
简介
Botsonar 一款企业使用的反爬虫管理平台。该平台集爬虫发现,策略,防御,流量分析于一体,目前处于 Alpha 测试版本,开源测试版本为旁路分析模式。
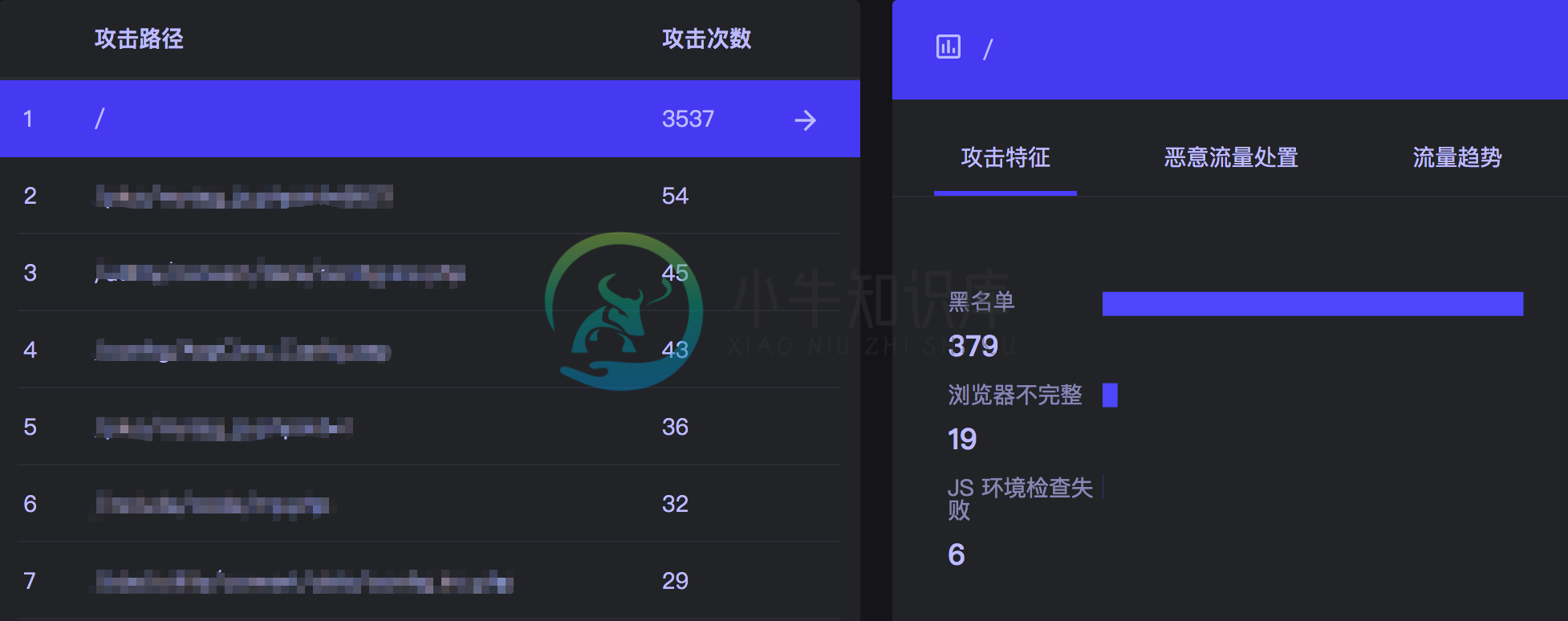
站点概览
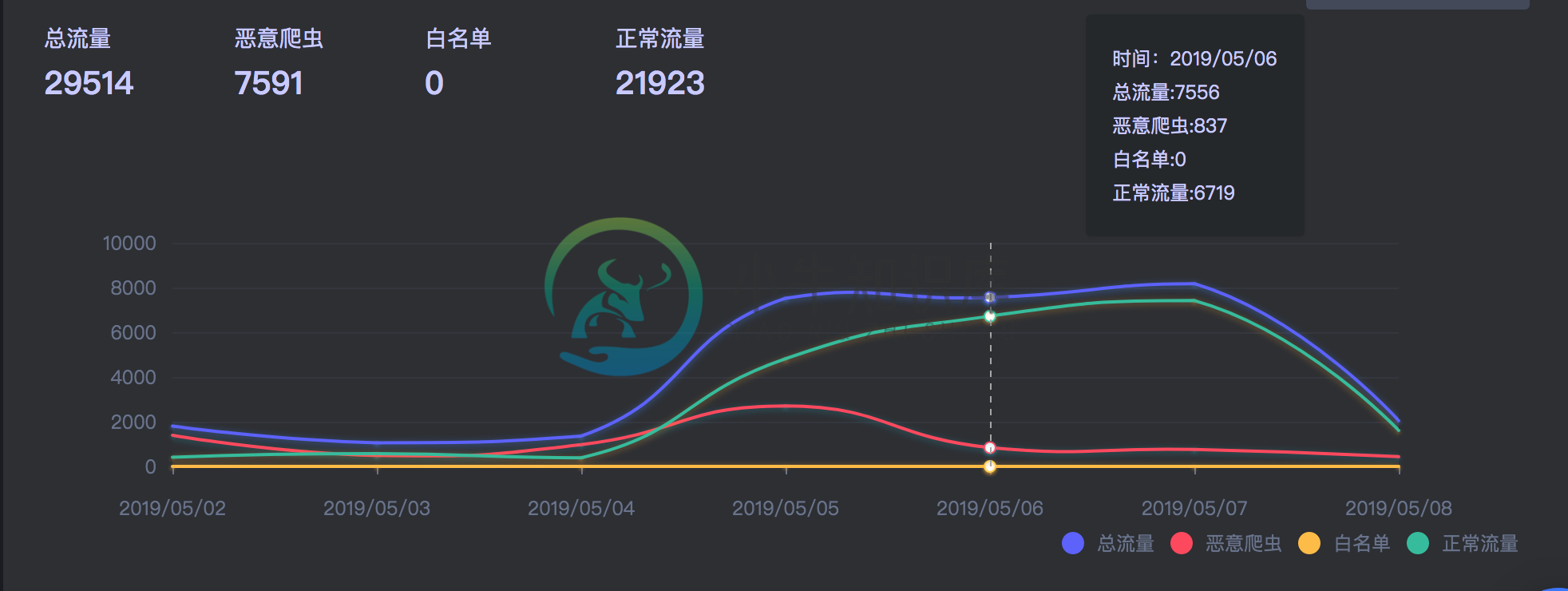
防御和威胁分类
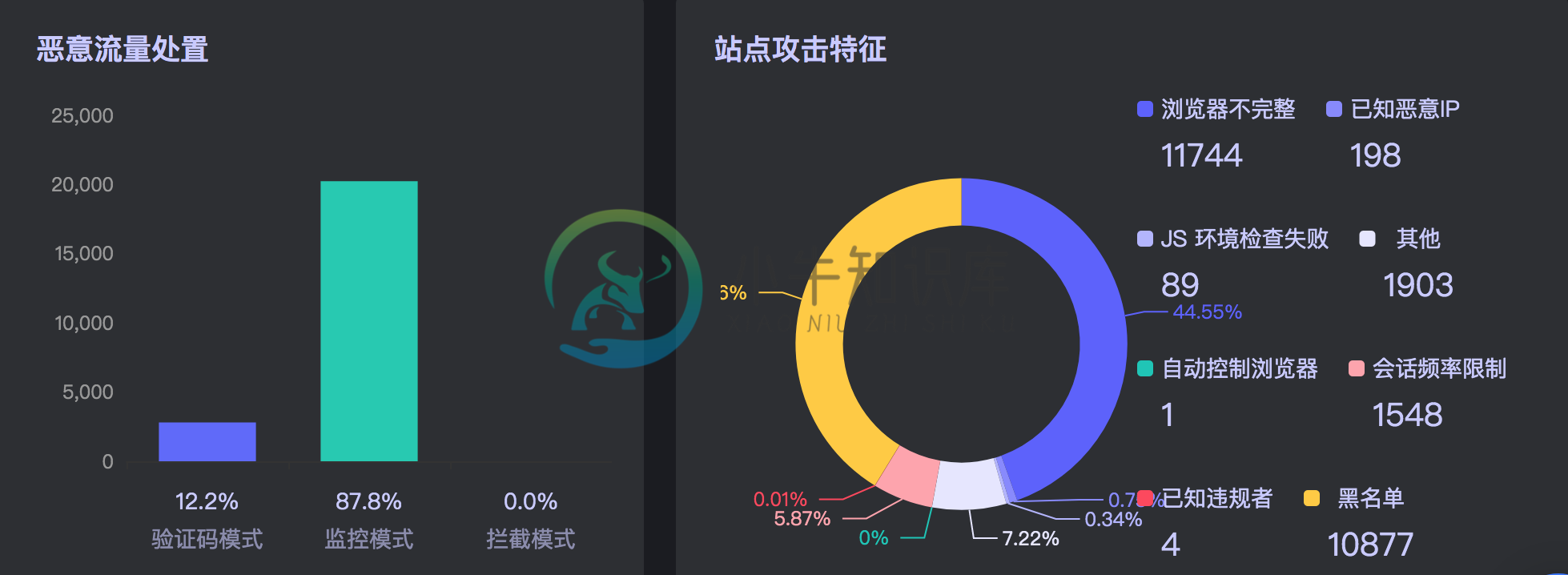
攻击 IP 详情
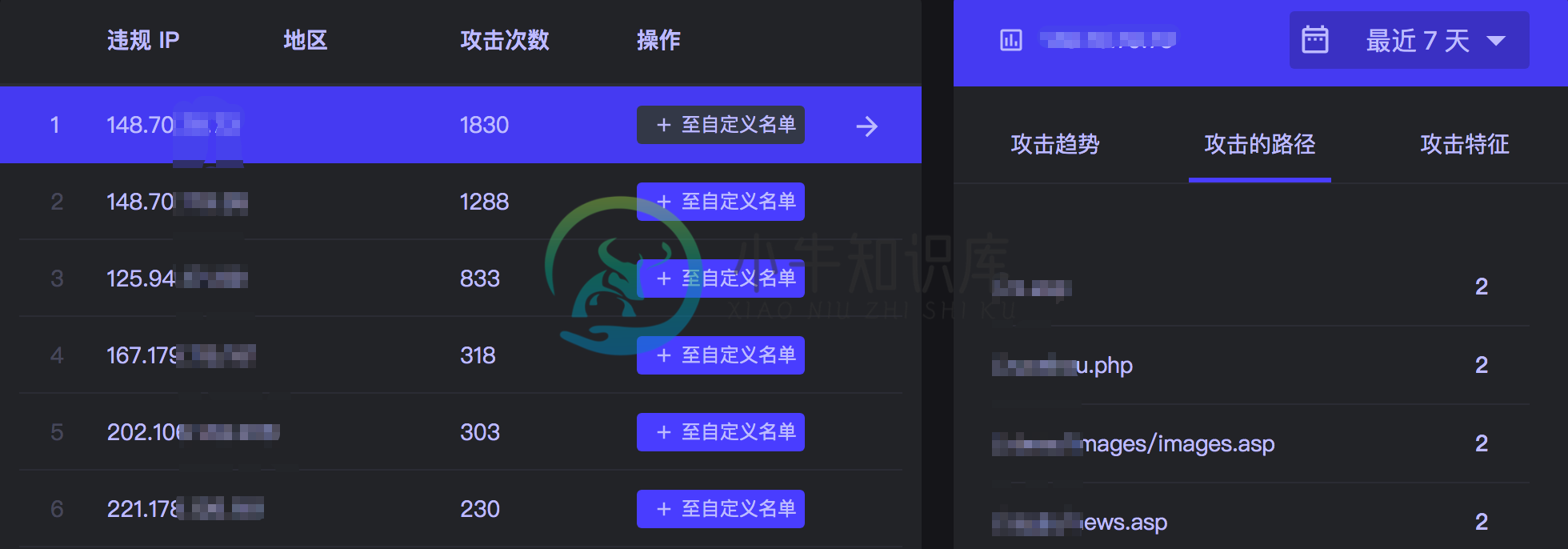
访问路径
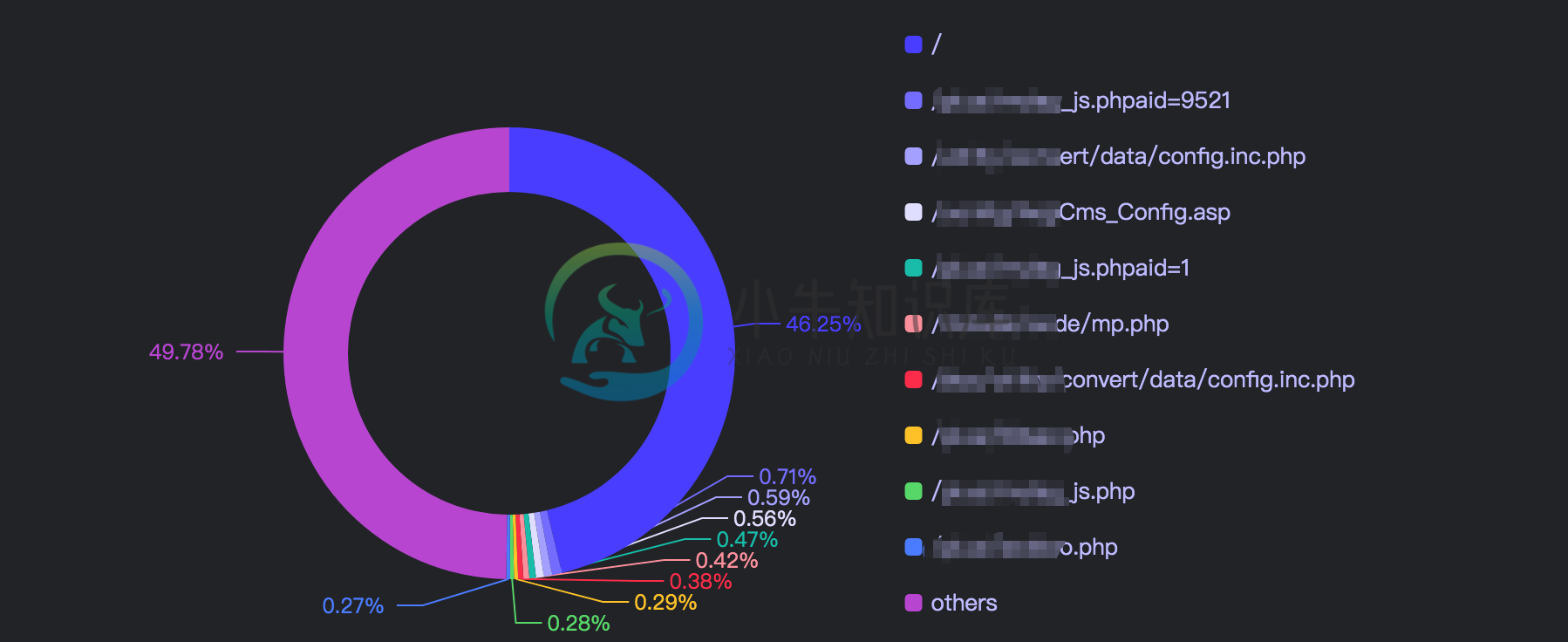
路径威胁详情
特性
- 全站流量统计
- IP 攻击分类
- 搜索引擎自动放行
- 威胁类型分类
- 验证码推送支持
- IP、Country、UA 策略
- 会话频率限制
- Javascript 检查
- 黑产 IP
- 共享白名单
- 机房 IP 分析
- 数据投毒
- 监控模式
- 企业级 JS 加密方案
- 鼠标轨迹 CNN 模型
- 动态 URL 接口
如何开始
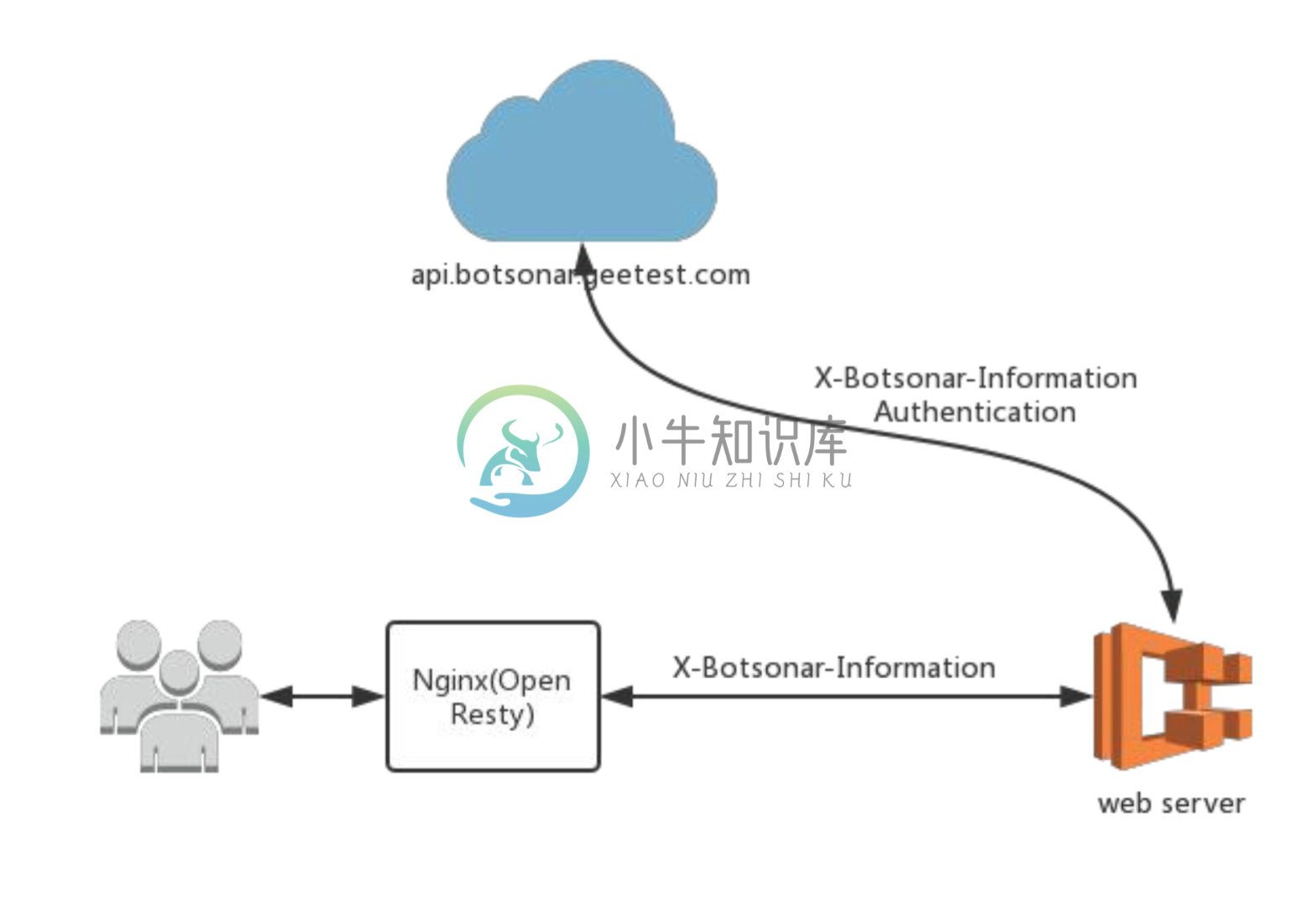
本次 Alpha 版本开源的是旁路分析模型,其接入方式是使用 Openresty 插件集成。
插件使用方法请移步至 openresty lua plugin
旁路分析工作模型
API 文档请参考 api.md
内部原理
反爬虫内部使用了四层流量监测模型:
- 设备环境检测
- 风险 IP 库
- 网络风险探测
- 时序轨迹 AI 模型
判别流程如下:
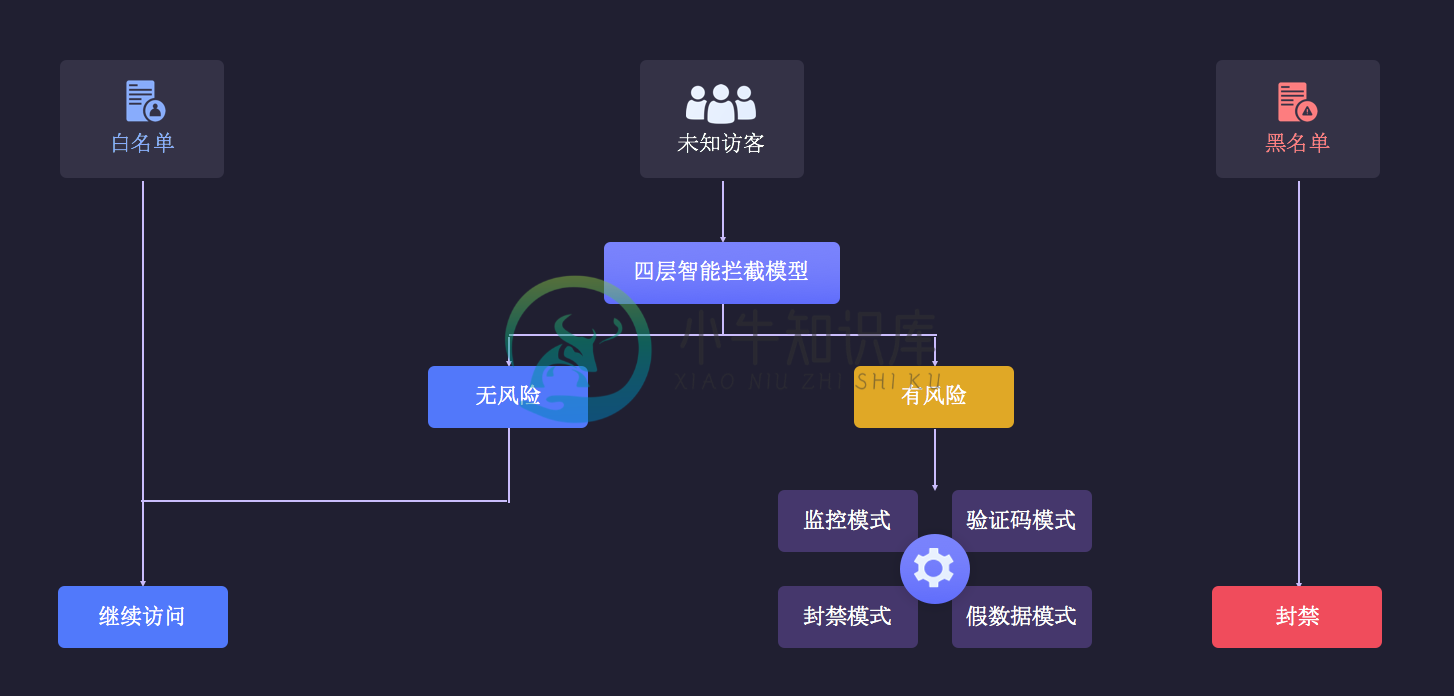
判别流程:
- 用户自定义黑白名单
- 公共 IP 风险库
- 四层拦截模型
- 用户策略处理(监控、验证码、拦截、假数据)
正式测试
旁路分析模型目前只利用了用户后端的数据日志进行流量的判别分析,没有集成用户设备环境检测功能。
需要测试的用户请按照下面的信息模板发送邮件至管理邮箱:botsonar@geetest.com ,我们会提供测试使用的 token,测试期间完全免费。
邮件主题: [反爬虫测试] 申请旁路测试
- 网站归属:个人 /团体 /企业
- 网站域名:请填写真实有效的站点,不然无法认证通过
- 测试时间:请说明想要测试的周期
- 个人联系方式:选填
- 备注信息:
工作日期间正常处理邮件,尽量工作时间申请,token 申请完成后,有效期内无需更换,请个人自行保留有效 token,不要重复申请。
-
有的时候,当我们的爬虫程序完成了,并且在本地测试也没有问题,爬取了一段时间之后突然就发现报错无法抓取页面内容了。这个时候,我们很有可能是遇到了网站的反爬虫拦截。 我们知道,网站一方面想要爬虫爬取网站,比如让搜索引擎爬虫去爬取网站的内容,来增加网站的搜索排名。另一方面,由于网站的服务器资源有限,过多的非真实的用户对网站的大量访问,会增加运营成本和服务器负担。 因此,有些网站会设置一些反爬虫的措施。我
-
本文向大家介绍Python反爬虫伪装浏览器进行爬虫,包括了Python反爬虫伪装浏览器进行爬虫的使用技巧和注意事项,需要的朋友参考一下 对于爬虫中部分网站设置了请求次数过多后会封杀ip,现在模拟浏览器进行爬虫,也就是说让服务器认识到访问他的是真正的浏览器而不是机器操作 简单的直接添加请求头,将浏览器的信息在请求数据时传入: 打开浏览器--打开开发者模式--请求任意网站 如下图:找到请求的的名字,打
-
本文向大家介绍关于爬虫和反爬虫的简略方案分享,包括了关于爬虫和反爬虫的简略方案分享的使用技巧和注意事项,需要的朋友参考一下 前言 爬虫和反爬虫日益成为每家公司的标配系统。 爬虫在情报获取、虚假流量、动态定价、恶意攻击、薅羊毛等方面都能起到很关键的作用,所以每家公司都或多或少的需要开发一些爬虫程序,业界在这方面的成熟的方案也非常多。 有矛就有盾,每家公司也相应的需要反爬虫系统来达到数据保护、系统稳定
-
这一章将会介绍使用一些新的模块(optparse,spider)去完成一个爬虫的web应用。爬虫其实就是一个枚举出一个网站上面的所有链接,以帮助你创建一个网站地图的web应用程序。而使用Python则可以很快的帮助你开发出一个爬虫脚本. 你可以创建一个爬虫脚本通过href标签对请求的响应内容进行解析,并且可以在解析的同时创建一个新的请求,你还可以直接调用spider模块来实现,这样就不需要自己去写
-
根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种. 通用爬虫 通用网络爬虫 就是 捜索引擎抓取系统,目的是将互联网上的所有的网页下载到本地,形成一个互联网内容的镜像备份。 它决定着整个搜索引擎内容的丰富性和时效性,因此它的性能优劣直接影响着搜索引擎的效果。 通用搜索引擎(Search Engine)工作原理 第一步:抓取网页 搜索引擎网络爬虫的基本工作流程如下: 首先选取一部分的初始UR
-
爬虫项是什么呢?比如采集文章列表、文章详情页,他们都是不同的采集项。 定义示例: 继承Yurun\Crawler\Module\Crawler\Contract\BaseCrawlerItem类。 <?php namespace Yurun\CrawlerApp\Module\YurunBlog\Article; use Imi\Bean\Annotation\Bean; use Yurun\C
-
每天,来自商业、社会以及我们的日常生活所产生「图像、音频、视频、文本、定位信息」等各种各样的海量数据,注入到我们的万维网(WWW)、计算机和各种数据存储设备,其中万维网则是最大的信息载体。
-
本文向大家介绍java能写爬虫程序吗,包括了java能写爬虫程序吗的使用技巧和注意事项,需要的朋友参考一下 我们经常会使用网络爬虫去爬取需要的内容,提到爬虫,可能大家伙都会想到python,其实除了python,还有java。java的编程语言简单规范,是很好的爬虫工具。而且java爬虫的语言运行速度比python快,另外,java的多线程是可以利用多核的。 1、java为什么可以应用于网络爬虫?