
python编程实现希尔排序

观察一下”插入排序“:其实不难发现她有个缺点:
如果当数据是”5, 4, 3, 2, 1“的时候,此时我们将“无序块”中的记录插入到“有序块”时,估计俺们要崩盘,每次插入都要移动位置,此时插入排序的效率可想而知。
shell根据这个弱点进行了算法改进,融入了一种叫做“缩小增量排序法”的思想,其实也蛮简单的,不过有点注意的就是:
增量不是乱取,而是有规律可循的。
希尔排序时效分析很难,关键码的比较次数与记录移动次数依赖于增量因子序列d的选取,特定情况下可以准确估算出关键码的比较次数和记录的移动次数。目前还没有人给出选取最好的增量因子序列的方法。增量因子序列可以有各种取法,有取奇数的,也有取质数的,但需要注意:增量因子中除1 外没有公因子,且最后一个增量因子必须为1。希尔排序方法是一个不稳定的排序方法。
首先要明确一下增量的取法(这里图片是copy别人博客的,增量是奇数,我下面的编程用的是偶数):
第一次增量的取法为: d=count/2;
第二次增量的取法为: d=(count/2)/2;
最后一直到: d=1;
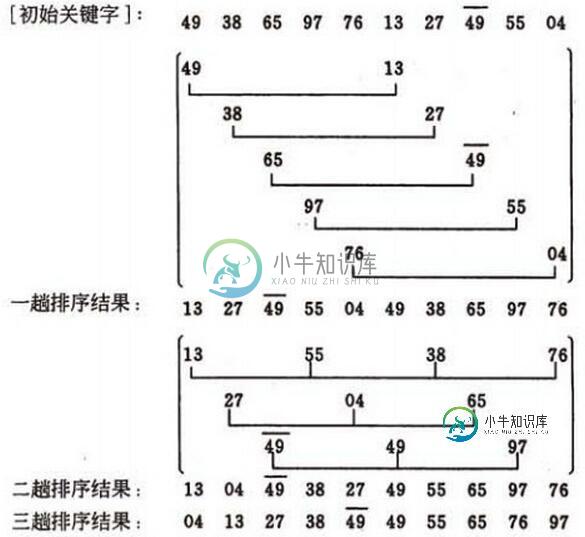
好,注意看图了,第一趟的增量d1=5, 将10个待排记录分为5个子序列,分别进行直接插入排序,结果为(13, 27, 49, 55, 04, 49, 38, 65, 97, 76)
第二趟的增量d2=3, 将10个待排记录分为3个子序列,分别进行直接插入排序,结果为(13, 04, 49, 38, 27, 49, 55, 65, 97, 76)
第三趟的增量d3=1, 对整个序列进行直接插入排序,最后结果为(04, 13, 27, 38, 49, 49, 55, 65, 76, 97)
重点来了。当增量减小到1时,此时序列已基本有序,希尔排序的最后一趟就是接近最好情况的直接插入排序。可将前面各趟的"宏观"调整看成是最后一趟的预处理,比只做一次直接插入排序效率更高。
本人是学python的,今天用python实现了希尔排序。
def ShellInsetSort(array, len_array, dk): # 直接插入排序 for i in range(dk, len_array): # 从下标为dk的数进行插入排序 position = i current_val = array[position] # 要插入的数 index = i j = int(index / dk) # index与dk的商 index = index - j * dk # while True: # 找到第一个的下标,在增量为dk中,第一个的下标index必然 0<=index<dk # index = index - dk # if 0<=index and index <dk: # break # position>index,要插入的数的下标必须得大于第一个下标 while position > index and current_val < array[position-dk]: array[position] = array[position-dk] # 往后移动 position = position-dk else: array[position] = current_val def ShellSort(array, len_array): # 希尔排序 dk = int(len_array/2) # 增量 while(dk >= 1): ShellInsetSort(array, len_array, dk) print(">>:",array) dk = int(dk/2) if __name__ == "__main__": array = [49, 38, 65, 97, 76, 13, 27, 49, 55, 4] print(">:", array) ShellSort(array, len(array))
输出:
>: [49, 38, 65, 97, 76, 13, 27, 49, 55, 4]
>>: [13, 27, 49, 55, 4, 49, 38, 65, 97, 76]
>>: [4, 27, 13, 49, 38, 55, 49, 65, 97, 76]
>>: [4, 13, 27, 38, 49, 49, 55, 65, 76, 97]
首先你得先会插入排序,不会你必然看不懂。
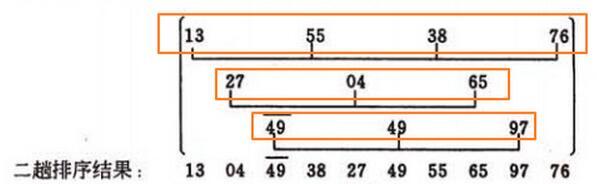
插入排序,即是对上图三个黄色框中的数进行插入排序。举个例子:13,55,38,76
直接看55,55<13, 不用移动。接着看38,38<55,那么55后移,数据变为[13,55,55,76],接着比较13<38, 那么38替换55,变成[13,38,55,76]。其它同理,略。
这里有个问题,比如第二个黄色框[27,4,65],4<27, 那27往后移,接着4就替换第一个,数据变成[4,27,65],但是计算机怎么知道4就是在第一个啊??
我的做法是,先找出[27,4,65]第一个数的下标,在这个例子中27的下标为1。当要插入的数的下标大于第一个下标1时,才可以往后移,前一个数不可以往后移有两种情况,一种是前面有数据,且小于要插入的数,那你只能插在它后面。另一种,很重要,当要插入数比前面所有数都小时,那插入数肯定是放在第一个,此时要插入数的下标=第一个数的下标。(这段话,感觉初学者应该不大懂……)
为了找到第一个数的下标,最开始想的是用循环,一直到最前面:
while True: # 找到第一个的下标,在增量为dk中,第一个的下标index必然 0<=index<dk index = index - dk if 0<=index and index <dk: break
在Debug时,发现用循环太浪费时间了,特别是当增量d=1时,直接插入排序为了插入列表最后一个数,得循环减1,直到第一个数的下标,后来我学聪明了,用下面的方法:
j = int(index / dk) # index与dk的商 index = index - j * dk
时间复杂度:
希尔排序的时间复杂度是所取增量序列的函数,尚难准确分析。有文献指出,当增量序列为d[k]=2^(t-k+1)时,希尔排序的时间复杂度为O(n^1.5), 其中t为排序趟数。
稳定性: 不稳定
希尔排序效果:
参考资料: 编程是我自己实现的。建议Debug看看运行过程
c++中八大排序算法
视觉直观感受若干常用排序算法
C#七大经典排序算法系列(下)
1.非系统的学习也是在浪费时间 2.做一个会欣赏美,懂艺术,会艺术的技术人
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍java实现希尔排序算法,包括了java实现希尔排序算法的使用技巧和注意事项,需要的朋友参考一下 希尔排序算法的基本思想是:先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为dl的倍数的记录放在同一个组中。先在各组内进行直接插人排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在
-
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。 希尔排序是基于插入排序的以下两点性质而提出改进方法的: 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率; 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位; 希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“
-
1. 前言 本节内容是排序算法系列之一:希尔排序,主要讲解了希尔排序的主体思路,选取了一个待排序的数字列表对希尔排序算法进行了演示,给出了希尔排序算法的 Java 代码实现,帮助大家可以更好的理解希尔排序算法。 2. 什么是希尔排序? 希尔排序(Shell Sort),是计算机科学与技术领域中较为简单的一种排序算法。 希尔排序是插入排序的一种,有时候也被称为 “缩小增量排序”。它是插入排序的改进版
-
希尔排序(有时称为“递减递增排序”)通过将原始列表分解为多个较小的子列表来改进插入排序,每个子列表使用插入排序进行排序。 选择这些子列表的方式是希尔排序的关键。不是将列表拆分为连续项的子列表,希尔排序使用增量i(有时称为 gap),通过选择 i 个项的所有项来创建子列表。 这可以在 Figure 6 中看到。该列表有九个项。如果我们使用三的增量,有三个子列表,每个子列表可以通过插入排序进行排序。完
-
主要内容:序列的划分方法,希尔排序算法的具体实现前面给大家介绍了 插入排序算法,通过将待排序序列中的元素逐个插入到有序的子序列中,最终使整个序列变得有序。下图所示的动画演示了插入排序的整个过程: 图 1 插入排序算法 观察动画不难发现,插入排序算法是通过比较元素大小和交换元素存储位置实现排序的,比较大小和移动元素的次数越多,算法的效率就越差。 希尔排序算法又叫 缩小增量排序算法,是一种更高效的插入排序算法。和普通的插入排序算法相比,希尔排序算法
-
本文向大家介绍Java 插入排序之希尔排序的实例,包括了Java 插入排序之希尔排序的实例的使用技巧和注意事项,需要的朋友参考一下 Java 插入排序之希尔排序的实例 Java代码 运行后的结果为: Java代码 当分割的间隔为1时,变成了直接插入排序。 感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!