
Python聚类算法之基本K均值实例详解

本文实例讲述了Python聚类算法之基本K均值运算技巧。分享给大家供大家参考,具体如下:
基本K均值 :选择 K 个初始质心,其中 K 是用户指定的参数,即所期望的簇的个数。每次循环中,每个点被指派到最近的质心,指派到同一个质心的点集构成一个。然后,根据指派到簇的点,更新每个簇的质心。重复指派和更新操作,直到质心不发生明显的变化。
# scoding=utf-8
import pylab as pl
points = [[int(eachpoint.split("#")[0]), int(eachpoint.split("#")[1])] for eachpoint in open("points","r")]
# 指定三个初始质心
currentCenter1 = [20,190]; currentCenter2 = [120,90]; currentCenter3 = [170,140]
pl.plot([currentCenter1[0]], [currentCenter1[1]],'ok')
pl.plot([currentCenter2[0]], [currentCenter2[1]],'ok')
pl.plot([currentCenter3[0]], [currentCenter3[1]],'ok')
# 记录每次迭代后每个簇的质心的更新轨迹
center1 = [currentCenter1]; center2 = [currentCenter2]; center3 = [currentCenter3]
# 三个簇
group1 = []; group2 = []; group3 = []
for runtime in range(50):
group1 = []; group2 = []; group3 = []
for eachpoint in points:
# 计算每个点到三个质心的距离
distance1 = pow(abs(eachpoint[0]-currentCenter1[0]),2) + pow(abs(eachpoint[1]-currentCenter1[1]),2)
distance2 = pow(abs(eachpoint[0]-currentCenter2[0]),2) + pow(abs(eachpoint[1]-currentCenter2[1]),2)
distance3 = pow(abs(eachpoint[0]-currentCenter3[0]),2) + pow(abs(eachpoint[1]-currentCenter3[1]),2)
# 将该点指派到离它最近的质心所在的簇
mindis = min(distance1,distance2,distance3)
if(mindis == distance1):
group1.append(eachpoint)
elif(mindis == distance2):
group2.append(eachpoint)
else:
group3.append(eachpoint)
# 指派完所有的点后,更新每个簇的质心
currentCenter1 = [sum([eachpoint[0] for eachpoint in group1])/len(group1),sum([eachpoint[1] for eachpoint in group1])/len(group1)]
currentCenter2 = [sum([eachpoint[0] for eachpoint in group2])/len(group2),sum([eachpoint[1] for eachpoint in group2])/len(group2)]
currentCenter3 = [sum([eachpoint[0] for eachpoint in group3])/len(group3),sum([eachpoint[1] for eachpoint in group3])/len(group3)]
# 记录该次对质心的更新
center1.append(currentCenter1)
center2.append(currentCenter2)
center3.append(currentCenter3)
# 打印所有的点,用颜色标识该点所属的簇
pl.plot([eachpoint[0] for eachpoint in group1], [eachpoint[1] for eachpoint in group1], 'or')
pl.plot([eachpoint[0] for eachpoint in group2], [eachpoint[1] for eachpoint in group2], 'oy')
pl.plot([eachpoint[0] for eachpoint in group3], [eachpoint[1] for eachpoint in group3], 'og')
# 打印每个簇的质心的更新轨迹
for center in [center1,center2,center3]:
pl.plot([eachcenter[0] for eachcenter in center], [eachcenter[1] for eachcenter in center],'k')
pl.show()
运行效果截图如下:
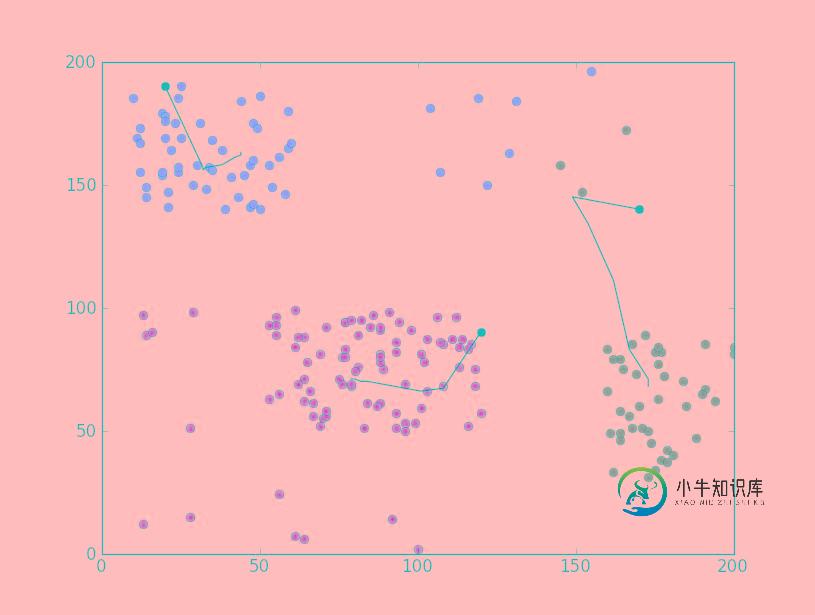
希望本文所述对大家Python程序设计有所帮助。
-
$k$均值聚类算法(k-means clustering algorithm) 在聚类的问题中,我们得到了一组训练样本集 ${x^{(1)},...,x^{(m)}}$,然后想要把这些样本划分成若干个相关的“类群(clusters)”。其中的 $x^{(i)}\in R^n$,而并未给出分类标签 $y^{(i)}$ 。所以这就是一个无监督学习的问题了。 $K$ 均值聚类算法如下所示: 随机初始化(
-
聚类 聚类,简单来说,就是将一个庞杂数据集中具有相似特征的数据自动归类到一起,称为一个簇,簇内的对象越相似,聚类的效果越好。它是一种无监督的学习(Unsupervised Learning)方法,不需要预先标注好的训练集。聚类与分类最大的区别就是分类的目标事先已知,例如猫狗识别,你在分类之前已经预先知道要将它分为猫、狗两个种类;而在你聚类之前,你对你的目标是未知的,同样以动物为例,对于一个动物集来
-
问题内容: 我正在寻找带有示例的k-means算法的Python实现来聚类和缓存我的坐标数据库。 问题答案: 更新:( 在最初回答之后十一年,可能是该进行更新的时候了。) 首先,您确定要使用k均值吗? 该页面很好地总结了一些不同的聚类算法。我建议您在图形之外,特别查看每种方法所需的参数,并确定您是否可以提供所需的参数(例如,k均值需要簇的数量,但是也许您不知道在开始之前就知道了)群集)。 以下是一
-
本文向大家介绍K均值聚类算法的Java版实现代码示例,包括了K均值聚类算法的Java版实现代码示例的使用技巧和注意事项,需要的朋友参考一下 1.简介 K均值聚类算法是先随机选取K个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。一旦全部对象都被分配了,每个聚类的聚类中心会根据聚类中现有的对象被重
-
本文向大家介绍python实现k-means聚类算法,包括了python实现k-means聚类算法的使用技巧和注意事项,需要的朋友参考一下 k-means聚类算法 k-means是发现给定数据集的k个簇的算法,也就是将数据集聚合为k类的算法。 算法过程如下: 1)从N个文档随机选取K个文档作为质心 2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类,我们一般取欧几里得距离 3)重
-
目标 在本章中,我们将了解K-Means聚类的概念,其工作原理等。 理论 我们将用一个常用的例子来处理这个问题。 T-shirt尺寸问题 考虑一家公司,该公司将向市场发布新型号的T恤。显然,他们将不得不制造不同尺寸的模型,以满足各种规模的人们的需求。因此,该公司会记录人们的身高和体重数据,并将其绘制到图形上,如下所示: 公司无法制作所有尺寸的T恤。取而代之的是,他们将人划分为小,中和大,并仅制造这