
Gather Platform 数据抓取平台是一套基于 Webmagic 内核的,具有 Web 任务配置和任务管理界面的数据采集平台,一个轻量级的搜索引擎系统。具有以下功能
-
根据配置的模板进行数据采集
-
对采集的数据进行NLP处理,包括:抽取关键词,抽取摘要,抽取实体词
-
自定义任务循环执行周期,一次定义,无人值守,自动采集
-
在不配置采集模板的情况下自动检测网页正文,自动抽取文章发布时间
-
动态字段抽取与静态字段植入
-
已抓取数据的管理,包括:搜索,增删改查,按照新的数据模板重新抽取数据
-
多数据输出方式:Elasticsearch、JSON文本,Redis
5分钟即可部署完毕,半分钟即可完成一个爬虫,开始数据采集. 不需要进行任何编码就可以完成一个功能强大的爬虫.
爬虫模板配置页面
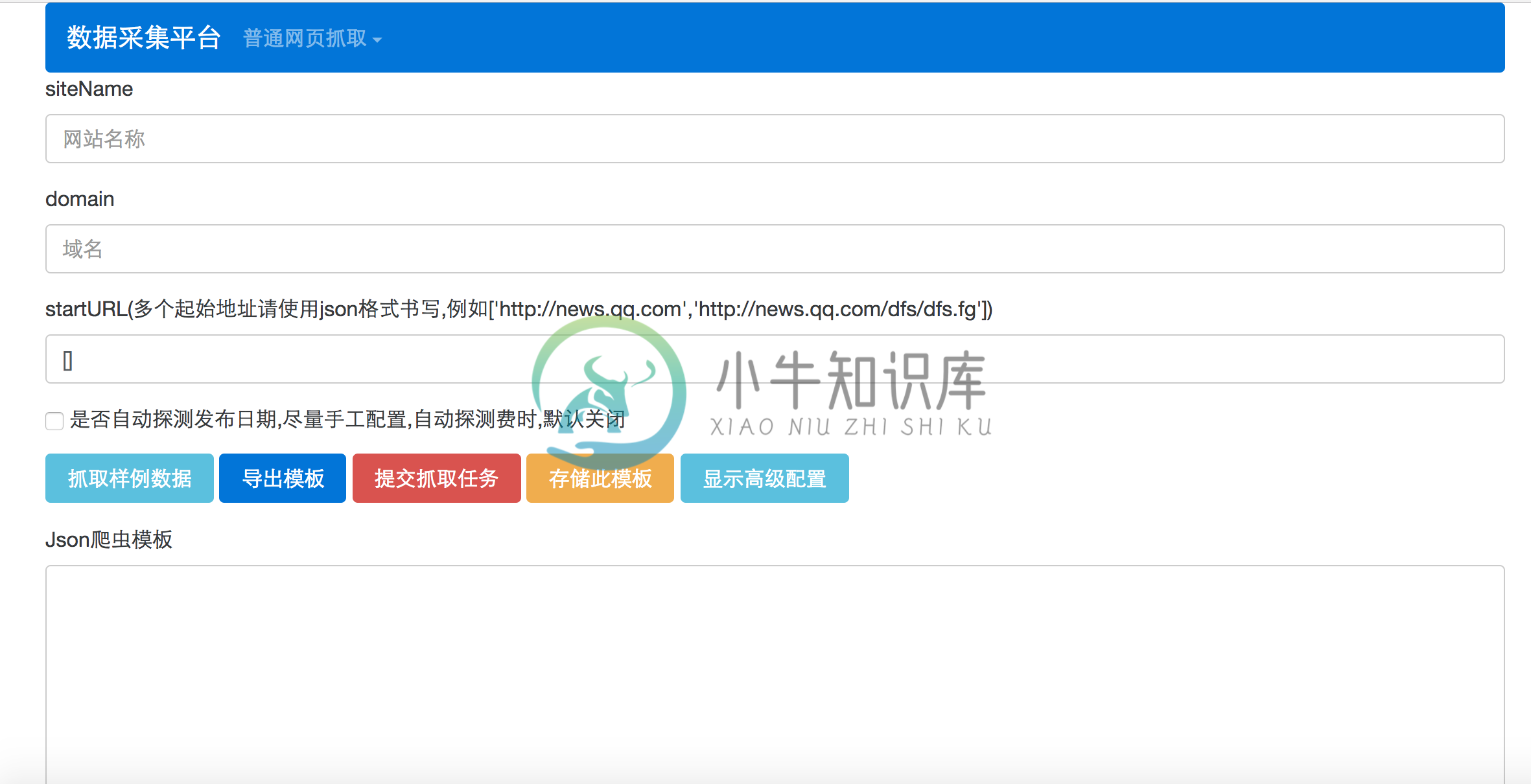
抓取样例数据效果
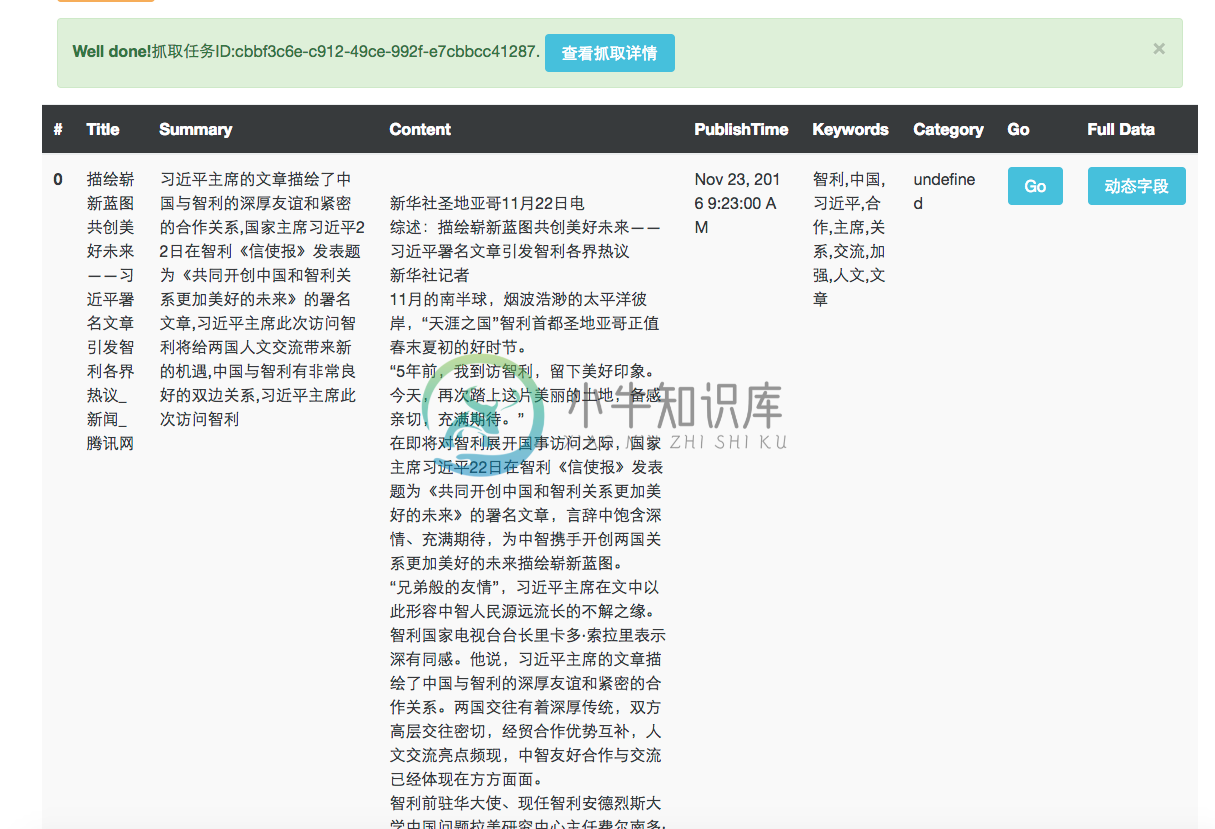
爬虫管理页面
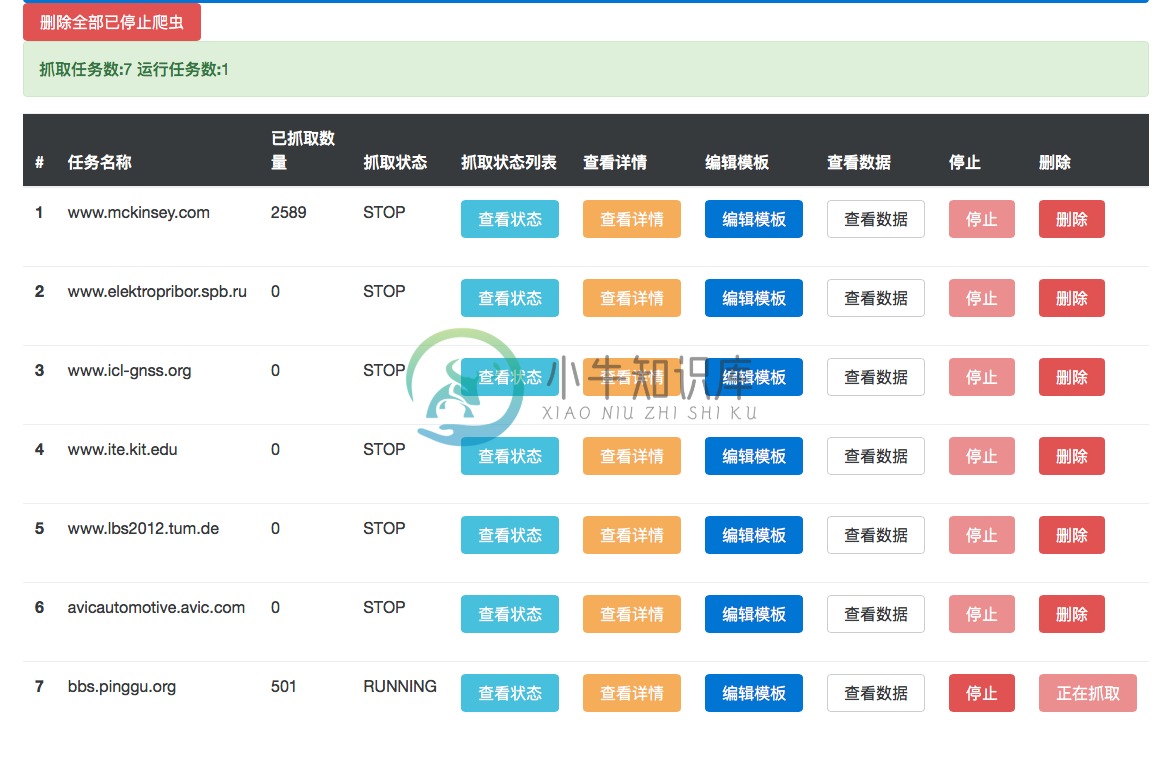
循环任务监测

数据搜索与管理页面
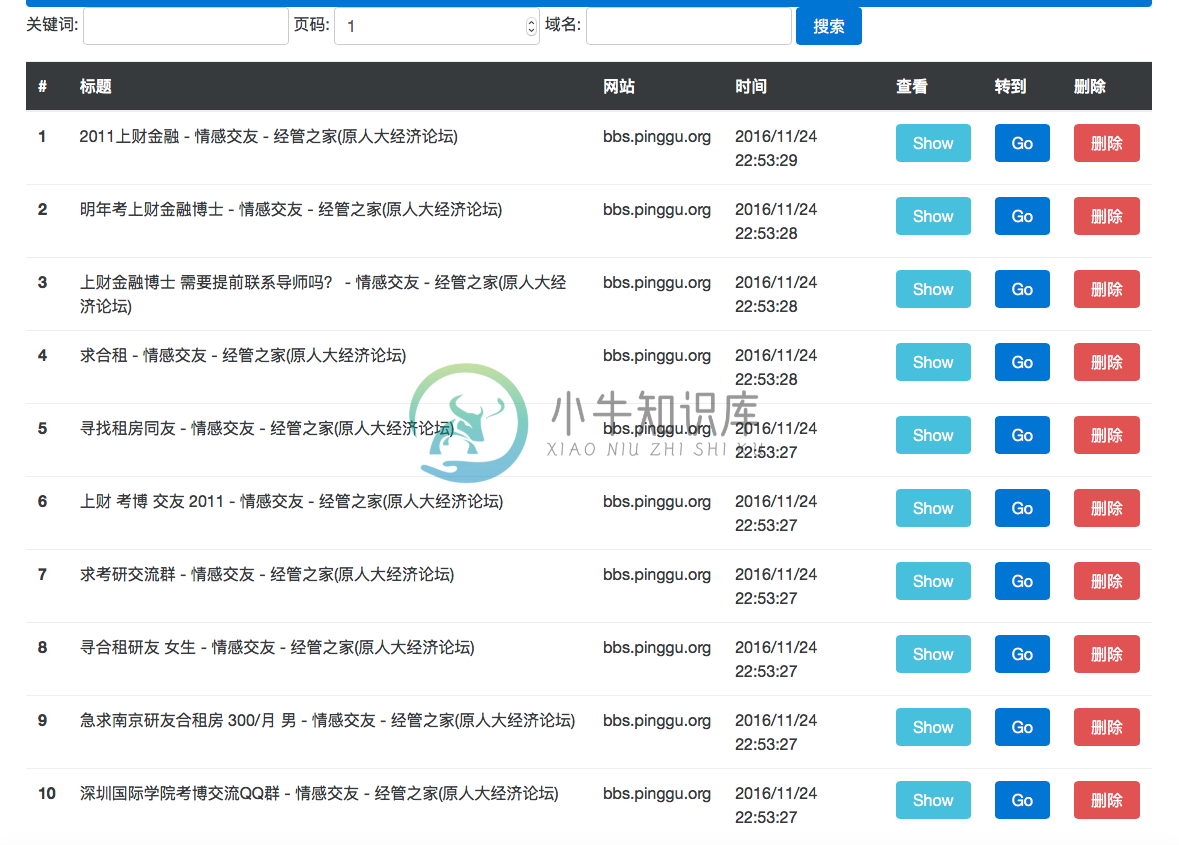
网页信息查看
关联信息页
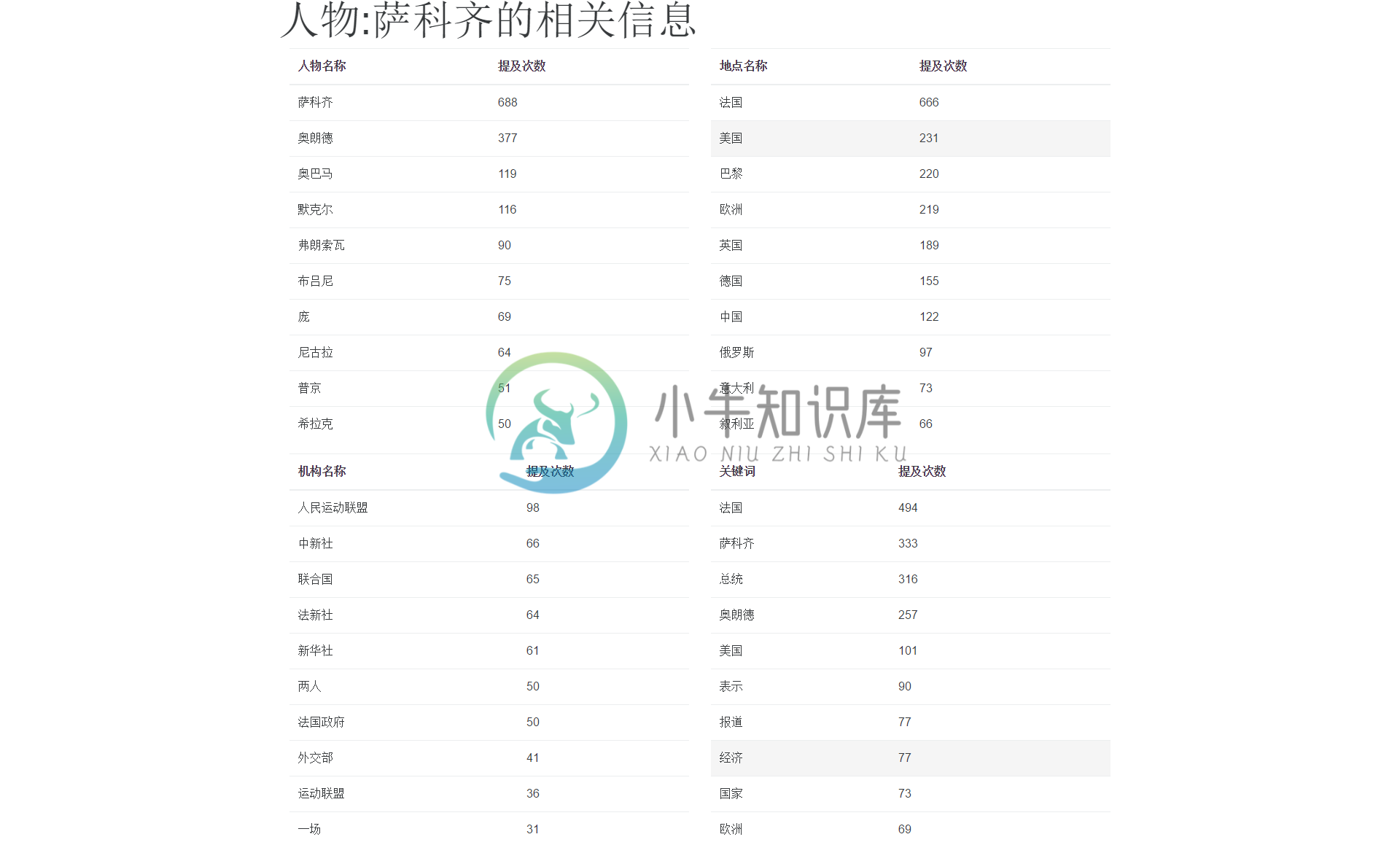
根据域名统计数据页面
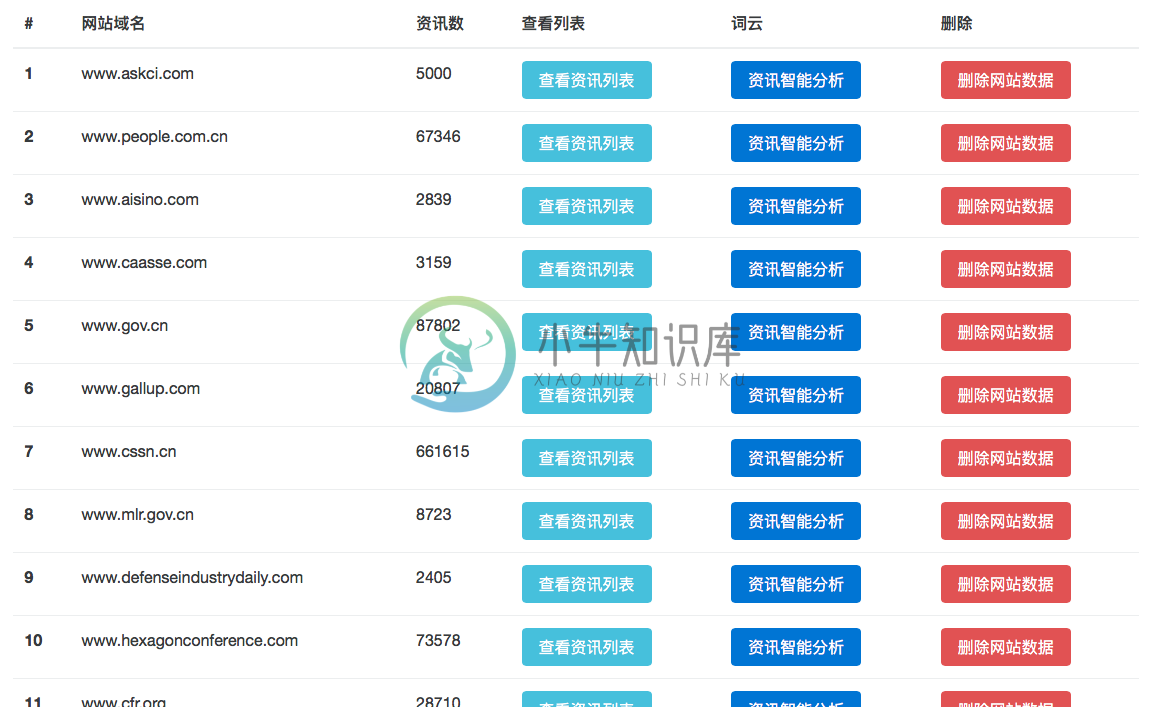
具体部署方式参考项目主页README
百度云下载链接密码: v3jm
-
我试图学习如何用python编写asnycron编程,并编写了一个小tornado应用程序,它用sleep命令执行两个asnycron循环。 如果我用两个await命令等待两个协程,那么它的行为与预期的一样(第一个循环,而不是第二个循环被执行) 如果我将这两个协同路径与聚集结合在一起,则什么都不会发生。(没有错误,没有打印输出,Web请求从未完成。) 我不明白*await gather发生了什么(
-
《OpenShift / RHEL / DevSecOps / Ansible 汇总目录》 请参考 《Ansible Automation Platform - 功能构成》一文了解什么是 Ansible Navigator 和 Execution Environment。 安装最新版 Ansible Navigator Ansible Navigator 需要本地有 docker 或 podman
-
Applies to: Oracle Database - Personal Edition - Version 10.1.0.2 to 11.2.0.3 [Release 10.1 to 11.2] Oracle Database - Enterprise Edition - Version 10.1.0.2 to 11.2.0.3 [Release 10.1 to 11.2] Oracle D
-
集群结构 较大的集群都会设计单独的登录节点,用户只能ssh到登录节点,不能直接ssh到集群的任何主节点和计算节点。同时配置用户在计算节点之间的ssh互信,为了并行作业的运行。 登录节点也安装LSF,配置为LSF 静态Client或者MXJ值为0,也即不运行作业的客户端。集群的WEB节点与办公访问局域网一个网段。如需使用浮动client,主节点网卡需要 单纯LSF环境(命令行提交) LSF+PA
-
希望各路好汉走过路过给点意见!!! 在做Tensorflow Object detection API的时候,想要把训练好的模型转换为.pb文件,在执行转换程序export_inference_graph.py的时候,出现了AttributeError: module 'tensorflow' has no attribute 'batch_gather'这个问题。我的操作系统是WIN10,另外t
-
个人总结各个平台的收集系统日志方法,在排错或者诊断 ASM/ASM lib问题的时候用到.上传给oracle support还没有做过. How To Gather The OS Logs For Each Specific OS Platform. [ID 1349613.1] Modified 29-AUG-2011 Type HOWTO Status PUBLISHED
-
数据库报错 GATHER_STATS_JOB encountered errors. Check the trace file. Errors in file /opt/oracle/diag/rdbms/dbserver1/dbserver1/trace/dbserver1_j003_10544.trc: ORA-20011: Approximate NDV failed: ORA-01476
-
一、在alert.log文件中發現如下錯誤 : *** 2013-06-01 10:00:13.500 DBMS_STATS: GATHER_STATS_JOB: GATHER_TABLE_STATS('"SYS"','"ALERT_HUMAN2"','""', ...) DBMS_STATS: ORA-20011: Approximate NDV failed: ORA-29913: 執行 OD
-
In this Document Goal Solution Quick Recreate Recommendation Important Notes Regarding the Gathering of Optimizer Statistics Gathering Object statistics Use a large enough sample size Ga
-
In this Document Goal Solution References APPLIES TO: Oracle Server - Enterprise Edition - Version: 9.0.1.4 to 9.2.0.8 - Release: 9.0.1 to 9.2 Information in this document applies to any platfor
-
In this Document Goal Solution References APPLIES TO: Oracle Database - Personal Edition - Version 10.1.0.2 to 10.2.0.5 [Release 10.1 to 10.2] Oracle Database - Standard Edition - Version 10.1.0
-
In this Document Goal Solution References APPLIES TO: Oracle Database - Enterprise Edition - Version 12.1.0.1 and later Oracle Database - Standard Edition - Version 12.1.0.1 and later Oracle Dat
-
已采集数据 所有入库成功或失败的数据都被记录在此,用于网址排重,防止重复采集
-
引入Hubble SDK包,按照业务需求通过代码埋入相关数据,这种是常规的,也是推荐的方式。这里不做详细描述,具体的使用方式请参考SDK使用文档,目前HubbleData支持SDK: iOS SDK Android SDK JS SDK)使用说明 JAVA SDK 微信小程序 SDK 打通App与H5 如果遇到HubbleData不支持的数据类型,推荐使用接口数据发送方式。
-
统计支持您根据自己的业务场景需求(如考虑隐私相关条款)设置对单一设备开启或关闭数据采集。 当您判断该设备不应该进行数据采集时,可以通过设置不调用该设备的startWithAppId接口即可实现数据采集关闭
-
统计支持您根据自己的业务场景需求(如考虑隐私相关条款)设置对单一设备开启或关闭数据采集。 当您判断该设备不应该进行数据采集时,可以通过设置不调用该设备的初始化函数,从而实现关闭该设备的数据采集。具体来说。 如果您使用的是无埋点SDK:执行屏蔽调用 StatService.autoTrace API 即可; 如果您使用的是手动埋点版本:执行屏蔽调用StatService.start API,此外,如
-
作为监控系统来讲,首先得有监控数据,然后才能做后面的分析处理、绘图报警等事情,那falcon是如何处理数据采集这个问题的呢? 我们先要考虑有哪些数据要采集,脑洞打开~ 机器负载信息,这个最常见,cpu.idle/load.1min/mem.memfree.percent/df.bytes.free.percent等等 硬件信息,比如功耗、风扇转速、磁盘是否可写,系统组同学对这些比较关注 服务监控数
-
作为监控系统来讲,首先得有监控数据,然后才能做后面的分析处理、绘图报警等事情,那falcon是如何处理数据采集这个问题的呢? 我们先要考虑有哪些数据要采集,脑洞打开~ 机器负载信息,这个最常见,cpu.idle/load.1min/mem.memfree.percent/df.bytes.free.percent等等 硬件信息,比如功耗、风扇转速、磁盘是否可写,系统组同学对这些比较关注 服务监控数
-
使用指南 - 统计设置 - 其它设置 - 如何关闭数据采集 网站统计支持您根据自己的业务场景需求(如考虑隐私相关条款)设置对单个站点关闭数据采集,如下所示: // 关闭数据采集 _hmt.push(['_setAutoTracking'], false); 如需重新开启数据采集,则把false修改为true即可。
-
数据采集也即埋点,它是精细化分析的第一步。数据的准确性、可扩展性以及技术人员的高效性依次被视为数据采集的三大要点。埋点,保证了数据的准确性;事件、属性、值的结构保证了数据的可扩展性;埋点文档也保证了团队成员协同的高效性。 为了帮助诸葛io的客户能够准确、高效的采集数据,我们建议您: 一、数据分析需求梳理 数据采集切忌大而全,产品不断迭代,数据分析的需求也是随着产品不断迭代的,明确长远阶段和当前阶段