
Cola是一个分布式的爬虫框架,用户只需编写几个特定的函数,而无需关注分布式运行的细节。任务会自动分配到多台机器上,整个过程对用户是透明的。
依赖
首先,确保Python版本为2.6或者2.7(未来会支持3+)。由于Cola配置文件使用的yaml,所以Cola只依赖于pyyaml,安装easy_install或者pip工具后,则可以:
pip install pyyaml
安装
下载或者用git clone源码,假设在目录/to/pth/cola,将该路径添加到Python path中。
一种简单的方法是在site-packages中添加pth文件。site-packages因系统而异,如果是windows,假设python装在C:\python27,那么就是C:\python27\Lib\site-packages;如果是linux,那么应该是/usr/local/lib/pythonX.X/dist-packages。
在site-packages下新建一个cola.pth文件,里面写上路径:/to/path/cola。
运行
Cola集群需要一个master和若干个worker,对于每台机器,只能启动一个worker。但是,集群不是必须的,在单机模式下亦可以运行。
Cola目前自带了若干个爬虫,在项目根目录下的contrib中。
下面就wiki为例,分别说明如何在单机和分布式环境下运行。
依赖
无论是维基百科还是新浪微博的实现,数据都存放在MongoDB中,所以要确保MongoDB的安装。
在wiki下的wiki.yaml和weibo下的weibo.yaml中可以配置MongoDB的主机和端口。
维基百科和新浪微博实现依赖于下面的几个包:
mechanize
python-dateutil
BeautifulSoup4
mongoengine
rsa(仅新浪微博需要)
可以使用pip或者easy_install来安装。
单机模式
单机模式非常简单,只需运行contrib/wiki/__init__.py即可。
cd /to/path/cola/contrib/wiki python __init__.py
要运行新浪微博的爬虫,需要在weibo.yaml中配置登录的用户名和密码。这里要注意,要保证这个用户名和密码在登录时不需要验证码。
停止则需运行stop.py,注意不能通过直接杀死进程来停止,否则会导致cola非法关闭。如果非法关闭,确保cola不在运行的情况下,则可以运行stop.py来恢复。但无论如何,都不推荐非法关闭,否则可能遇到不可预知的错误。
python stop.py
分布式模式
首先需要启动cola master和cola workers。分别运行根目录下bin中的start_master.py和start_worker.py
启动cola master:
cd /to/path/cola python bin/start_master.py --data /my/path/data
如果不指定--data,那么数据文件会放置在项目根目录下的data文件夹中。
启动cola worker:
python bin/start_worker.py --master <master ip address> --data /my/path/data
--data选项同master。如果不指定master,会询问是否连接到本机master,输入yes连接。
最后使用bin下的coca.py来运行指定的Cola job:
python bin/coca.py -m <master ip address> -runLocalJob /to/path/cola/contrib/wiki
-runLocalJob选项是要运行的job所在文件夹的绝对路径。输入命令后,该job会被提交到Cola集群来运行。
停止Cola Job或集群
停止整个集群,则可以运行:
python bin/coca.py -m <master ip address> -stopAll
而停止一个Job,则需要查询得到Job的名称:
python bin/coca.py -m <master ip address> -showRunningJobsNames
得到名称后,再运行:
python bin/coca.py -m <master ip address> -stopRunningJobByName <job name>
基于Cola实现的爬虫
基于Cola实现的爬虫位于contrib/目录下。目前实现了四个爬虫:
wiki:维基百科。
weibo:新浪微博爬虫。从初始用户出发,然后是其关注和粉丝,依次类推,抓取指定个数的新浪微博用户的微博、个人信息、关注和粉丝。其中,用户微博只获取了内容、赞的个数、转发和评论的个数等等,而没有具体去获取此微博被转发和评论的内容。
generic(unstable):通用爬虫,只需配置,而无需修改代码。目前Cola实现了一个抽取器(cola/core/extractor),能够从网页正文中自动抽取主要内容,即去除类似边栏和底脚等内容。但是,此抽取器目前准确度还不够,效率也不够高,所以需要谨慎使用。
weibosearch(unstable):新浪微博搜索的爬虫。这个爬虫使用cola.core.opener.SpynnerOpener,基于spynner实现了一个Opener能够执行JavaScript和Ajax代码。目前这个爬虫存在的问题是:新浪微博可能会将其识别成机器人,因此有可能会让输入验证码。
wiki和weibo之前有所提及。主要说明generic和weibosearch。
对于generic来说,主要要修改的就是配置文件:
job: patterns: - regex: http://blog.sina.com.cn/$ name: home store: no extract: no - regex: http://blog.sina.com.cn/s/blog_.+ name: article store: yes extract: yes
其中,regex表示要匹配的url的正则表达式;name是正则匹配的名称;store为yes时是存储这个网页,no为不存储;extract表示是否自动抽取网页正文,只有当store为yes的时候,extract才有作用。
对于weibosearch,其使用了spynner来执行JavaScript和Ajax代码。所以需要确保以下依赖的安装:
如果你觉得可以基于cola实现一个比较通用的第三方爬虫,比如说腾讯微博等等,欢迎将此爬虫提交到contrib/中。
编写自定义Cola Job
见wiki编写自定义Cola Job。
架构和原理
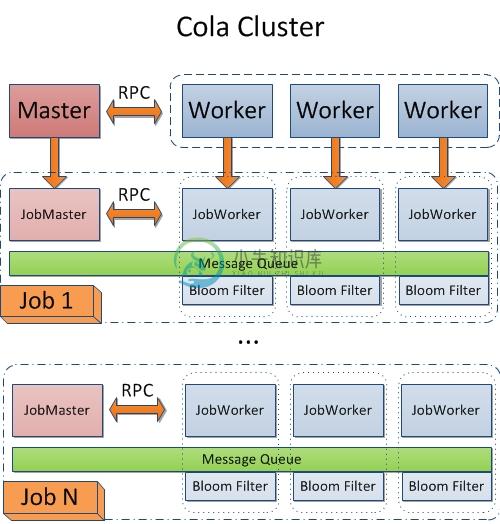
在Cola集群里,当一个任务被提交的时候,Cola Master和Worker会分别启动JobMaster和JobWorker。对于一个Cola Job,当JobWorker启动完成后,会通知JobMaster,JobMaster等待所有JobWorker启动完成后开始运行Job。在一个Cola Job启动时,会启动一个消息队列(Message Queue,主要操作是put和get,worker抓取到的对象会被put到队列中,而要抓取新的对象时,只要从队列中取即可),每个JobWorker上都存在消息队列节点,同时会有一个去重模块(bloom filter实现)。
问题
Cola还不够稳定,目前会处于持续改进的状态。且Cola还没有在较大规模的集群上测试,但是接下来我会把Cola应用到新项目中,并逐步完善。也希望大家也能给我反馈,并帮助改进。
Roadmap
0.1版本正式推出前不会再增加新的功能了,主要目标让Cola更加稳定,并且提高cola/core/extractor的性能和精确度,完善contrib/generic和contrib/weibosearch。
0.2版本计划:
实现一个web接口,可以查看运行的cola job以及运行情况
简化安装,支持easy_install或者pip安装。增加解决依赖库安装的机制。
0.3版本计划:
增加一个统一持久化抽象,支持保存到关系型数据库,MongoDB,文件系统,HDFS等等。
0.4版本计划:
支持Python 3+
-
基于 阿里 cola 落地DDD 1. GitHub https://github.com/alibaba/COLA 2. 生成脚手架 D:\open_source\cola>mvn archetype:generate -DgroupId=com.alibaba.cola.demo.web -DartifactId=demo-web -Dversion=1.0.0-SNAPSHOT -Dpa
-
COCA COLA I/ Coca Cola Vietnam Background In 1886, Coca-Cola history began when the curiosity of an Atlanta pharmacist, Dr. John S. Pemberton, created a distinctive tasting soft drink that could be s
-
互联网时代的信息爆炸是很多人倍感头痛的问题,应接不暇的新闻、信息、视频,无孔不入地侵占着我们的碎片时间。但另一方面,在我们真正需要数据的时候,却感觉数据并不是那么容易获取的。比如我们想要分析现在人在讨论些什么,关心些什么。甚至有时候,可能我们只是暂时没有时间去一一阅览心仪的小说,但又想能用技术手段把它们存在自己的资料库里。哪怕是几个月或一年后再来回顾。再或者我们想要把互联网上这些稍纵即逝的有用信息
-
在前面我们已经掌握了Scrapy框架爬虫,虽然爬虫是异步多线程的,但是我们只能在一台主机上运行,爬取效率还是有限。 分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,将大大提高爬取的效率。 16.1 分布式爬虫架构 回顾Scrapy的架构: Scrapy单机爬虫中有一个本地爬取队列Queue,这个队列是利用deque模块实现的。 如果有新的Request产生,就会放到队列里面,随后Reque
-
主要内容:Scrapy下载安装,创建Scrapy爬虫项目,Scrapy爬虫工作流程,settings配置文件Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。 提示:Twisted 是一个基于事件驱动的网络引擎框架,同样采用 Python 实现。 Scrapy下载安装 Scrapy 支持常见的主流平台,比如 Linux、Mac、Windows 等,因此你可以很方便的安装它
-
本文向大家介绍Java多线程及分布式爬虫架构原理解析,包括了Java多线程及分布式爬虫架构原理解析的使用技巧和注意事项,需要的朋友参考一下 这是 Java 爬虫系列博文的第五篇,在上一篇Java 爬虫服务器被屏蔽的解决方案中,我们简单的聊反爬虫策略和反反爬虫方法,主要针对的是 IP 被封及其对应办法。前面几篇文章我们把爬虫相关的基本知识都讲的差不多啦。这一篇我们来聊一聊爬虫架构相关的内容。 前面几
-
本文向大家介绍简单好用的nodejs 爬虫框架分享,包括了简单好用的nodejs 爬虫框架分享的使用技巧和注意事项,需要的朋友参考一下 这个就是一篇介绍爬虫框架的文章,开头就不说什么剧情了。什么最近一个项目了,什么分享新知了,剧情是挺好,但介绍的很初级,根本就没有办法应用,不支持队列的爬虫,都是耍流氓。 所以我就先来举一个例子,看一下这个爬虫框架是多么简单并可用。 第一步:安装 Crawl-pet
-
本文向大家介绍分享一个简单的java爬虫框架,包括了分享一个简单的java爬虫框架的使用技巧和注意事项,需要的朋友参考一下 反复给网站编写不同的爬虫逻辑太麻烦了,自己实现了一个小框架 可以自定义的部分有: 请求方式(默认为Getuser-agent为谷歌浏览器的设置),可以通过实现RequestSet接口来自定义请求方式 储存方式(默认储存在f盘的html文件夹下),可以通过SaveUtil接口来
-
有的时候,当我们的爬虫程序完成了,并且在本地测试也没有问题,爬取了一段时间之后突然就发现报错无法抓取页面内容了。这个时候,我们很有可能是遇到了网站的反爬虫拦截。 我们知道,网站一方面想要爬虫爬取网站,比如让搜索引擎爬虫去爬取网站的内容,来增加网站的搜索排名。另一方面,由于网站的服务器资源有限,过多的非真实的用户对网站的大量访问,会增加运营成本和服务器负担。 因此,有些网站会设置一些反爬虫的措施。我
-
这一章将会介绍使用一些新的模块(optparse,spider)去完成一个爬虫的web应用。爬虫其实就是一个枚举出一个网站上面的所有链接,以帮助你创建一个网站地图的web应用程序。而使用Python则可以很快的帮助你开发出一个爬虫脚本. 你可以创建一个爬虫脚本通过href标签对请求的响应内容进行解析,并且可以在解析的同时创建一个新的请求,你还可以直接调用spider模块来实现,这样就不需要自己去写