
Apache Kylin 是一个开源的分布式的 OLAP 分析引擎,来自 eBay 公司开发,基于 Hadoop 提供 SQL 接口和 OLAP 接口,支持 TB 到 PB 级别的数据量。
Apache Kylin 的商业支持请访问 http://kyligence.io/
Apache Kylin 是:
-
超级快的 OLAP 引擎,具备可伸缩性
-
为 Hadoop 提供 ANSI-SQL 接口
-
交互式查询能力
-
MOLAP Cube
-
可与其他 BI 工具无缝集成,如 Tableau,而 Microstrategy 和 Excel 将很快推出
其他值得关注的特性包括:
-
作业管理和监控
-
压缩和编码的支持
-
Cube 的增量更新
-
Leverage HBase Coprocessor for query latency
-
Approximate Query Capability for distinct Count (HyperLogLog)
-
易用的 Web 管理、构建、监控和查询 Cube 的接口
-
Security capability to set ACL at Cube/Project Level
-
支持 LDAP 集成
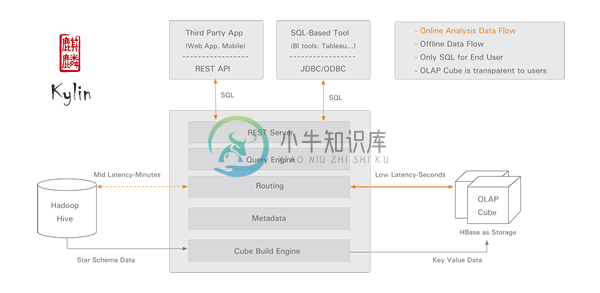
运行环境要求:
Hadoop
-
Hadoop: 2.2.0.2.0.6.0-61 or above
-
Hive: 0.12.0.2.0.6.0-61 or above
-
HBase: 0.96.0.2.0.6.0-61-hadoop2
Tested with Hortornworks distribution (HDP2.1.3), not tested with others yet.
Kylin Server
-
Command hadoop, hive, hbase is workable on your hadoop cluster
-
JDK Runtime: JDK7 (OpenJDK or Oracle JDK)
-
Maven
-
Git
-
Tomcat
-
Mysql
-
前言 本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和文献引用请见1000个问题搞定大数据技术体系 正文 Apache Kylin 的使命 Apache Kylin 的使命是超高速的大数据 OLAP ( OnlineAnalyticalProcessing ),也就是要让大数据分析像使用数据库一样简单迅
-
整理了下近期比较优秀的关于Apache Kylin的实践和博客: Apache Kylin在百度地图的实践 http://www.infoq.com/cn/articles/practis-of-apache-kylin-in-baidu-map 摘要:百度基于Kylin的二次开发管理监控系统以及Cube优化 Apache Kylin在云海的实践 http://www.csdn.net/artic
-
kylin安装文档 hadoop spark安装参看这篇 https://blog.csdn.net/longgelaile/article/details/78424474 安装apache-kylin-2.0.0-bin-hbase098.tar.gz 去官网自行下载安装包 linux版本centos 安装版本kylin2.0.0版本 hbase 0.98.6 hive版本apache-hiv
-
查询数据,Apache Kylin支持这三种方式 坚持原创,写好每一篇文章 我们都知道,Apache Kylin的数据来源除了从Hive这些软件导入之外,还支持Rest API,JDBC、OJBC等数据来源,这篇文章我们讲讲这部分内容。 Rest请求 传统的数据库在查询的时候查询结果是以列表的形式展示,而Apache Kylin支持的查询结果的形式可以以折线图、柱状图和饼状图等多种形式展示。这些查
-
Apache Kylin(包括孪生产品Kyligence)是由国人主导的开源大数据OLAP引擎。这是一款优点和缺点都很明显的产品。 简史 2013年中,ebay中国开启了一个OLAP-on-Hadoop项目,用以解决BI-on-Hadoop的性能问题。 2014年9月,正式命名为kylin并在ebay内部上线 2014年10月1号,kylin发布到github,正式开源 2014年11月,加入ap
-
网站是否具有吸引力对于访客的回头率具有非常重要的促进作用,从吸引力分析中了解访客喜好,增加网站吸引力从而提升用户粘性。
-
主要内容:一、InnoDB启动,二、源码分析,三、总结一、InnoDB启动 在MySql中,InnoDB的启动流程其实是很重要的。一些更细节的问题,就藏在了这其中。在前面分析过整个数据库启动的流程,本篇就具体分析一下InnoDB引擎启动所做的各种动作。在这期间,分析一下对数据库索引的处理过程。在前面的分析中已经探讨过,今天重点分析一下数据引擎的启动和加载流程。 在MySql中,方向是朝着插件化发展,所以InnoDB本身也是做为一个插件进行引用的。通过
-
本文向大家介绍深入分析PHP引用(&),包括了深入分析PHP引用(&)的使用技巧和注意事项,需要的朋友参考一下 引用是什么 在 PHP 中引用意味着用不同的名字访问同一个变量内容。这并不像 C 的指针,替代的是,引用是符号表别名。注意在 PHP 中,变量名和变量内容是不一样的,因此同样的内容可以有不同的名字。最接近的比喻是 Unix 的文件名和文件本身——变量名是目录条目,而变量内容则是文件本身。
-
我用cmd删除了映射 在我的配置文件中,我定义了如下索引:, 并尝试创建一个新的映射,但我得到了错误 {“error”:{“root_cause”:[{“type”:“index_not_found_exception”,“reason”:“no-this index”,“resource.type”:“index_or_alias”,“resource.id”:“logstash_log*”,“
-
本文向大家介绍MySQL索引用法实例分析,包括了MySQL索引用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了MySQL索引用法。分享给大家供大家参考,具体如下: MYSQL描述: 一个文章库,里面有两个表:category和article。category里面有10条分类数据。article里面有20万条。article里面有一个"article_category"字段是与c
-
本文向大家介绍C#引用访问权限分析,包括了C#引用访问权限分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了C#引用访问权限问题。分享给大家供大家参考。具体分析如下: 同样代码表现的不同行为: 创建基类(Super)和派生类(Sub)每个类有一个字段field和一个公共方法getField,并且使用内联的方式初始化为1,方法getField返回字段field。C#和Java代码及运行
-
本文向大家介绍浅谈MySQL索引优化分析,包括了浅谈MySQL索引优化分析的使用技巧和注意事项,需要的朋友参考一下 为什么你写的sql查询慢?为什么你建的索引常失效?通过本章内容,你将学会MySQL性能下降的原因,索引的简介,索引创建的原则,explain命令的使用,以及explain输出字段的意义。助你了解索引,分析索引,使用索引,从而写出更高性能的sql语句。还在等啥子?撸起袖子就是干! 案例
-
一、创建索引: 在SQLite中,创建索引的SQL语法和其他大多数关系型数据库基本相同,因为这里也仅仅是给出示例用法: sqlite> CREATE TABLE testtable (first_col integer,second_col integer); --创建最简单的索引,该索引基于某个表的一个字段。 sqlite> CREATE INDEX testtable_idx ON test