
Python HTMLTestRunner可视化报告实现过程解析

操作步骤
1.下载HTMLTestRunner.py
2.把文件复制到python安装/lib位置下
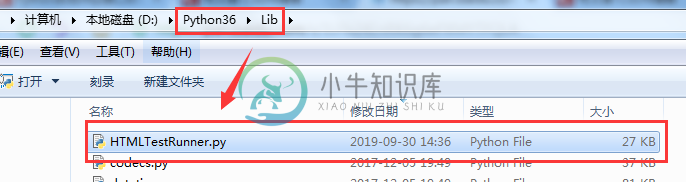 3.
3.
3.导入:import HTMLTestRunner import unittest
4.mian执行:
1.实例化:ts = unittest.TestSuite()
2.按类加载全部testxxx测试用例:ts.addTest(unittest.TestLoader().loadTestsFromTestCase(类名))
按函数加载testxxx测试用例:ts.addTest(类名('函数名'))
3.打开文件位置,如果没有则新建一个文件:filename = open(‘C:\xxx.html','wb')
4.定义报告属性:htmlroport = HTMLTestRunner.HTMLTestRunner(stream=filename,title="标题XXX报告",description='XXX报告XX描述',tester='测试人员XXX')
5.加载执行用例生成报告:htmlroport.run(ts)
举例说明
#!/usr/bin/python3
# encoding:utf-8
'''
Created on 2019年9月30日
@author: EDZ
'''
import unittest
import HTMLTestRunner
import os
import time
class HtmlReport(unittest.TestCase):
def test_1(self):
print('test_1错误')
self.assertEqual(1, 2,'说明错误')
def test_2(self):
print('test_2正确')
self.assertEqual(1, 1)
def test_3(self):
print('test_3错误')
self.assertEqual(2, 3)
if __name__=='__main__':
now = time.strftime("%Y-%m-%d %H%M%S", time.localtime(time.time()))
localpath = os.getcwd()
print('本文件目录位置:'+localpath)
filepath = os.path.join(localpath,'Report',now +'.html')
print('报告存放路径 :'+filepath)
ts = unittest.TestSuite()#实例化
#按类加载全部testxxx测试用例
ts.addTest(unittest.TestLoader().loadTestsFromTestCase(HtmlReport))
#按函数加载testxxx测试用例
#ts.addTest(HtmlReport('test_1'))
#打开文件位置,如果没有则新建一个文件
filename = open(filepath,'wb')
htmlroport = HTMLTestRunner.HTMLTestRunner(stream=filename,title="标题XXX报告",description='XXX报告XX描述',tester='测试人员XXX')
htmlroport.run(ts)
运行结果
本文件目录位置:C:\Users\EDZ\eclipse-workspace\pythonTest
报告存放路径 :C:\Users\EDZ\eclipse-workspace\pythonTest\Report\2019-09-30 >160852.html
F.F
Time Elapsed: 0:00:00.001000
报告截图

拓展方法
result = htmlroport.run(ts)
num1 = result.testsRun # 运行测试用例的总数
num2 = result.success_count # 运行测试用例成功的个数
num3 = result.failure_count # 运行测试用例失败的个数
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍Python爬虫爬取博客实现可视化过程解析,包括了Python爬虫爬取博客实现可视化过程解析的使用技巧和注意事项,需要的朋友参考一下 源码: 爬虫不是重点,只是拿来爬阅读数量,pyecharts是重点 这次爬的是我自己的博客,一共10页,每页10片文章,正好写了100篇博客 pyecharts安装: pip install wheelpip install pyecharts==0.
-
本文向大家介绍java实现可视化日历,包括了java实现可视化日历的使用技巧和注意事项,需要的朋友参考一下 java可视化日历程序,供大家参考,具体内容如下 利用DateFormat以及Calendar等方法来实现。 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
问题内容: 我正在尝试让空手道DSL报告工作,这被证明是一个挑战,因为我的团队使用Circle CI而不是Jenkins。黄瓜报告似乎仅对詹金斯有用。 我在这里查看了此文档: https://github.com/intuit/karate/tree/master/karate-demo#example-report https://github.com/jenkinsci/cucumber-re
-
本文向大家介绍python可视化实现KNN算法,包括了python可视化实现KNN算法的使用技巧和注意事项,需要的朋友参考一下 简介 这里通过python的绘图工具Matplotlib包可视化实现机器学习中的KNN算法。 需要提前安装python的Numpy和Matplotlib包。 KNN–最近邻分类算法,算法逻辑比较简单,思路如下: 1.设一待分类数据iData,先计算其到已标记数据集中每个数
-
本文向大家介绍Jmeter参数化实现原理及过程解析,包括了Jmeter参数化实现原理及过程解析的使用技巧和注意事项,需要的朋友参考一下 背景: 在实际的测试工作中,我们经常需要对多组不同的输入数据,进行同样的测试操作步骤,以验证我们的软件的功能。这种测试方式在业界称为数据驱动测试,而在实际测试工作中,测试工具中实现不同数据输入的过程称为参数化设置。 jmeter提供多种参数化设置的方式,常用的有:
-
本文向大家介绍基于python爬取梨视频实现过程解析,包括了基于python爬取梨视频实现过程解析的使用技巧和注意事项,需要的朋友参考一下 目标网址:梨视频 然后我们找到科技这一页:https://www.pearvideo.com/category_8。其实你要哪一页都行,你喜欢就行。嘿嘿… 这是动态网站,所以咱们直奔network 然后去到XHR: 找规律,这个应该不难,我就直接贴网址上来咯,