
Airflow 被 Airbnb 内部用来创建、监控和调整数据管道。任何工作流都可以在这个使用 Python 编写的平台上运行(目前加入 Apache 基金会孵化器)。
Airflow 允许工作流开发人员轻松创建、维护和周期性地调度运行工作流(即有向无环图或成为DAGs)的工具。在Airbnb中,这些工作流包括了如数据存储、增长分析、Email发送、A/B测试等等这些跨越多部门的用例。这个平台拥有和 Hive、Presto、MySQL、HDFS、Postgres和S3交互的能力,并且提供了钩子使得系统拥有很好地扩展性。除了一个命令行界面,该工具还提供了一个 基于Web的用户界面让您可以可视化管道的依赖关系、监控进度、触发任务等。
Airflow 包含如下组件:
一个元数据库(MySQL或Postgres)
一组Airflow工作节点
一个调节器(Redis或RabbitMQ)
一个Airflow Web服务器
截图:

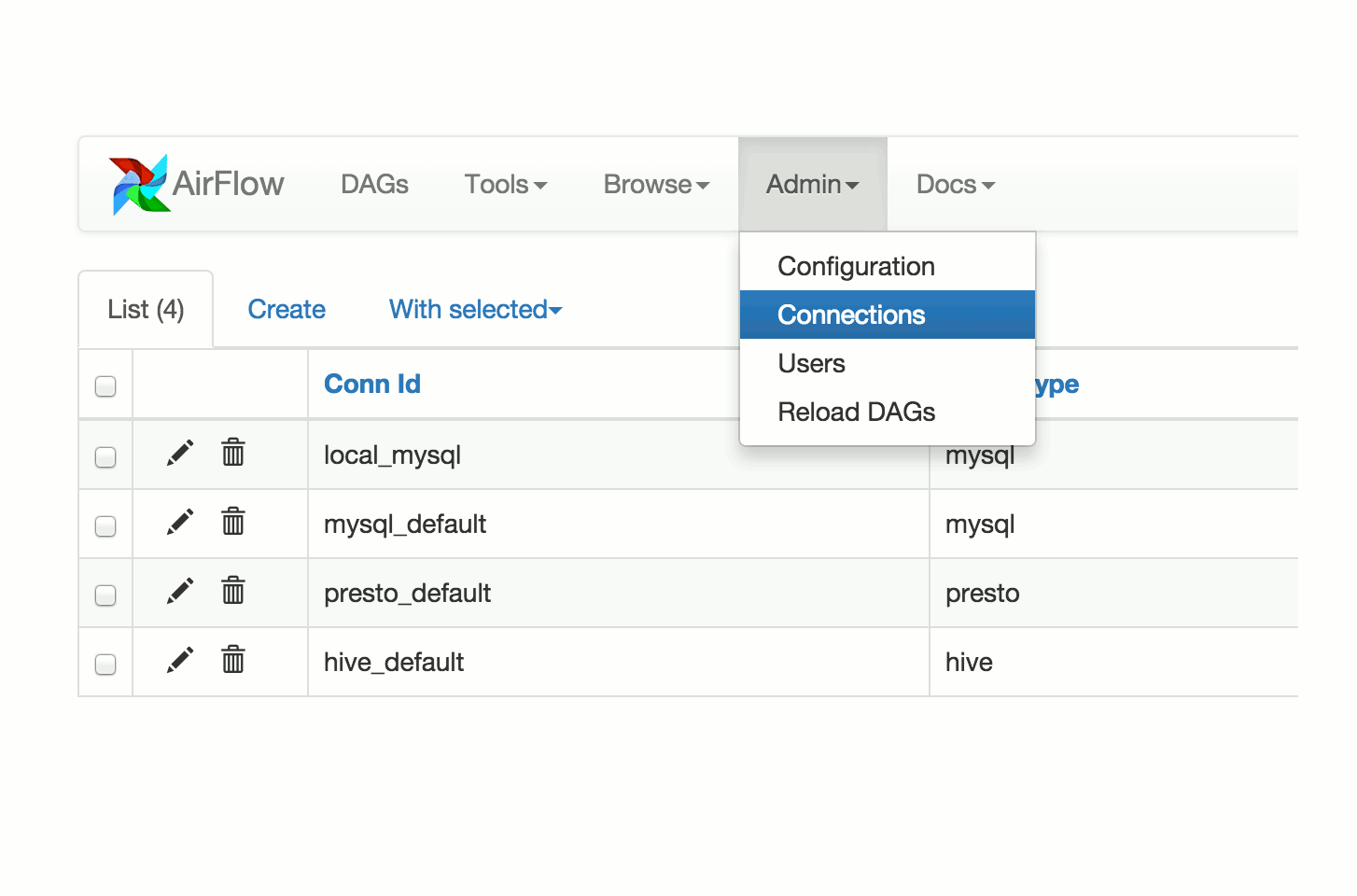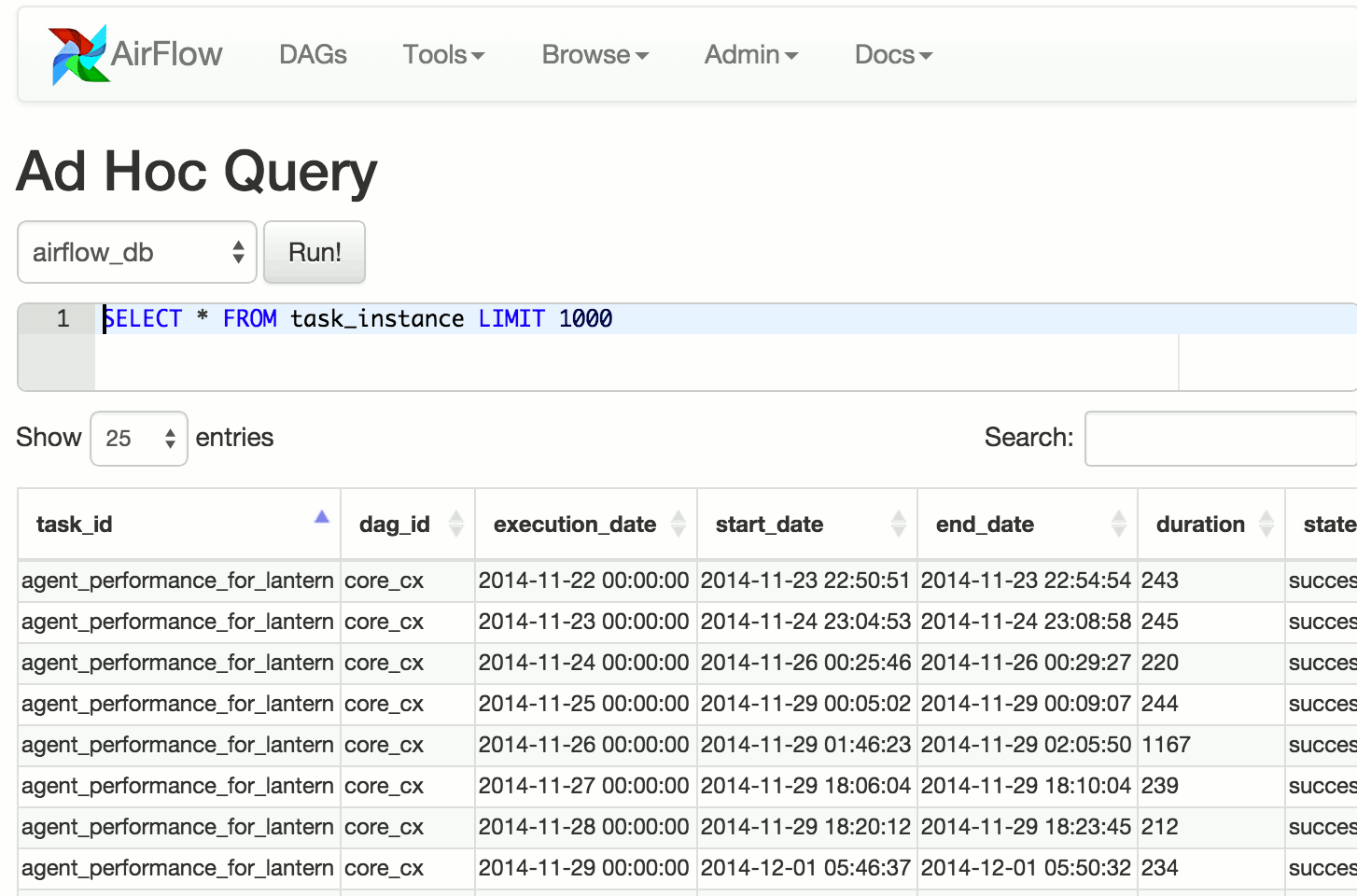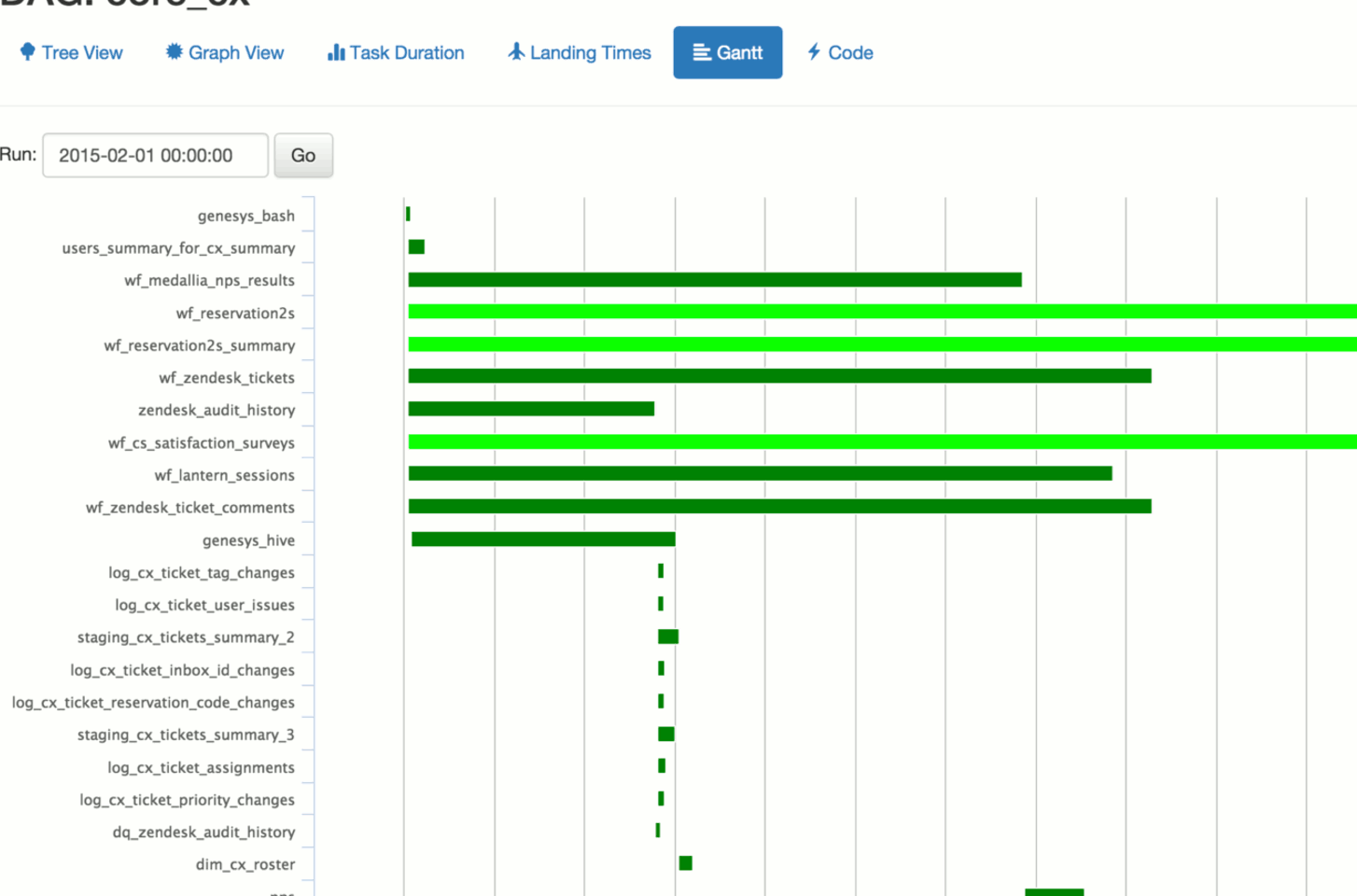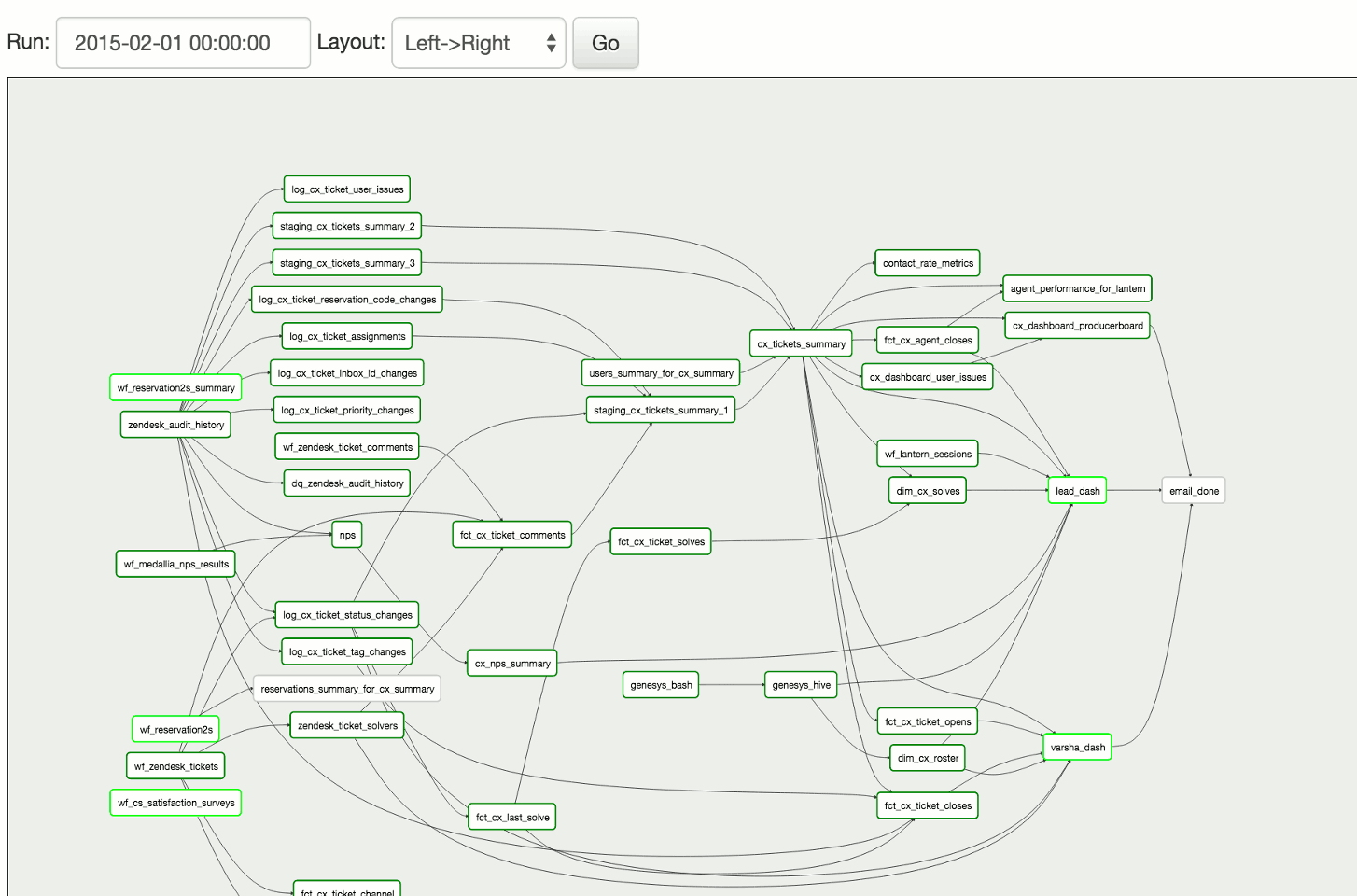
管道定义示例:
"""
Code that goes along with the Airflow tutorial located at:
https://github.com/airbnb/airflow/blob/master/airflow/example_dags/tutorial.py
"""
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2015, 6, 1),
'email': ['airflow@airflow.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
}
dag = DAG('tutorial', default_args=default_args)
# t1, t2 and t3 are examples of tasks created by instantiating operators
t1 = BashOperator(
task_id='print_date',
bash_command='date',
dag=dag)
t2 = BashOperator(
task_id='sleep',
bash_command='sleep 5',
retries=3,
dag=dag)
templated_command = """
{% for i in range(5) %}
echo "{{ ds }}"
echo "{{ macros.ds_add(ds, 7)}}"
echo "{{ params.my_param }}"
{% endfor %}
"""
t3 = BashOperator(
task_id='templated',
bash_command=templated_command,
params={'my_param': 'Parameter I passed in'},
dag=dag)
t2.set_upstream(t1)
t3.set_upstream(t1)-
棱镜七彩安全预警 近日网上有关于开源项目Apache Airflow Hive Provider命令注入漏洞,棱镜七彩威胁情报团队第一时间探测到,经分析研判,向全社会发起开源漏洞预警公告,提醒相关安全团队及时响应。 项目介绍 Apache Airflow 是一个用于以编程方式创作、安排和监控工作流平台。Apache Airflow Hive Provider 是一个使用 SQL 读取、写入和管理分
-
这一节将简述监管背后的概念、原语及语义。要了解这些如何转换成真实代码,请参阅相关的Scala和Java API章节。 监管的意思 在 Actor 系统 中说过,监管描述的是actor之间的依赖关系:监管者将任务委托给下属,并相应地对下属的失败状况进行响应。当一个下属出现了失败(即抛出一个异常),它自己会将自己和自己所有的下属挂起,然后向自己的监管者发送一个提示失败的消息。基于所监管的工作的性质和失
-
Tsar 介绍 Tsar是淘宝的一个用来收集服务器系统和应用信息的采集报告工具,如收集服务器的系统信息(cpu,mem等),以及应用数据,收集到的数据存储在服务器磁盘上,可以随时查询历史信息,也可以将数据发送到nagios报警。 Tsar能够比较方便的增加模块,只需要按照tsar的要求编写数据的采集函数和展现函数,就可以把自定义的模块加入到tsar中 Tsar 安装 开源版 #git clone
-
Sentinel 提供对所有资源的实时监控。如果需要实时监控,客户端需引入以下依赖(以 Maven 为例): <dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-transport-simple-http</artifactId> <version>x.y.z</version> </de
-
系统搭建好了,应该如何用起来,这节给大家逐步介绍一下 我们说agent只要部署到机器上,并且配置好了heartbeat和transfer就自动采集数据了,我们就可以去dashboard上面搜索监控数据查看了。dashboard是个web项目,浏览器访问之。左侧输入endpoint搜索,endpoint是什么?应该用什么搜索?对于agent采集的数据,endpoint都是机器名,去目标机器上执行ho
-
1. ngxtop ngxtop是一款用python编写的类top的监控nginx信息的工具。它就像top一样,可以实时地监控nginx的访问信息。 2. 安装 在ubuntu下是这样安装的。 sudo pip install ngxtop 如果没有装pip,可以用下面的命令安装。 sudo apt-get install python-pip 3. 用法 直接输入命令就可以了。 ngxtop 效
-
AWS Data Pipeline是一种Web服务,旨在使用户能够更轻松地集成跨多个AWS服务的数据,并从单个位置对其进行分析。 使用AWS Data Pipeline,可以从源访问数据,进行处理,然后将结果有效地传输到相应的AWS服务。 如何设置数据管道? 以下是设置数据管道的步骤 - Step 1 - 使用以下步骤创建管道。 登录AWS账户。 使用此链接打开AWS Data Pipeline控
-
本文向大家介绍服务器中一般要监控哪些数据,如何监控的,怎么从监控数据中发现问题?相关面试题,主要包含被问及服务器中一般要监控哪些数据,如何监控的,怎么从监控数据中发现问题?时的应答技巧和注意事项,需要的朋友参考一下 基础监控和应用监控。 基础监控包括机器是否死机,cpu,内存,磁盘使用率等;应用监控包括日志监控、端口监控、进程数监控等。
-
Java Management Extensions(JMX)提供了一种监视和管理应用程序的标准机制。 默认情况下,Spring Boot将管理端点公开为org.springframework.boot域下的JMX MBean。 5.4.1 自定义MBean名称 MBean的名称通常是从端点的id生成的。 例如,运行状况端点公开为org.springframework.boot:type = En