
Flink.Kafka消费者没有收到来自Kafka的消息

我在mac上运行Kafka和Flink作为docker容器。
我已经实现了Flink作业,它应该消耗来自Kafka主题的消息。我运行一个向主题发送消息的python生产者。
工作开始时没有问题,但没有收到任何消息。我相信这些消息被发送到了正确的主题,因为我有一个能够使用消息的python消费者。
flink作业(java):
package com.p81.datapipeline.swg;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Properties;
public class SWGEventJob {
private static final Logger LOG = LoggerFactory.getLogger(SWGEventJob.class);
public static void main(String[] args) throws Exception {
ParameterTool parameterTool = ParameterTool.fromArgs(args);
final String inputTopic = parameterTool.get("kafka_input_topic","kafka_fake_swg_event_topic_in");
final String outputTopic = parameterTool.get("kafka_output_topic","kafka_fake_swg_event_topic_out");
final String consumerGroup = parameterTool.get("kafka_consumer_group","p81_swg_event_consumer_group");
final String bootstrapServers = parameterTool.get("kafka_bootstrap_servers","broker:29092");
LOG.info("inputTopic : " + inputTopic);
LOG.info("outputTopic : " + outputTopic);
LOG.info("consumerGroup : " + consumerGroup);
LOG.info("bootstrapServers : " + bootstrapServers);
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
FlinkKafkaConsumer<SWGEvent> swgEventConsumer = createSWGEventConsumer(inputTopic, bootstrapServers, consumerGroup);
swgEventConsumer.setStartFromEarliest();
DataStream<SWGEvent> dataStream = env.addSource(swgEventConsumer).name(String.format("SWG Event Kafka Consumer [%s]",inputTopic));
FlinkKafkaProducer<SWGEvent> swgEventProducer = createSWGEventProducer(outputTopic, bootstrapServers);
dataStream.map(new SWGEventAnonymizer()).addSink(swgEventProducer).name(String.format("SWG Event Kafka Producer [%s]",outputTopic));
env.execute("P81 Dummy SWG Event Flink Job");
}
static private FlinkKafkaConsumer<SWGEvent> createSWGEventConsumer(String topic, String kafkaAddress, String kafkaGroup) {
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", kafkaAddress);
properties.setProperty("group.id", kafkaGroup);
return new FlinkKafkaConsumer<>(topic, new SWGEventDeserializationSchema(), properties);
}
static private FlinkKafkaProducer<SWGEvent> createSWGEventProducer(String topic, String kafkaAddress) {
return new FlinkKafkaProducer<>(kafkaAddress, topic, new SWGEventSerializationSchema());
}
}
Flink作业日志:
2021-11-25 10:03:25,282 INFO org.apache.flink.client.ClientUtils [] - Starting program (detached: true)
2021-11-25 10:03:25,284 INFO com.p81.datapipeline.swg.SWGEventJob [] - inputTopic : kafka_fake_swg_event_topic_in
2021-11-25 10:03:25,284 INFO com.p81.datapipeline.swg.SWGEventJob [] - outputTopic : kafka_fake_swg_event_topic_out
2021-11-25 10:03:25,284 INFO com.p81.datapipeline.swg.SWGEventJob [] - consumerGroup : p81_swg_event_consumer_group
2021-11-25 10:03:25,284 INFO com.p81.datapipeline.swg.SWGEventJob [] - bootstrapServers : broker:29092
2021-11-25 10:03:26,155 WARN org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer [] - Property [transaction.timeout.ms] not specified. Setting it to 3600000 ms
2021-11-25 10:03:26,202 INFO org.apache.flink.client.deployment.application.executors.EmbeddedExecutor [] - Job 62c766b4ace055cf91f97f1e46f621d1 is submitted.
2021-11-25 10:03:26,202 INFO org.apache.flink.client.deployment.application.executors.EmbeddedExecutor [] - Submitting Job with JobId=62c766b4ace055cf91f97f1e46f621d1.
2021-11-25 10:03:26,301 INFO org.apache.flink.runtime.dispatcher.StandaloneDispatcher [] - Received JobGraph submission 62c766b4ace055cf91f97f1e46f621d1 (P81 Dummy SWG Event Flink Job).
2021-11-25 10:03:26,302 INFO org.apache.flink.runtime.dispatcher.StandaloneDispatcher [] - Submitting job 62c766b4ace055cf91f97f1e46f621d1 (P81 Dummy SWG Event Flink Job).
2021-11-25 10:03:26,306 INFO org.apache.flink.runtime.rpc.akka.AkkaRpcService [] - Starting RPC endpoint for org.apache.flink.runtime.jobmaster.JobMaster at akka://flink/user/rpc/jobmanager_15 .
2021-11-25 10:03:26,307 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - Initializing job P81 Dummy SWG Event Flink Job (62c766b4ace055cf91f97f1e46f621d1).
2021-11-25 10:03:26,309 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - Using restart back off time strategy NoRestartBackoffTimeStrategy for P81 Dummy SWG Event Flink Job (62c766b4ace055cf91f97f1e46f621d1).
2021-11-25 10:03:26,309 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - Running initialization on master for job P81 Dummy SWG Event Flink Job (62c766b4ace055cf91f97f1e46f621d1).
2021-11-25 10:03:26,309 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - Successfully ran initialization on master in 0 ms.
2021-11-25 10:03:26,310 INFO org.apache.flink.runtime.scheduler.adapter.DefaultExecutionTopology [] - Built 1 pipelined regions in 0 ms
2021-11-25 10:03:26,310 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - No state backend has been configured, using default (HashMap) org.apache.flink.runtime.state.hashmap.HashMapStateBackend@252e8634
2021-11-25 10:03:26,310 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - Checkpoint storage is set to 'jobmanager'
2021-11-25 10:03:26,310 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator [] - No checkpoint found during restore.
2021-11-25 10:03:26,310 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - Using failover strategy org.apache.flink.runtime.executiongraph.failover.flip1.RestartPipelinedRegionFailoverStrategy@3931aba0 for P81 Dummy SWG Event Flink Job (62c766b4ace055cf91f97f1e46f621d1).
2021-11-25 10:03:26,311 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - Starting execution of job P81 Dummy SWG Event Flink Job (62c766b4ace055cf91f97f1e46f621d1) under job master id 00000000000000000000000000000000.
2021-11-25 10:03:26,318 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - Starting scheduling with scheduling strategy [org.apache.flink.runtime.scheduler.strategy.PipelinedRegionSchedulingStrategy]
2021-11-25 10:03:26,318 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Job P81 Dummy SWG Event Flink Job (62c766b4ace055cf91f97f1e46f621d1) switched from state CREATED to RUNNING.
2021-11-25 10:03:26,319 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Source: SWG Event Kafka Consumer [kafka_fake_swg_event_topic_in] -> Map -> Sink: SWG Event Kafka Producer [kafka_fake_swg_event_topic_out] (1/1) (87c54365842acb250dc6984b1ca9b466) switched from CREATED to SCHEDULED.
2021-11-25 10:03:26,320 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - Connecting to ResourceManager akka.tcp://flink@jobmanager:6123/user/rpc/resourcemanager_*(00000000000000000000000000000000)
2021-11-25 10:03:26,321 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - Resolved ResourceManager address, beginning registration
2021-11-25 10:03:26,322 INFO org.apache.flink.runtime.resourcemanager.StandaloneResourceManager [] - Registering job manager 00000000000000000000000000000000@akka.tcp://flink@jobmanager:6123/user/rpc/jobmanager_15 for job 62c766b4ace055cf91f97f1e46f621d1.
2021-11-25 10:03:26,324 INFO org.apache.flink.runtime.resourcemanager.StandaloneResourceManager [] - Registered job manager 00000000000000000000000000000000@akka.tcp://flink@jobmanager:6123/user/rpc/jobmanager_15 for job 62c766b4ace055cf91f97f1e46f621d1.
2021-11-25 10:03:26,327 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - JobManager successfully registered at ResourceManager, leader id: 00000000000000000000000000000000.
2021-11-25 10:03:26,328 INFO org.apache.flink.runtime.resourcemanager.slotmanager.DeclarativeSlotManager [] - Received resource requirements from job 62c766b4ace055cf91f97f1e46f621d1: [ResourceRequirement{resourceProfile=ResourceProfile{UNKNOWN}, numberOfRequiredSlots=1}]
2021-11-25 10:03:26,394 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Source: SWG Event Kafka Consumer [kafka_fake_swg_event_topic_in] -> Map -> Sink: SWG Event Kafka Producer [kafka_fake_swg_event_topic_out] (1/1) (87c54365842acb250dc6984b1ca9b466) switched from SCHEDULED to DEPLOYING.
2021-11-25 10:03:26,395 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Deploying Source: SWG Event Kafka Consumer [kafka_fake_swg_event_topic_in] -> Map -> Sink: SWG Event Kafka Producer [kafka_fake_swg_event_topic_out] (1/1) (attempt #0) with attempt id 87c54365842acb250dc6984b1ca9b466 to 172.18.0.4:35157-adeb80 @ kafka_taskmanager_1.kafka_default (dataPort=41077) with allocation id 968834ad9a512d16050107a088449490
2021-11-25 10:03:26,546 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Source: SWG Event Kafka Consumer [kafka_fake_swg_event_topic_in] -> Map -> Sink: SWG Event Kafka Producer [kafka_fake_swg_event_topic_out] (1/1) (87c54365842acb250dc6984b1ca9b466) switched from DEPLOYING to INITIALIZING.
2021-11-25 10:03:27,597 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Source: SWG Event Kafka Consumer [kafka_fake_swg_event_topic_in] -> Map -> Sink: SWG Event Kafka Producer [kafka_fake_swg_event_topic_out] (1/1) (87c54365842acb250dc6984b1ca9b466) switched from INITIALIZING to RUNNING.
生产者作业(python):(在主机上运行-不是docker)
import json
import os
import time
from dataclasses import dataclass, asdict
from random import randint
from kafka import KafkaProducer
import logging
logging.basicConfig(level=logging.INFO)
_METHODS = ['GET'] * 17 + ['POST', 'PUT', 'DELETE']
_ACTIONS = ['ALLOW', 'WARNING', 'BLOCK']
_URLS = ['x']
@dataclass
class SWGEvent:
url: str
action: str
agentId: int
agentIP: str
HTTPMethod: str
timestamp: int
def _get_fake_swg_event() -> SWGEvent:
url = _URLS[randint(0, len(_URLS) - 1)]
action = _ACTIONS[randint(0, len(_ACTIONS) - 1)]
agent_id = randint(1, 1000)
agent_ip = f'{randint(1, 255)}.{randint(1, 255)}.{randint(1, 255)}.{randint(1, 255)}'
http_method = _METHODS[randint(0, len(_METHODS) - 1)]
timestamp = int(time.time())
return SWGEvent(url, action, agent_id, agent_ip, http_method, timestamp)
def produce(producer: KafkaProducer, topic_name: str) -> None:
x = 0
while x < 500:
event: SWGEvent = _get_fake_swg_event()
result = producer.send(topic_name, asdict(event))
x += 1
time.sleep(1)
producer.flush()
logging.info(f'send result: {str(result)}')
if __name__ == '__main__':
kafka_server = os.getenv('KAFKA_SERVER')
topic_name = os.getenv('TOPIC_NAME')
logging.info(f'Producer.Working with server {kafka_server} and topic {topic_name}')
producer = KafkaProducer(bootstrap_servers=kafka_server, value_serializer=lambda v: json.dumps(v).encode('utf-8'))
produce(producer, topic_name)
python代码打印出来:
INFO:root:Producer.Working with server localhost:9092 and topic kafka_fake_swg_event_topic_in
docker撰写。yml
version: '3.8'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.0.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:7.0.0
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "9092:9092"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8091
schema-registry:
image: confluentinc/cp-schema-registry:7.0.0
hostname: schema-registry
container_name: schema-registry
depends_on:
- broker
ports:
- "8091:8091"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'broker:29092'
SCHEMA_REGISTRY_LISTENERS: http://0.0.0.0:8091
rest-proxy:
image: confluentinc/cp-kafka-rest:7.0.0
depends_on:
- broker
- schema-registry
ports:
- 8082:8082
hostname: rest-proxy
container_name: rest-proxy
environment:
KAFKA_REST_HOST_NAME: rest-proxy
KAFKA_REST_BOOTSTRAP_SERVERS: 'broker:29092'
KAFKA_REST_LISTENERS: "http://0.0.0.0:8082"
KAFKA_REST_SCHEMA_REGISTRY_URL: 'http://schema-registry:8091'
KAFKA_REST_ACCESS_CONTROL_ALLOW_ORIGIN: '*'
KAFKA_REST_ACCESS_CONTROL_ALLOW_METHODS: 'GET,POST,PUT,DELETE,OPTIONS,HEAD'
jobmanager:
image: flink:1.13.2-scala_2.12
ports:
- "8081:8081"
command: jobmanager
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: jobmanager
taskmanager:
image: flink:1.13.2-scala_2.12
depends_on:
- jobmanager
command: taskmanager
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: jobmanager
taskmanager.numberOfTaskSlots: 2
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2f465a0a4129 confluentinc/cp-kafka-rest:7.0.0 "/etc/confluent/dock…" 23 hours ago Up 23 hours 0.0.0.0:8082->8082/tcp rest-proxy
eb25992c47d0 confluentinc/cp-schema-registry:7.0.0 "/etc/confluent/dock…" 23 hours ago Up 23 hours 8081/tcp, 0.0.0.0:8091->8091/tcp schema-registry
1081319da296 confluentinc/cp-kafka:7.0.0 "/etc/confluent/dock…" 23 hours ago Up 17 hours 0.0.0.0:9092->9092/tcp, 0.0.0.0:9101->9101/tcp broker
de9056ee250c flink:1.13.2-scala_2.12 "/docker-entrypoint.…" 23 hours ago Up 28 minutes 6123/tcp, 8081/tcp kafka_taskmanager_1
b38beefc35e3 confluentinc/cp-zookeeper:7.0.0 "/etc/confluent/dock…" 23 hours ago Up 23 hours 2888/tcp, 0.0.0.0:2181->2181/tcp, 3888/tcp zookeeper
e6db23fa8842 flink:1.13.2-scala_2.12 "/docker-entrypoint.…" 23 hours ago Up 18 hours 6123/tcp, 0.0.0.0:8081->8081/tcp kafka_jobmanager_1
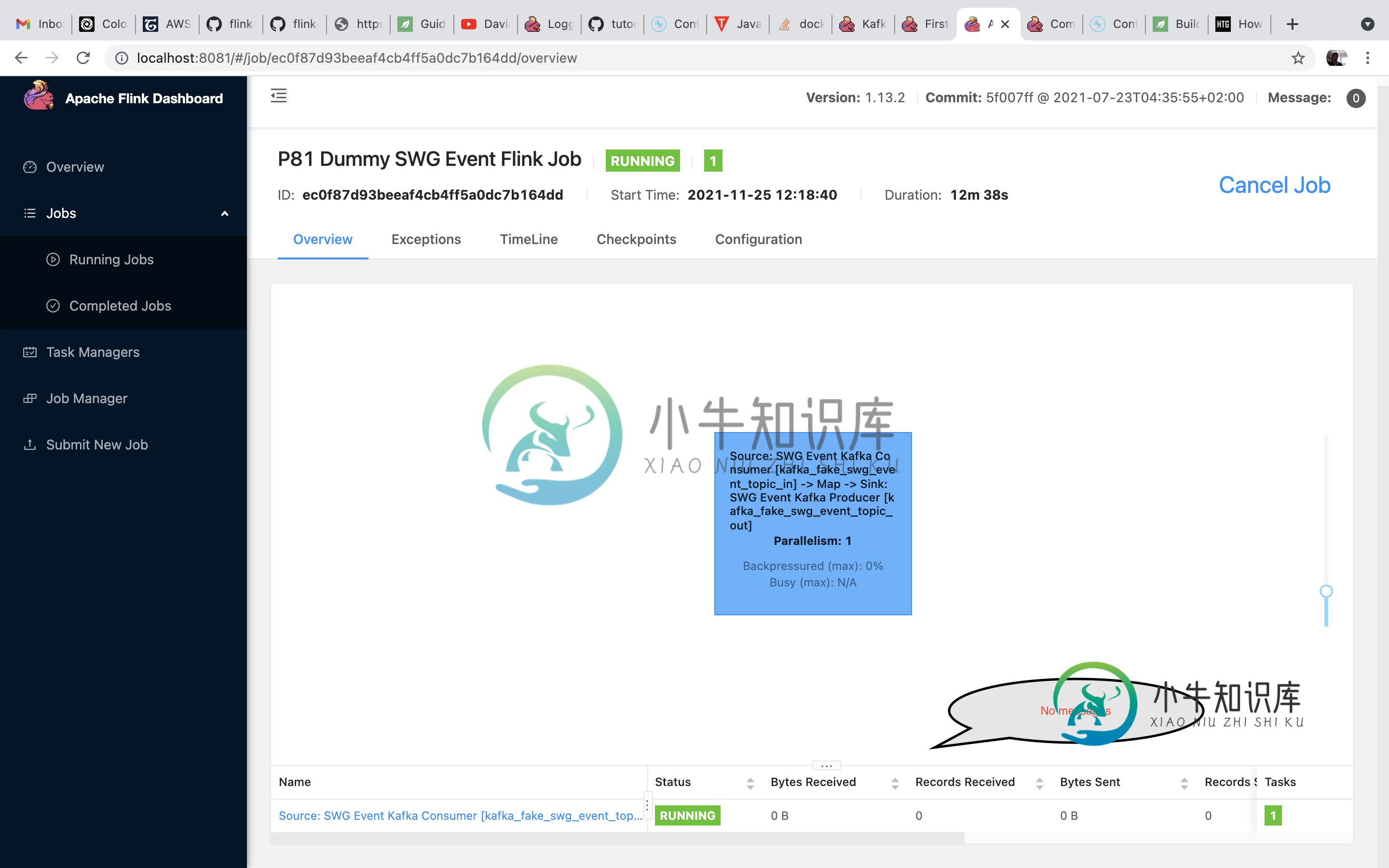
问题:为了让信息进入Flink job,应该修复什么?
更新#1看起来工作正常。Kafka消费者消费和Kafka制作人制作的事件。(通过查看Flink任务管理器日志,我了解到了这一点。)所以真正的问题是——为什么Flink UI显示零活动?
共有1个答案

您正在查看的Flink指标仅测量Flink群集本身内发生的流量(使用Flink的序列化器和网络堆栈),而忽略作业图边缘的通信(使用连接器的序列化器和网络)。
换句话说,源从不报告记录进来,汇也从不报告记录出去。
此外,在你的工作中,所有的操作员都可以链接在一起,所以Flink的网络根本不用。
是的,这令人困惑。
-
我正在使用以下在docker上运行kafka、zookeeper和kafdrop: 我有一个具有以下配置的Spring Boot Producer应用程序-: 在我的中,我有以下内容: 这是一个单独的应用程序,我在我的服务中这样称呼Kafka制作人: 在一个完全不同的spring引导应用程序中,我有一个像这样的使用者: 我可以看到消费者正在连接到代理,但是有消息的日志。下面是我能看到的完整日志:
-
D: \软件\Kafka\Kafka2.10-0.10.0.1\bin\windows 我使用上面的命令来消费消息,有什么我错过的吗?帮助我: 这个 那些是生产者和消费者......
-
我正在尝试把阿帕奇Storm和Kafka整合在一起。连接似乎建立良好,但没有收到任何消息。但是这些消息似乎也被发送到了Kafka服务器,而Kafka服务器中相应主题的索引文件显示存在一些数据。有没有一种方法可以在Storm End上调试这个更多的..?我正在使用Storm的客户解码器来处理信息。Storm的实现是:
-
消费者使用Spring的JavaConfig类如下: Kafka主题侦听器使用@KafkaListener注释,如下所示: 我的pom包括依赖项: 现在当我打包到war并部署到tomcat时,它不会显示任何错误,即使在调试模式下也不会显示任何错误,只是部署war什么都没有。 请帮助我了解是否缺少触发kafkalistner的某些配置。 谢谢Gary我添加了上下文。xml和web。xml,但我得到了
-
我试图消费一个Kafka主题从Spring启动应用程序。我使用的是下面提到的版本的Spring云流 Spring boot starter父级:2.5.7 Spring云版本:2020.0.4 下面是代码和配置 application.yml 消息消费者类 下面的消息发布者正在正确地发布消息。发布者是在不同的微服务中编写的。 pom.xml
-
我是Kafka的新手。我在网上读了很多关于Kafka制作人和Kafka消费者的说明。我成功地实现了前者,它可以向Kafka集群发送消息。然而,我没有完成后一个。请帮我解决这个问题。我看到我的问题像StackOverflow上的一些帖子,但我想更清楚地描述一下。我在虚拟盒子的Ubuntu服务器上运行Kafka和Zookeeper。使用1个Kafka集群和1个Zookeeper集群的最简单配置(几乎是