《中邮消费金融》专题
-
 最大花费金额 - 华为OD统一考试
最大花费金额 - 华为OD统一考试OD统一考试 题解: Java / Python / C++ 题目描述 双十一众多商品进行打折销售,小明想购买自己心仪的一些物品,但由于受购买资金限制,所以他决定从众多心仪商品中购买三件,而且想尽可能的花完资金现在请你设计一个程序帮助小明计算尽可能花费的最大资金数额。 输入描述 第一行为一维整型数组M,数组长度Q小于100,数组元素记录单个商品的价格,单个商品价格小于1000。 第二行为购买资金的
-
 Kafka消费者仅在两条消息堆叠时读取消息
Kafka消费者仅在两条消息堆叠时读取消息我们有一个Kafka制作人,偶尔会制作一些信息。 我写了一个消费者来消费这些消息。问题是,只有当两个消息叠加时,它们才会被使用。例如,如果消息是在13:00产生的,消费者不做任何事情。如果另一条消息是在13:01生成的,则消费者会使用这两条消息。在kafkaTool中,在消费者属性中有一个名为LAG的列,当消息未被消费时,该列为1。我缺少的这个东西有什么配置吗? 消费者配置:
-
为什么新消费者群体的Kafka消费者(0.10.0.0)会看到旧的/以前发布的消息?
我有一个制作人发布一个名为“MyTopic”的主题的消息。我有两个不同的消费者组中的两个消费者在听这些消息。我按以下顺序开始这两个消费者和生产者。 1)启动组“GROUP1”中的使用者%1%2)启动生产者以发布数百条消息 过了一段时间,我检查消费者1的偏移量,这与我预期的一样: 输出: 输出: 对于任何其他拥有新消费群体的消费者来说,也存在同样的问题。为什么在消息发布后加入一个新的消费者组的消费者
-
消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果不正确,那么有没有什么hack的手段?*
本文向大家介绍消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果不正确,那么有没有什么hack的手段?*相关面试题,主要包含被问及消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果不正确,那么有没有什么hack的手段?*时的应答技巧和注意事项,需要的朋友参考一下 不正确,通过自定义分区分配策略,可以将一个c
-
Kafa consumer 是否可以消费指定分区消息?
本文向大家介绍Kafa consumer 是否可以消费指定分区消息?相关面试题,主要包含被问及Kafa consumer 是否可以消费指定分区消息?时的应答技巧和注意事项,需要的朋友参考一下 Kafa consumer 消费消息时,向 broker 发出"fetch"请求去消费特定分区的消息,consumer 指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,custome
-
Apache Kafka-消费者未从生产者接收消息
我很感激你在这方面的帮助。 我正在构建一个ApacheKafka消费者,以订阅另一个已经运行的Kafka。现在,我的问题是,当我的制作人将消息推送到服务器时。。。我的消费者没有收到。。我在打印的日志中得到以下信息: 我不确定我是否遗漏了任何重要的配置。。。但是,我可以使用WireShark看到一些来自我的服务器的消息,但是我的消费者没有消费这些消息。。。。 我的代码是示例消费者示例的精确副本:ht
-
仅拦截来自消费者的Spring云流消息
我目前正在使用带有的Kafka绑定器的Spring Cloud Stream为我的Spring Boot微服务执行消息记录。 我有: 生产者将消息发布到订阅频道 在消息从生产者发布到流并被消费者收听的整个过程中,可以观察到preSend方法被触发了两次: 一次在生产者端-消息发布到流时 然而,出于日志记录的目的,我只需要在消费者端截获并记录消息。 是否有任何方法可以仅在一侧(例如消费者侧)截获SC
-
如何消费来自Kafka主题的特定消息
有人能帮我弄清楚这件事吗。 谢了!
-
消费者再平衡期间的Kafka消息排序
在消费者重新平衡期间如何确保消息排序。假设最初我们有四个分区:p1、p2、p3、p4和两个消费者c1和c2(在同一组中)。因此每个消费者得到两个分区,例如c1 : p1,p2和c2 : p3,p4。 现在添加了新的消费者,比如c3和c4,重新平衡发生,这样每个消费者都有一个分区,比如c1: p1、c2: p2、c3: p3、c4: p4。 在此期间,消费者c1可能正在处理来自分区p2的消息(在重新
-
Kafka 0.10Java消费者没有从主题阅读消息
我有一个简单的java制作人,如下所示 我正在尝试读取如下数据 但消费者并没有从Kafka那里读到任何信息。如果我在处添加以下内容 然后消费者开始从题目开始阅读。但是每次消费者重新启动时,它都从我不想要的主题开始读取消息。如果我在启动消费程序时添加了以下配置 然后,它从主题中读取消息,但是如果消费者在处理所有消息之前重新启动,那么它不会读取未处理的消息。 有人可以让我知道出了什么问题,我该如何解决
-
pact-js消息消费者契约示例不工作
我想从Pact开始,为我们的异步消息流体系结构启用消费者驱动的契约。在阅读了pact-foundation的大部分文档和入门指南之后,我尝试使用https://github.com/pact-foundation/pact-js/tree/master/examples/messages中的示例。现在我只需要契约创建的消费者端。 当我跑的时候 至 由于我的JavaScript/node.js/Ty
-
Kafka消费者在重新启动时跳过消息
我有一个Kafka集群正在运行,当重新启动应用程序(消费者)时,它会跳过一些在应用程序关闭时推送到主题的消息。 当应用程序启动时,我可以看到它读取带有偏移量的消息,然后将偏移量推送到。然后当应用程序关闭时,带有偏移量的消息被推送到主题。重启应用程序后,它读取并将其偏移量设置为,因此跳过。 这是我的配置:
-
消费和产生特定的Kafka分区的消息?
阅读主题中的所有分区: ~bin/kafka-console-consumer.sh--zookeeper localhost:2181--topic myTopic--从头开始 如何使用主题的特定分区?(例如使用分区键13) 以及如何使用特定分区键在分区中生成消息?有可能吗?
-
Kafka消费者能否并行处理多个消息
想知道Kafka使用者(Java客户端)是否可以并行读取和处理多条消息...我的意思是使用多个线程...我应该使用rxJava吗?? 1)这样做是一个好的方法吗???2)而且根据我的理解,Kafka甚至把每一个线程都当作消费者...如果我错了,请纠正我... 3)并且还想让Java客户端作为守护进程服务在Linux中运行,这样它就可以连续运行,并且轮询Kafka的消息,读取和处理都是一样的...这
-
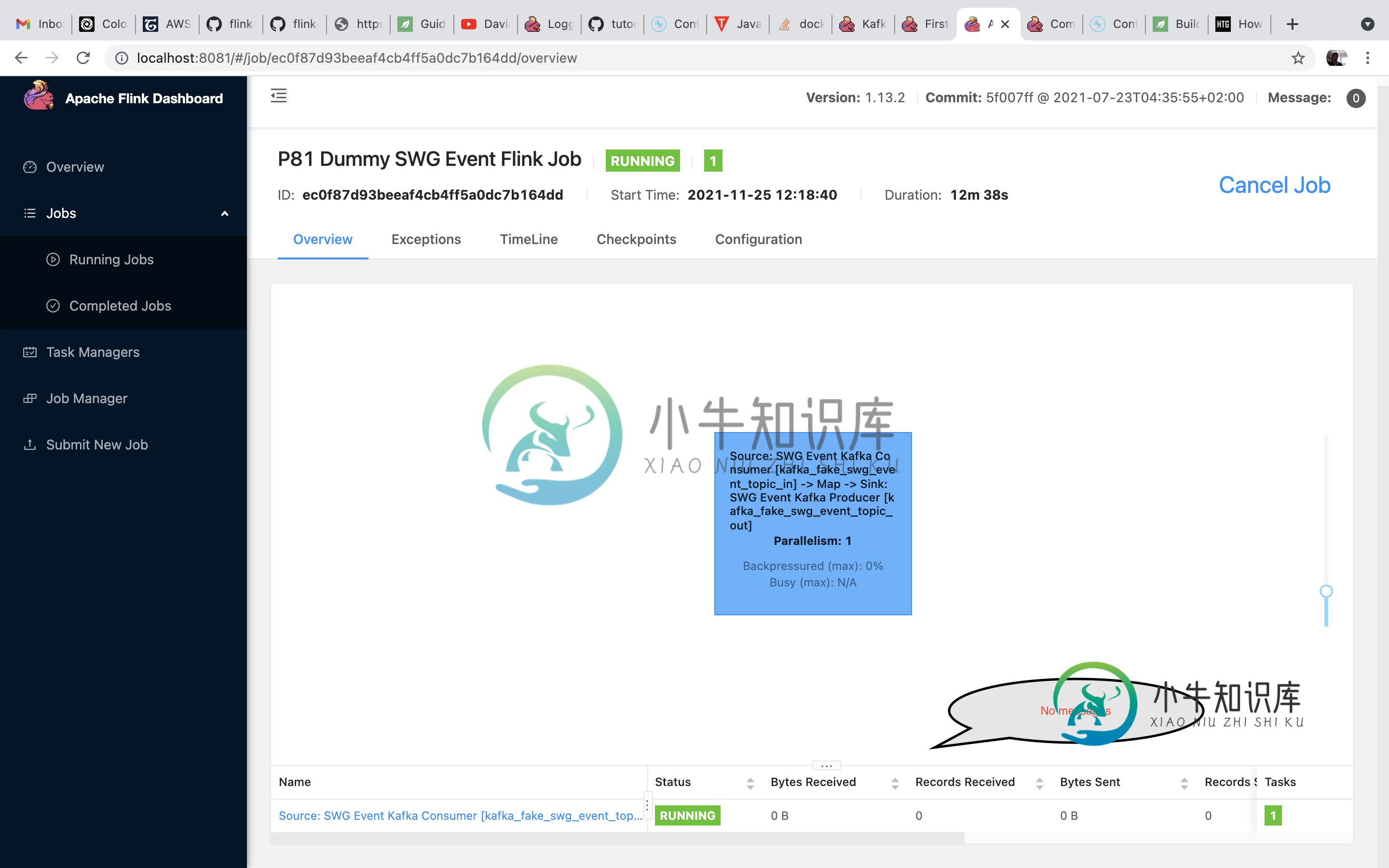 Flink.Kafka消费者没有收到来自Kafka的消息
Flink.Kafka消费者没有收到来自Kafka的消息我在mac上运行Kafka和Flink作为docker容器。 我已经实现了Flink作业,它应该消耗来自Kafka主题的消息。我运行一个向主题发送消息的python生产者。 工作开始时没有问题,但没有收到任何消息。我相信这些消息被发送到了正确的主题,因为我有一个能够使用消息的python消费者。 flink作业(java): Flink作业日志: 生产者作业(python):(在主机上运行-不是d