
Crawlab 是一个使用 Golang 开发的分布式爬虫管理平台,支持Python、NodeJS、Go、Java、PHP等多种编程语言以及多种爬虫框架。
安装
三种方式:
要求(Docker)
- Docker 18.03+
- Redis
- MongoDB 3.6+
要求(直接部署)
- Go 1.12+
- Node 8.12+
- Redis
- MongoDB 3.6+
运行
Docker
运行主节点示例。192.168.99.1是在Docker Machine网络中的宿主机IP地址。192.168.99.100是Docker主节点的IP地址。
docker run -d --rm --name crawlab \
-e CRAWLAB_REDIS_ADDRESS=192.168.99.1 \
-e CRAWLAB_MONGO_HOST=192.168.99.1 \
-e CRAWLAB_SERVER_MASTER=Y \
-e CRAWLAB_API_ADDRESS=192.168.99.100:8000 \
-e CRAWLAB_SPIDER_PATH=/app/spiders \
-p 8080:8080 \
-p 8000:8000 \
-v /var/logs/crawlab:/var/logs/crawlab \
tikazyq/crawlab:0.3.0
当然也可以用docker-compose来一键启动,甚至不用配置MongoDB和Redis数据库,当然我们推荐这样做。在当前目录中创建docker-compose.yml文件,输入以下内容。
version: '3.3'
services:
master:
image: tikazyq/crawlab:latest
container_name: master
environment:
CRAWLAB_API_ADDRESS: "localhost:8000"
CRAWLAB_SERVER_MASTER: "Y"
CRAWLAB_MONGO_HOST: "mongo"
CRAWLAB_REDIS_ADDRESS: "redis"
ports:
- "8080:8080" # frontend
- "8000:8000" # backend
depends_on:
- mongo
- redis
mongo:
image: mongo:latest
restart: always
ports:
- "27017:27017"
redis:
image: redis:latest
restart: always
ports:
- "6379:6379"
然后执行以下命令,Crawlab主节点+MongoDB+Redis就启动了。打开http://localhost:8080就能看到界面。
docker-compose up
Docker部署的详情,请见相关文档。
直接部署
请参考相关文档。
截图
登录

首页

节点列表

节点拓扑图
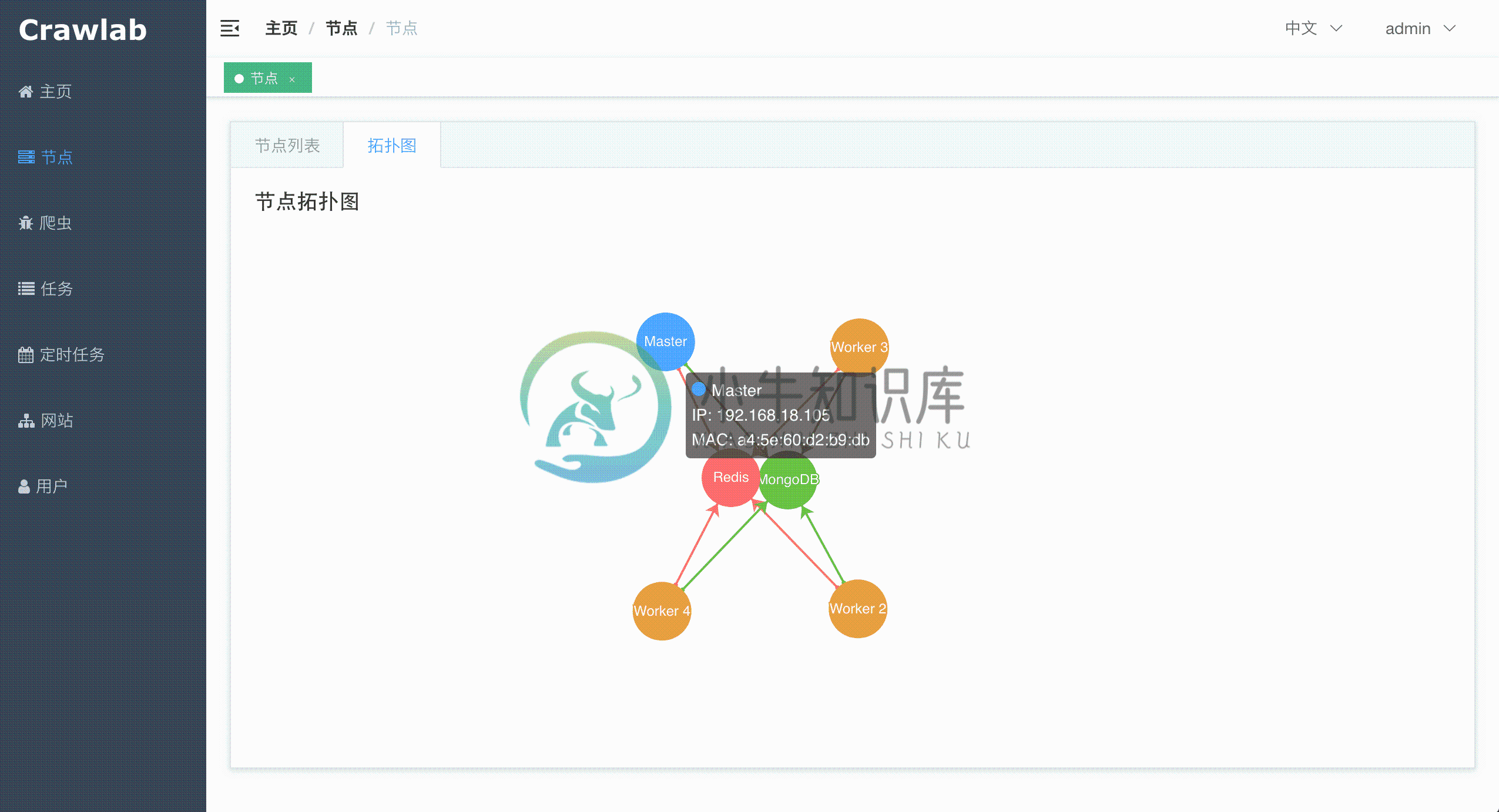
爬虫列表
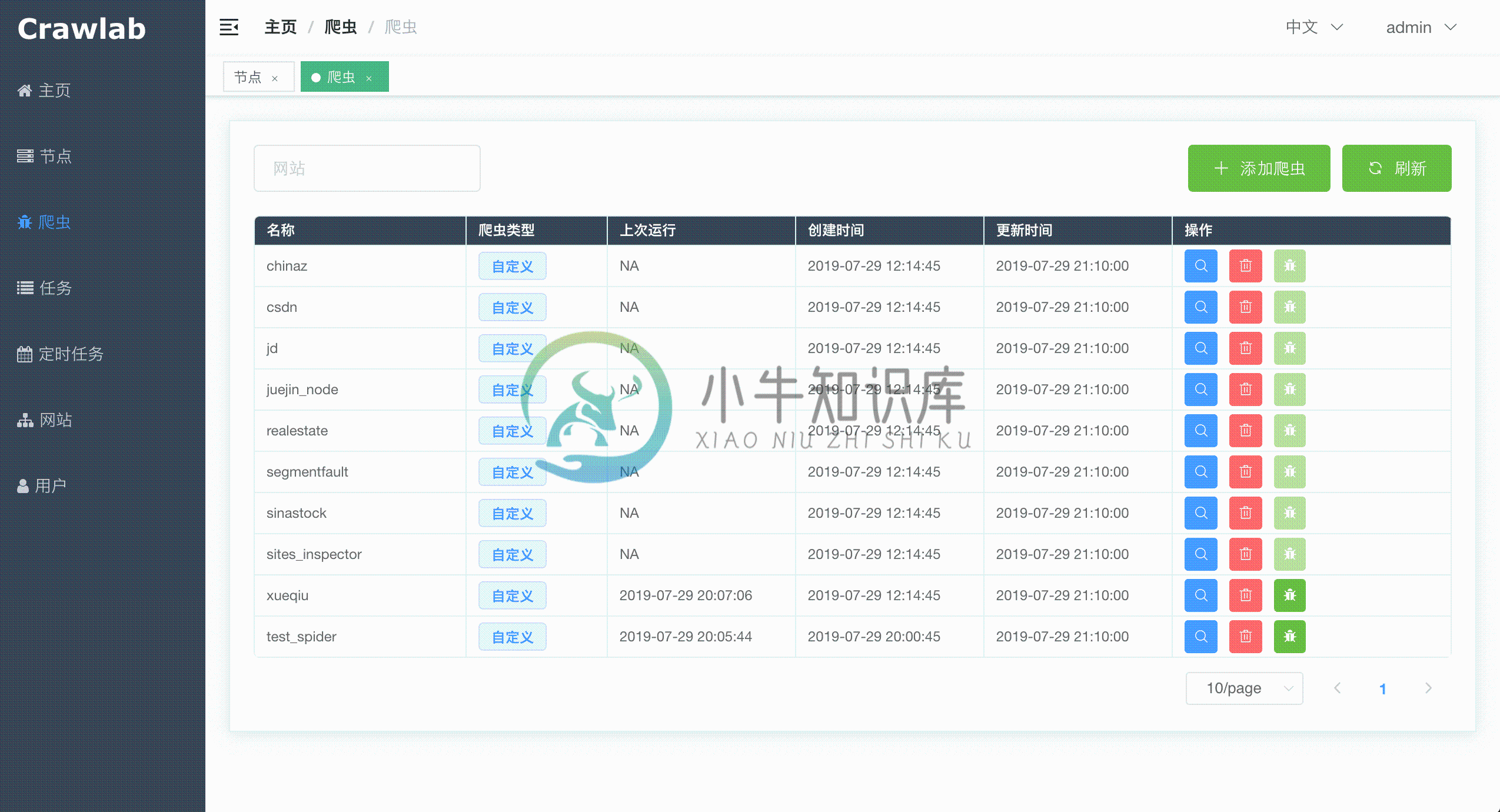
爬虫概览
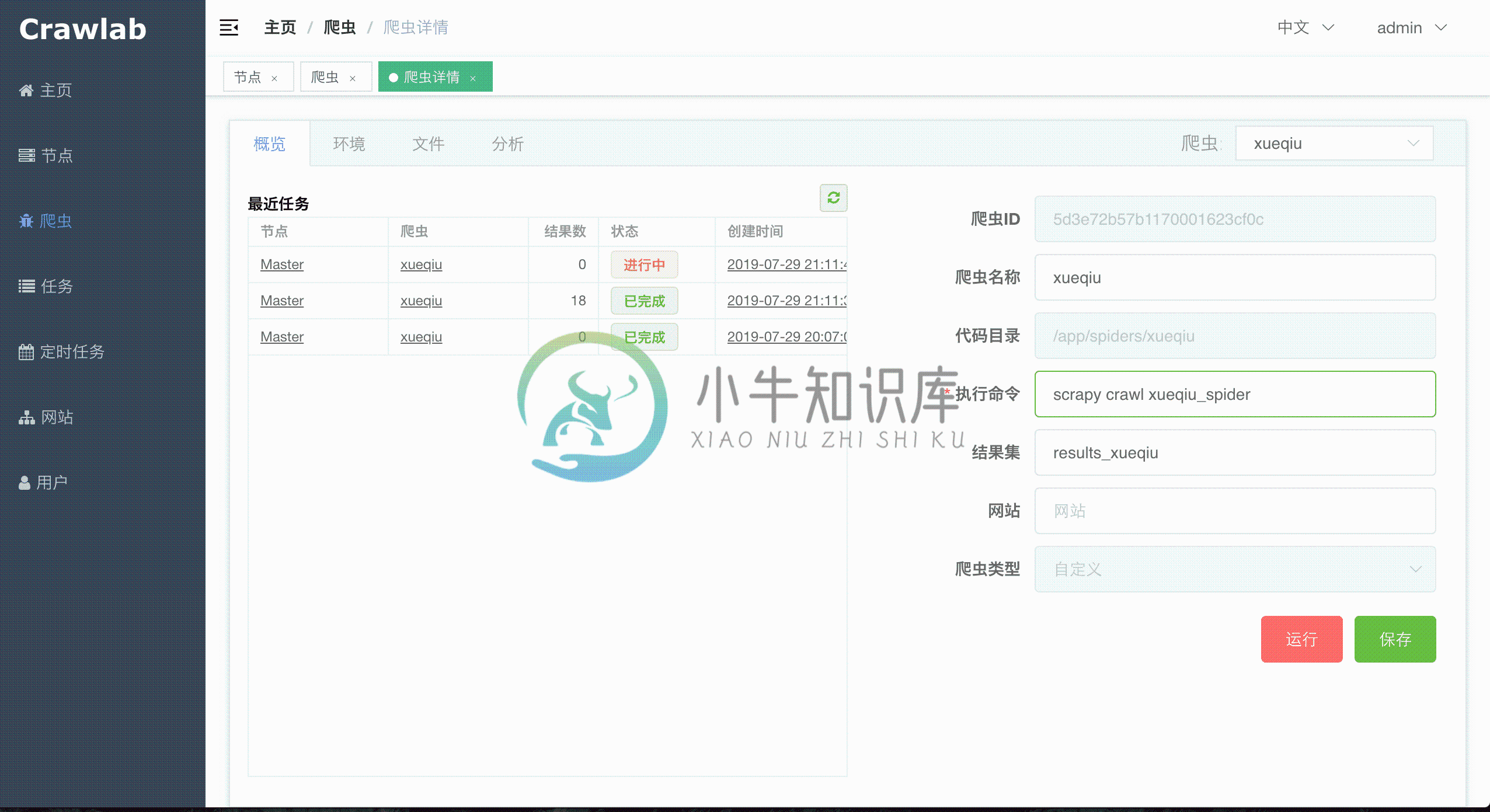
爬虫分析
爬虫文件

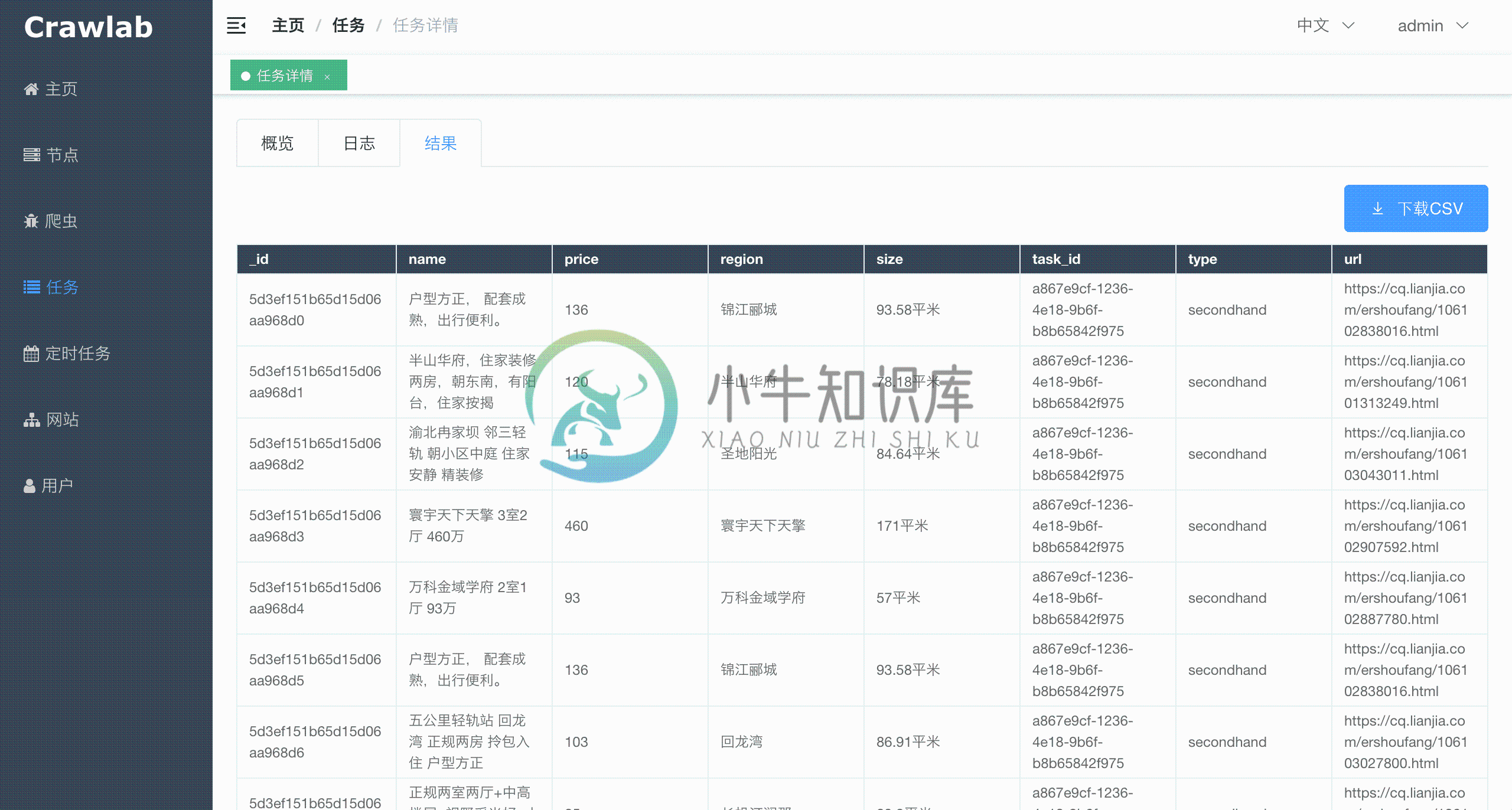
任务详情 - 抓取结果
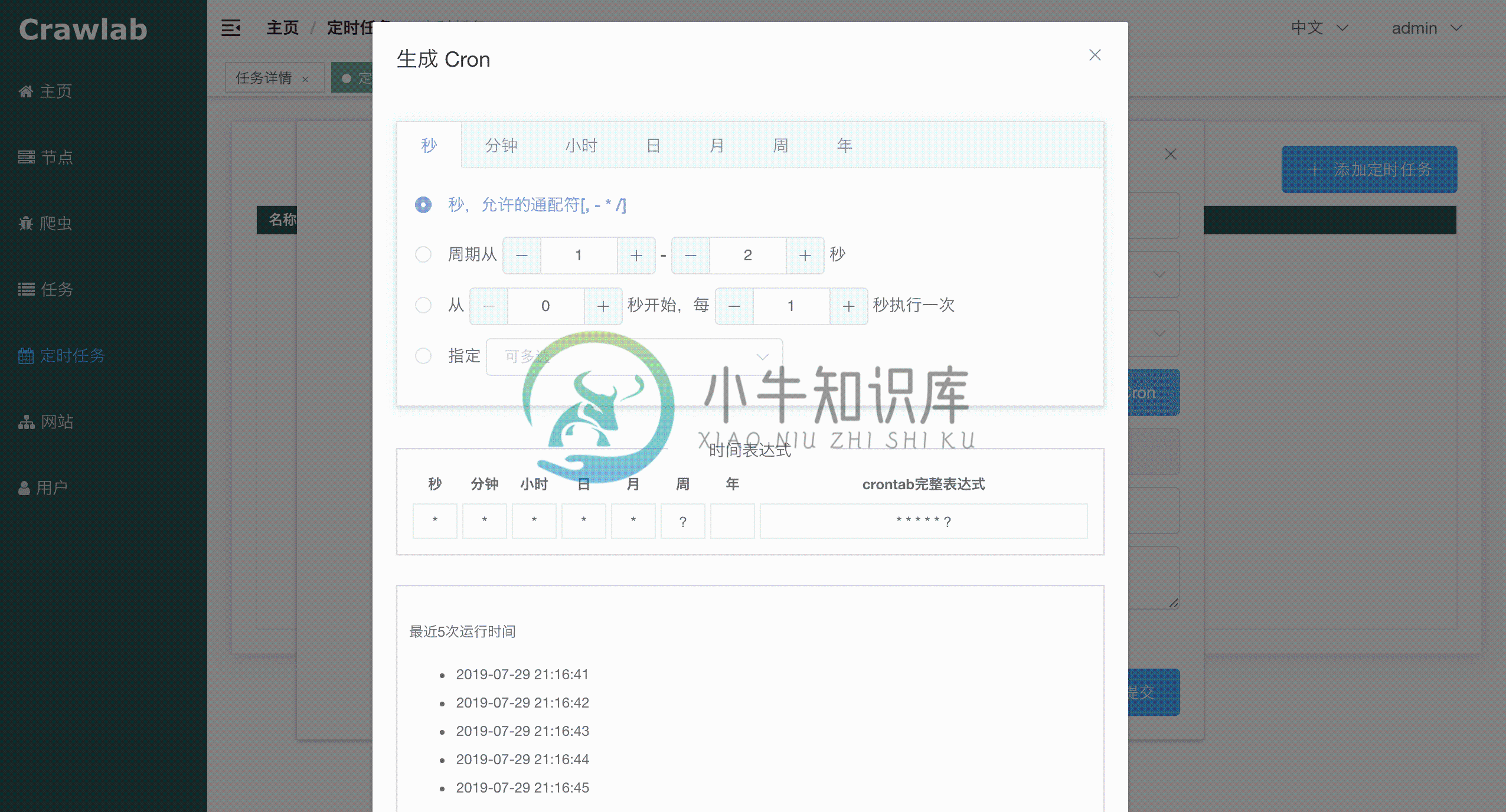
定时任务
架构
Crawlab的架构包括了一个主节点(Master Node)和多个工作节点(Worker Node),以及负责通信和数据储存的Redis和MongoDB数据库。
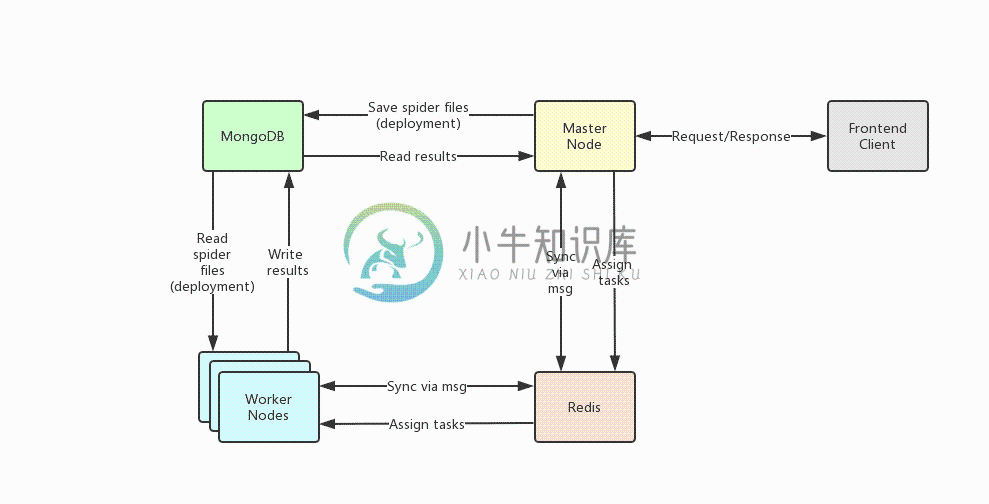
前端应用向主节点请求数据,主节点通过MongoDB和Redis来执行任务派发调度以及部署,工作节点收到任务之后,开始执行爬虫任务,并将任务结果储存到MongoDB。架构相对于v0.3.0之前的Celery版本有所精简,去除了不必要的节点监控模块Flower,节点监控主要由Redis完成。
主节点
主节点是整个Crawlab架构的核心,属于Crawlab的中控系统。
主节点主要负责以下功能:
- 爬虫任务调度
- 工作节点管理和通信
- 爬虫部署
- 前端以及API服务
- 执行任务(可以将主节点当成工作节点)
主节点负责与前端应用进行通信,并通过Redis将爬虫任务派发给工作节点。同时,主节点会同步(部署)爬虫给工作节点,通过Redis和MongoDB的GridFS。
工作节点
工作节点的主要功能是执行爬虫任务和储存抓取数据与日志,并且通过Redis的PubSub跟主节点通信。通过增加工作节点数量,Crawlab可以做到横向扩展,不同的爬虫任务可以分配到不同的节点上执行。
MongoDB
MongoDB是Crawlab的运行数据库,储存有节点、爬虫、任务、定时任务等数据,另外GridFS文件储存方式是主节点储存爬虫文件并同步到工作节点的中间媒介。
Redis
Redis是非常受欢迎的Key-Value数据库,在Crawlab中主要实现节点间数据通信的功能。例如,节点会将自己信息通过HSET储存在Redis的nodes哈希列表中,主节点根据哈希列表来判断在线节点。
前端
前端是一个基于Vue-Element-Admin的单页应用。其中重用了很多Element-UI的控件来支持相应的展示。
与其他框架的集成
爬虫任务本质上是由一个shell命令来实现的。任务ID将以环境变量CRAWLAB_TASK_ID的形式存在于爬虫任务运行的进程中,并以此来关联抓取数据。另外,CRAWLAB_COLLECTION是Crawlab传过来的所存放collection的名称。
在爬虫程序中,需要将CRAWLAB_TASK_ID的值以task_id作为可以存入数据库中CRAWLAB_COLLECTION的collection中。这样Crawlab就知道如何将爬虫任务与抓取数据关联起来了。当前,Crawlab只支持MongoDB。
集成Scrapy
以下是Crawlab跟Scrapy集成的例子,利用了Crawlab传过来的task_id和collection_name。
import os
from pymongo import MongoClient
MONGO_HOST = '192.168.99.100'
MONGO_PORT = 27017
MONGO_DB = 'crawlab_test'
# scrapy example in the pipeline
class JuejinPipeline(object):
mongo = MongoClient(host=MONGO_HOST, port=MONGO_PORT)
db = mongo[MONGO_DB]
col_name = os.environ.get('CRAWLAB_COLLECTION')
if not col_name:
col_name = 'test'
col = db[col_name]
def process_item(self, item, spider):
item['task_id'] = os.environ.get('CRAWLAB_TASK_ID')
self.col.save(item)
return item
与其他框架比较
现在已经有一些爬虫管理框架了,因此为啥还要用Crawlab?
因为很多现有当平台都依赖于Scrapyd,限制了爬虫的编程语言以及框架,爬虫工程师只能用scrapy和python。当然,scrapy是非常优秀的爬虫框架,但是它不能做一切事情。
Crawlab使用起来很方便,也很通用,可以适用于几乎任何主流语言和框架。它还有一个精美的前端界面,让用户可以方便的管理和运行爬虫。
| 框架 | 类型 | 分布式 | 前端 | 依赖于Scrapyd |
|---|---|---|---|---|
| Crawlab | 管理平台 | Y | Y | N |
| ScrapydWeb | 管理平台 | Y | Y | Y |
| SpiderKeeper | 管理平台 | Y | Y | Y |
| Gerapy | 管理平台 | Y | Y | Y |
| Scrapyd | 网络服务 | Y | N | N/A |
Q&A
1. 为何我访问 http://localhost:8080 提示访问不了?
假如您是Docker部署的,请检查一下您是否用了Docker Machine,这样的话您需要输入地址 http://192.168.99.100:8080才行。
另外,请确保您用了-p 8080:8080来映射端口,并检查宿主机是否开放了8080端口。
2. 我可以看到登录页面了,但为何我点击登陆的时候按钮一直转圈圈?
绝大多数情况下,您可能是没有正确配置CRAWLAB_API_ADDRESS这个环境变量。这个变量是告诉前端应该通过哪个地址来请求API数据的,因此需要将它设置为宿主机的IP地址+端口,例如 192.168.0.1:8000。接着,重启容器,在浏览器中输入宿主机IP+端口,就可以顺利登陆了。
请注意,8080是前端端口,8000是后端端口,您在浏览器中只需要输入前端的地址就可以了,要注意区分。
3. 在爬虫页面有一些不认识的爬虫列表,这些是什么呢?
这些是demo爬虫,如果需要添加您自己的爬虫,请将您的爬虫文件打包成zip文件,再在爬虫页面中点击添加爬虫上传就可以了。
注意,Crawlab将取文件名作为爬虫名称,这个您可以后期更改。另外,请不要将zip文件名设置为中文,可能会导致上传不成功。
-
一,安装vm ,centos系统 (测试步骤,正式搭建可以跳过) 1,在win10上,安装vm,centos8.5系统 vm下载(试用版本):https://www.vmware.com/cn/products/workstation-pro/workstation-pro-evaluation.html centos8.5系统: CentOS Mirrors List 2,下载完成之后打开虚拟机
-
Crawlab爬虫管理框架使用(上手) 1、准备 1.1 安装Go环境 官网要求使用 Go1.15+ 的 更多 Go 下载 我使用的是 Go1.17.5 ,如果你懒得去寻找的话也可以和我使用同一个版本 Go1.17.5 下载完成后直接点点就可以 1.2安装Docker 1.2.1 安装docker(默认推荐docker) 可参考 docker 官方文档 进行安装 Windows 和 Mac 的用户
-
一、生产环境上我们不希望仅仅是简单部署,我们可以在多台服务器上分别部署Crawlab然后连接公共的MongoDB及Redis。这时候就需要让Mongo及Redis独立出来,避免耦合启动。 二、 Docker-Compose主节点 docker-compose.yml version: '3.3' services: master: image: tikazyq/crawlab:lat
-
crawlab是一个开源且简单好用的爬虫管理平台。在GitHub已收到7.6k的star,官网:https://github.com/crawlab-team/crawlab。本次尝试部署:使用Docker容器部署方式,简单方便;参数从简,适合小白,先开起来再研究QAQ~ 一、需要准备的环境 二、部署步骤 三、写在最后 一、需要准备的环境 Docker 1.13.1 Python 3.
-
Crawlab 搭建 基于unbuntu系统环境配置 1.更新系统指令 sudo apt-get update 部署docker 2.1.若有docker则先卸载旧版 apt-get remove docker docker-engine docker.io containerd runc 2.2. apt-get install ca-certificates curl gnupg lsb
-
警告 请勿使用本文提到的内容违反法律。 本文不提供任何担保 目录 警告 一、概述 二、影响版本 三、漏洞复现 一、概述 Crawlab users 的 api 存在任意用户添加,且添加为未授权接口,可通过添加后在后台进一步攻击。
-
在前面我们已经掌握了Scrapy框架爬虫,虽然爬虫是异步多线程的,但是我们只能在一台主机上运行,爬取效率还是有限。 分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,将大大提高爬取的效率。 16.1 分布式爬虫架构 回顾Scrapy的架构: Scrapy单机爬虫中有一个本地爬取队列Queue,这个队列是利用deque模块实现的。 如果有新的Request产生,就会放到队列里面,随后Reque
-
互联网时代的信息爆炸是很多人倍感头痛的问题,应接不暇的新闻、信息、视频,无孔不入地侵占着我们的碎片时间。但另一方面,在我们真正需要数据的时候,却感觉数据并不是那么容易获取的。比如我们想要分析现在人在讨论些什么,关心些什么。甚至有时候,可能我们只是暂时没有时间去一一阅览心仪的小说,但又想能用技术手段把它们存在自己的资料库里。哪怕是几个月或一年后再来回顾。再或者我们想要把互联网上这些稍纵即逝的有用信息
-
差不多70MIN 面试官人很帅,而且上来就介绍面试流程,整个面试下来感觉很舒服,写算法题的时候也在和面试官沟通确定一些特殊情况 1.自我介绍 2.集中管理平台是什么#面经# 3.发布是怎样实现的 4.Exporter是怎么采集到数据的 (没答好 确实没了解过) 5.交付相关 6.Prometheus规则是怎样的 具体存储在哪里 7.仪表盘数据是哪里来的 Prometheus支持多少台机器 8.怎么
-
本文向大家介绍Java多线程及分布式爬虫架构原理解析,包括了Java多线程及分布式爬虫架构原理解析的使用技巧和注意事项,需要的朋友参考一下 这是 Java 爬虫系列博文的第五篇,在上一篇Java 爬虫服务器被屏蔽的解决方案中,我们简单的聊反爬虫策略和反反爬虫方法,主要针对的是 IP 被封及其对应办法。前面几篇文章我们把爬虫相关的基本知识都讲的差不多啦。这一篇我们来聊一聊爬虫架构相关的内容。 前面几
-
在分布式系统中,常困扰我们的还有上线问题。虽然目前有一些优雅重启方案,但实际应用中可能受限于我们系统内部的运行情况而没有办法做到真正的“优雅”。比如我们为了对去下游的流量进行限制,在内存中堆积一些数据,并对堆积设定时间或总量的阈值。在任意阈值达到之后将数据统一发送给下游,以避免频繁的请求超出下游的承载能力而将下游打垮。这种情况下重启要做到优雅就比较难了。 所以我们的目标还是尽量避免采用或者绕过上线
-
有的时候,当我们的爬虫程序完成了,并且在本地测试也没有问题,爬取了一段时间之后突然就发现报错无法抓取页面内容了。这个时候,我们很有可能是遇到了网站的反爬虫拦截。 我们知道,网站一方面想要爬虫爬取网站,比如让搜索引擎爬虫去爬取网站的内容,来增加网站的搜索排名。另一方面,由于网站的服务器资源有限,过多的非真实的用户对网站的大量访问,会增加运营成本和服务器负担。 因此,有些网站会设置一些反爬虫的措施。我
-
这一章将会介绍使用一些新的模块(optparse,spider)去完成一个爬虫的web应用。爬虫其实就是一个枚举出一个网站上面的所有链接,以帮助你创建一个网站地图的web应用程序。而使用Python则可以很快的帮助你开发出一个爬虫脚本. 你可以创建一个爬虫脚本通过href标签对请求的响应内容进行解析,并且可以在解析的同时创建一个新的请求,你还可以直接调用spider模块来实现,这样就不需要自己去写
-
百度云分享爬虫项目 github上有好几个这样的开源项目,但是都只提供了爬虫部分,这个项目在爬虫的基础上还增加了保存数据,建立elasticsearch索引的模块,可以用在实际生产环境中,不过web模块还是需要自己开发 安装 安装node.js和pm2,node用来运行爬虫程序和索引程序,pm2用来管理node任务 安装mysql和mongodb,mysql用来保存爬虫数据,mongodb用来保存