发送给Spider之前,Response会首先经过Spider Middleware
-
# _*_ coding: utf-8 _*_ import requests, re from lxml import etree class BlBl: def __init__(self,url): self.url = url # 哔哩哔哩弹幕url self.danmu_url= 'https://comment.bilibil
-
一. Go语言爬取 Go语言的爬虫与python类似(可以参照官网http包和regexp包),但是Go语言爬取的效率更高,一般的爬取主要使用到ioutil,http,regexp,sync等相关处理的包,ioutil包主要是读取和写入数据的工具包(包括将数据读取和写入文件),http是关于客户端与服务端请求操作的包,regexp是关于正则表达式匹配相关操作的包,sync是关于同步操
-
主要内容:Scrapy下载安装,创建Scrapy爬虫项目,Scrapy爬虫工作流程,settings配置文件Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。 提示:Twisted 是一个基于事件驱动的网络引擎框架,同样采用 Python 实现。 Scrapy下载安装 Scrapy 支持常见的主流平台,比如 Linux、Mac、Windows 等,因此你可以很方便的安装它
-
有的时候,当我们的爬虫程序完成了,并且在本地测试也没有问题,爬取了一段时间之后突然就发现报错无法抓取页面内容了。这个时候,我们很有可能是遇到了网站的反爬虫拦截。 我们知道,网站一方面想要爬虫爬取网站,比如让搜索引擎爬虫去爬取网站的内容,来增加网站的搜索排名。另一方面,由于网站的服务器资源有限,过多的非真实的用户对网站的大量访问,会增加运营成本和服务器负担。 因此,有些网站会设置一些反爬虫的措施。我
-
这一章将会介绍使用一些新的模块(optparse,spider)去完成一个爬虫的web应用。爬虫其实就是一个枚举出一个网站上面的所有链接,以帮助你创建一个网站地图的web应用程序。而使用Python则可以很快的帮助你开发出一个爬虫脚本. 你可以创建一个爬虫脚本通过href标签对请求的响应内容进行解析,并且可以在解析的同时创建一个新的请求,你还可以直接调用spider模块来实现,这样就不需要自己去写
-
WebMagic是我业余开发的一款简单灵活的爬虫框架。基于它你可以很容易的编写一个爬虫。 这本小书以WebMagic入手,一方面讲解WebMagic的使用方式,另一方面讲解爬虫开发的一些惯用方案。
-
根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种. 通用爬虫 通用网络爬虫 就是 捜索引擎抓取系统,目的是将互联网上的所有的网页下载到本地,形成一个互联网内容的镜像备份。 它决定着整个搜索引擎内容的丰富性和时效性,因此它的性能优劣直接影响着搜索引擎的效果。 通用搜索引擎(Search Engine)工作原理 第一步:抓取网页 搜索引擎网络爬虫的基本工作流程如下: 首先选取一部分的初始UR
-
本文向大家介绍python爬虫框架talonspider简单介绍,包括了python爬虫框架talonspider简单介绍的使用技巧和注意事项,需要的朋友参考一下 1.为什么写这个? 一些简单的页面,无需用比较大的框架来进行爬取,自己纯手写又比较麻烦 因此针对这个需求写了talonspider: •1.针对单页面的item提取 - 具体介绍点这里 •2.spider模块 - 具体介绍点这里 2.介
-
爬虫项是什么呢?比如采集文章列表、文章详情页,他们都是不同的采集项。 定义示例: 继承Yurun\Crawler\Module\Crawler\Contract\BaseCrawlerItem类。 <?php namespace Yurun\CrawlerApp\Module\YurunBlog\Article; use Imi\Bean\Annotation\Bean; use Yurun\C
-
拼多多爬虫工程师面试题 电话面: http协议、tcp协议(几次握手) top命令 Linux/Mac 下虚拟内存(Swap) 线程、进程、协程 Async 相关、事件驱动相关 阻塞、非阻塞 Python GIL 布隆过滤器原理:如何实现、一般要几次哈希函数 给我留下了一个作业:抓取天猫超市上某些商品的可以配送省份信息。(当时做这个也花了很久,主要是需要解决PC端的登陆问题,后来通过h5接口) 现