
PyTorch搭建一维线性回归模型(二)

PyTorch基础入门二:PyTorch搭建一维线性回归模型
1)一维线性回归模型的理论基础
给定数据集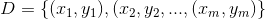 ,线性回归希望能够优化出一个好的函数
,线性回归希望能够优化出一个好的函数 ,使得
,使得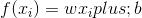 能够和
能够和 尽可能接近。
尽可能接近。
如何才能学习到参数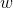 和
和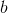 呢?很简单,只需要确定如何衡量与
呢?很简单,只需要确定如何衡量与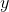 之间的差别,我们一般通过损失函数(Loss Funciton)来衡量:
之间的差别,我们一般通过损失函数(Loss Funciton)来衡量: 。取平方是因为距离有正有负,我们于是将它们变为全是正的。这就是著名的均方误差。我们要做的事情就是希望能够找到
。取平方是因为距离有正有负,我们于是将它们变为全是正的。这就是著名的均方误差。我们要做的事情就是希望能够找到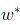 和
和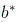 ,使得:
,使得:


均方差误差非常直观,也有着很好的几何意义,对应了常用的欧式距离。现在要求解这个连续函数的最小值,我们很自然想到的方法就是求它的偏导数,让它的偏导数等于0来估计它的参数,即:
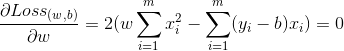

求解以上两式,我们就可以得到最优解。
2)代码实现
首先,我们需要“制造”出一些数据集:
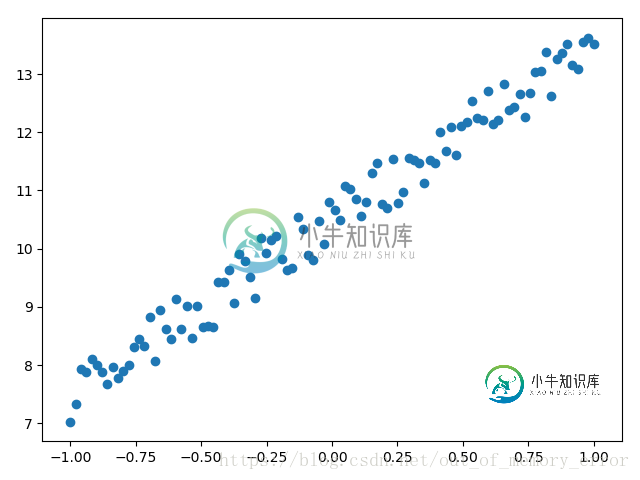
import torch import matplotlib.pyplot as plt x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) y = 3*x + 10 + torch.rand(x.size()) # 上面这行代码是制造出接近y=3x+10的数据集,后面加上torch.rand()函数制造噪音 # 画图 plt.scatter(x.data.numpy(), y.data.numpy()) plt.show()
我们想要拟合的一维回归模型是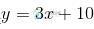 。上面制造的数据集也是比较接近这个模型的,但是为了达到学习效果,人为地加上了torch.rand()值增加一些干扰。
。上面制造的数据集也是比较接近这个模型的,但是为了达到学习效果,人为地加上了torch.rand()值增加一些干扰。
上面人为制造出来的数据集的分布如下:
有了数据,我们就要开始定义我们的模型,这里定义的是一个输入层和输出层都只有一维的模型,并且使用了“先判断后使用”的基本结构来合理使用GPU加速。
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1) # 输入和输出的维度都是1
def forward(self, x):
out = self.linear(x)
return out
if torch.cuda.is_available():
model = LinearRegression().cuda()
else:
model = LinearRegression()
然后我们定义出损失函数和优化函数,这里使用均方误差作为损失函数,使用梯度下降进行优化:
criterion = nn.MSELoss() optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)
接下来,开始进行模型的训练。
num_epochs = 1000
for epoch in range(num_epochs):
if torch.cuda.is_available():
inputs = Variable(x).cuda()
target = Variable(y).cuda()
else:
inputs = Variable(x)
target = Variable(y)
# 向前传播
out = model(inputs)
loss = criterion(out, target)
# 向后传播
optimizer.zero_grad() # 注意每次迭代都需要清零
loss.backward()
optimizer.step()
if (epoch+1) %20 == 0:
print('Epoch[{}/{}], loss:{:.6f}'.format(epoch+1, num_epochs, loss.data[0]))
首先定义了迭代的次数,这里为1000次,先向前传播计算出损失函数,然后向后传播计算梯度,这里需要注意的是,每次计算梯度前都要记得将梯度归零,不然梯度会累加到一起造成结果不收敛。为了便于看到结果,每隔一段时间输出当前的迭代轮数和损失函数。
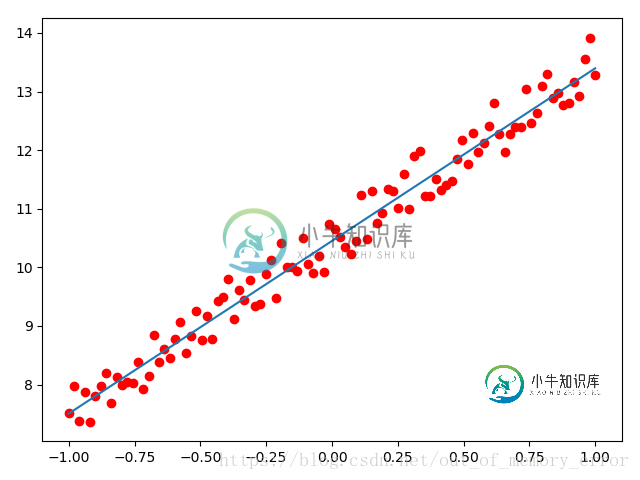
接下来,我们通过model.eval()函数将模型变为测试模式,然后将数据放入模型中进行预测。最后,通过画图工具matplotlib看一下我们拟合的结果,代码如下:
model.eval() if torch.cuda.is_available(): predict = model(Variable(x).cuda()) predict = predict.data.cpu().numpy() else: predict = model(Variable(x)) predict = predict.data.numpy() plt.plot(x.numpy(), y.numpy(), 'ro', label='Original Data') plt.plot(x.numpy(), predict, label='Fitting Line') plt.show()
其拟合结果如下图:
附上完整代码:
# !/usr/bin/python
# coding: utf8
# @Time : 2018-07-28 18:40
# @Author : Liam
# @Email : luyu.real@qq.com
# @Software: PyCharm
# .::::.
# .::::::::.
# :::::::::::
# ..:::::::::::'
# '::::::::::::'
# .::::::::::
# '::::::::::::::..
# ..::::::::::::.
# ``::::::::::::::::
# ::::``:::::::::' .:::.
# ::::' ':::::' .::::::::.
# .::::' :::: .:::::::'::::.
# .:::' ::::: .:::::::::' ':::::.
# .::' :::::.:::::::::' ':::::.
# .::' ::::::::::::::' ``::::.
# ...::: ::::::::::::' ``::.
# ```` ':. ':::::::::' ::::..
# '.:::::' ':'````..
# 美女保佑 永无BUG
import torch
from torch.autograd import Variable
import numpy as np
import random
import matplotlib.pyplot as plt
from torch import nn
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1)
y = 3*x + 10 + torch.rand(x.size())
# 上面这行代码是制造出接近y=3x+10的数据集,后面加上torch.rand()函数制造噪音
# 画图
# plt.scatter(x.data.numpy(), y.data.numpy())
# plt.show()
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1) # 输入和输出的维度都是1
def forward(self, x):
out = self.linear(x)
return out
if torch.cuda.is_available():
model = LinearRegression().cuda()
else:
model = LinearRegression()
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)
num_epochs = 1000
for epoch in range(num_epochs):
if torch.cuda.is_available():
inputs = Variable(x).cuda()
target = Variable(y).cuda()
else:
inputs = Variable(x)
target = Variable(y)
# 向前传播
out = model(inputs)
loss = criterion(out, target)
# 向后传播
optimizer.zero_grad() # 注意每次迭代都需要清零
loss.backward()
optimizer.step()
if (epoch+1) %20 == 0:
print('Epoch[{}/{}], loss:{:.6f}'.format(epoch+1, num_epochs, loss.data[0]))
model.eval()
if torch.cuda.is_available():
predict = model(Variable(x).cuda())
predict = predict.data.cpu().numpy()
else:
predict = model(Variable(x))
predict = predict.data.numpy()
plt.plot(x.numpy(), y.numpy(), 'ro', label='Original Data')
plt.plot(x.numpy(), predict, label='Fitting Line')
plt.show()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍PyTorch搭建多项式回归模型(三),包括了PyTorch搭建多项式回归模型(三)的使用技巧和注意事项,需要的朋友参考一下 PyTorch基础入门三:PyTorch搭建多项式回归模型 1)理论简介 对于一般的线性回归模型,由于该函数拟合出来的是一条直线,所以精度欠佳,我们可以考虑多项式回归来拟合更多的模型。所谓多项式回归,其本质也是线性回归。也就是说,我们采取的方法是,提高每个属
-
在本章中,我们将重点介绍使用TensorFlow进行线性回归实现的基本示例。逻辑回归或线性回归是用于对离散类别进行分类的监督机器学习方法。在本章中的目标是构建一个模型,用户可以通过该模型预测预测变量与一个或多个自变量之间的关系。 如果是因变量而变化,则认为是自变量。两个变量之间的这种关系可认为是线性的。两个变量的线性回归关系看起来就像下面提到的方程式一样 - 接下来,我们将设计一个线性回归算法,有
-
回归问题的条件或者说前提是 1) 收集的数据 2) 假设的模型,即一个函数,这个函数里含有未知的参数,通过学习,可以估计出参数。然后利用这个模型去预测/分类新的数据。 1 线性回归的概念 线性回归假设特征和结果都满足线性。即不大于一次方。收集的数据中,每一个分量,就可以看做一个特征数据。每个特征至少对应一个未知的参数。这样就形成了一个线性模型函数,向量表示形式: 这个就是一个组合问题,
-
线性回归模型(linear regression) 1.模型定义 给定数据集,$$T={(x{(1)},y{(1)}),(x{(2)},y{(2)}),...,(x{(m)},y{(m)})}$$,其中$$x{(i)}=(1, x_1, x_2, ..., x_n)T\in X= R{n+1}$$,$$y{(i)}\in Y=R$$,线性回归模型试图学到一个通过属性的线性组合来进行预测的函数,即
-
1 普通线性模型 普通线性模型(ordinary linear model)可以用下式表示: Y = \beta0 + \beta_1 x_1 + \beta_2 x_2 + … + \beta{p-1} x_{p-1} + \epsilon 这里$\beta$是未知参数,$\epsilon$是误差项。普通线性模型主要有以下几点假设: 响应变量$Y$和误差项$\epsilon$均服从正太分
-
我想写一个程序,给定三维空间中的点列表,用浮点表示为x,y,z坐标的数组,在这个空间中输出一条最佳拟合线。直线可以/应该是单位向量和直线上的点的形式。 问题是我不知道这是怎么做的。我发现的最接近的东西是这种联系,尽管老实说,我不明白他是如何从一个方程到另一个方程的,当我们到达矩阵时,我已经迷失了。 有没有一个简单的二维线性回归的泛化,我可以使用/有人可以(数学上)解释上面的链接到方法是否/如何工作