
简介
Sylph 被定位为大数据生态中的一站式流计算平台,您可以使用它来开发、管理、监控、运维您的流计算.
什么没看懂? 没关系apache-hive您总听过吧?(如果依然不知道,那么您最先需要看下最基础的hadoop三件套Hdfs,Yarn,Hive(MapReduce))
hive将您编写的hive-sql转换成分布式MR批计算Job(默认engine),然后自动在Hadoop-Yarn上执行,那么Sylph就是将Stream-Sql转换成分布式(Flink,…)流计算Job,然后同样自动在Hadoop-Yarn上执行,
您可以形象的把它比喻为Stream-Hive
demo
我们来看一个简单导航demo:
-- 注册json解析 udf create function get_json_object as 'ideal.sylph.runner.flink.udf.UDFJson'; -- 定义数据流接入 create input table topic1( _topic varchar, _key varchar, _message varchar, _partition integer, _offset bigint ) with ( type = 'kafka', kafka_topic = 'TP_A_1,TP_A_2', "auto.offset.reset" = latest, kafka_broker = 'localhost:9092', kafka_group_id = 'streamSql_test1' ); -- 定义数据流输出位置 create output table event_log( key varchar, user_id varchar, event_time bigint ) with ( type = 'hdfs', -- write hdfs hdfs_write_dir = 'hdfs:///tmp/test/data/xx_log', eventTime_field = 'event_time', format = 'parquet' ); -- 描述计算逻辑 insert into event_log select _key,get_json_object(_message, 'user_id') as user_id, cast(get_json_object(_message, 'event_time') as bigint) as event_time from topic1
快速了解
快速两部了解sylph两步走:
+ 第一步: 您只需编写好Stream Sql,然后Sylph会编译您的sql,将其翻译成具体的物理计算引擎
+ 第二步: 然后你接下来只需点击任务上线,然后sylph就会将这个分布式流计算任务提交到Hadoop-Yarn上运行。 ok到此,你的大数据分布式流计算程序已经上线了,接下来您可以直接在sylph的代理页面查看您的job, 了解下参数情况等,可以在这里管理和杀死job。
对了如果您的分布式job挂了,那么sylph还会尝试重新期待并恢复它。
简要设计
下面我将列出一些主要的特性, 这里先简单看下sylph的设计:
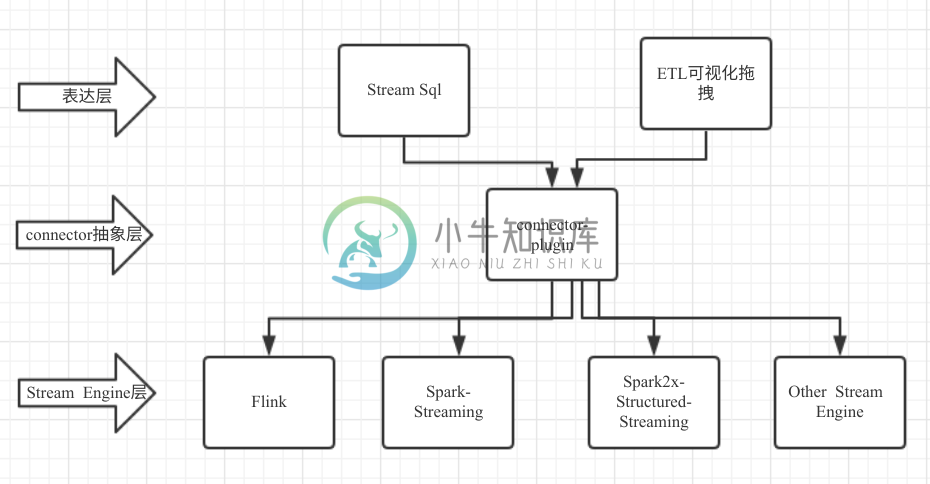
特性盘点:
-
1, 如上所诉您已经出窥了一些sylph一站式方面的特性
-
2, Stream SQL支持
-
3, connector-plugin层提供统一抽象层,随着时间推移我们会有非常多稳定connector供你选择,如果您选择自己编码那么您的代码逻辑甚至无需做改动,就可以同时支持Flink,Spark等引擎
-
4, Stream SQL支持支持Watermark技术,注:Apache Flink-Table-SQL目前还不支持
-
5, 支持批流维表join(俗称打宽),注: Apache Flink-Table-SQL目前还不支持
-
6, Stream SQL支持同时支持基于Prscess Time和 Event Time两种语义进行计算,注:Apache Flink-Table-SQL目前还不支持
写给未来:
未来我们会添加local模式,on ks8等模式,因为一站式的原因,您甚至无做任何业务代码修改就可以非常容易进行过渡和升级,并且local模式可能会在没有hadoop的边缘计算场景中带来价值.
此致:
最后欢迎您的阅读!
-
SYLPH 是一个用于实时流计算的平台,核心是通过工作流描述构建分布式流计算应用程序。,SYLPH是一套完整的解决方案,主要包括: 开发工具:webUI, 定义streamSql或streamETl任务 运行时:基于spark2.x及flink1.5+ , 依赖hdfs和yarn pipline插件扩展: java8, 按需实现source,transform,sink 基础运维:在webUI完成
-
快速入门 下面将以StreamSql为实例,一步步地搭建出一个 分布式流计算应用,让你能快速的入门 SYLPH。 StreamSql是完全通过类sql来描述整个流计算的过程。主要需要描述: 数据源如何接入、如何计算、如何输出到外部存储; 例如计算每分钟的pv; 每5秒更新一次最近一分钟的uv。 demo1 下面例子演示将kafka topic TP_A_1,TP_A_2的数据实时写入mysql表m
-
Sylph 是一个一站式的大数据流计算平台,通过编译Stream SQL,sylph会自动生成Apache Flink等分布式程序到Apache Yarn集群运行。 Sylph地址:https://github.com/harbby/sylph/ 以下开发基于Sylph 0.5.0版本 开发目标:由于当前Sylph提供的数据流接入类型仅有kafka及一个test类型,希望可以支持从hdfs接入数据
-
一站式大数据流计算平台Sylph 0.6预览版,开始全面支持SPARK流计算引擎 简介 Sylph 是一个一站式的大数据流计算平台,通过编译Stream SQL,sylph会自动生成Apache Flink等分布式程序到Apache Yarn集群运行。 通过它您只需编写Stream SQL,即可完成常见流计算快速开发、部署、运维、监控。 0.6 特性预览 1. 支持将Stream SQL编
-
1.个人推荐sylph 人不多,但是回复 2.AthenaX 没有联系方式,只能自己看源码值得推荐的这2个的单元测试都非常多
-
我有这个模式 列表表 [{“movie_id”:100,“gene1”:“犯罪”,“计数”:1,“id”:100},{“movie_id”:141267,“gene1”:“犯罪”,“计数”:1,“id”:141267},{“movie_id”:207932,“gene1”:“犯罪”,“计数”:1,“id”:207932},{“movie_id”:238636,“gene1”:“惊悚”,“计数”:1
-
先面试,过了之后给的笔试题 先自我介绍一下吧一一基本信息+和职位相关的专业能力+项目经验+表达自职位符合自己的职业规划 你刚刚说的参与的项目,你是怎么参与进去的? 你是怎么当的组长? 你在项目中遇到了什么挑战、你怎么去和组员一起解决的、最后你学到了什么 你在项目中有组员不按时完成他的工作内容吗,你是怎么解决的是自己去帮他做完吗? 后来你们还有合作吗? xx省博物馆项目中,我看到你说你做了3套方案,
-
我试图做以下java分配和每件事似乎工作正常,除了当我把一个数字 谢谢 赋值:创建一个询问考试结果并计算成绩平均值的程序。成绩是4到10之间的浮点数。程序要求成绩,直到键入负数。如果用户给出的分数不是4到10之间的数字,则文本“无效成绩!”将在屏幕上打印,程序要求另一个分数。最后,程序在屏幕上打印输入的成绩数及其平均值,如示例打印所示。如果没有输入成绩,通知“您没有输入任何成绩。”是屏幕上唯一打印
-
问题内容: 编辑:我已经写了平均的代码,但我不知道如何使它也使用从我的args.length而不是数组的整数 我需要编写一个Java程序,该程序可以计算:1.读入的整数数2.平均值-不必是整数! 注意!我不想从数组中计算平均值,但是要在args中计算整数。 目前我已经写了这个: 谁能指导我正确的方向?还是举个例子,以书面形式指导我塑造这段代码? 提前致谢 问题答案: 只需对您的代码进行一些小的修改
-
如何使用约束流api计算员工的公平性。 https://www.optaplanner.org/blog/2017/02/03/FormulaForMeasuringUnfairness.html 我在网球求解器示例中看到了上述流口水的实现。 https://github.com/kiegroup/optaplanner/blob/581d10fb8140f37b7491d06b2bab8d5ac
-
我读了Java8API中关于流抽象的内容,但我不太理解这句话: 当筛选操作创建一个新流时,该流是否包含已筛选的元素?它似乎理解了流只有在遍历时才包含元素,即使用终端操作。但是,than,什么包含过滤后的流?我糊涂了!!!