《中邮消费金融》专题
-
5.2会员消费积分/赠券
此协议用于微信会员消费上传进行积分或赠券。具体是执行积分、赠券,由营销活动中进行设置。 请求参数说明 参数 描述 必填 示例值 类型 最大长度 action 接口参数组 是 object └action 需要调用的接口名称 是 mb_points string get GET参数组,本组参数需要参与签名 是 object └mbno 会员卡号(id和mbno两个可选其中之一) 否 47302320
-
如何在Camel测试中模拟AMQP消费者?
说我有以下路线: 让我们假设根据RabbitMQ使用的消息调整和。 我想对3个场景进行单元测试: null 我的问题是:如何模拟/存根RabbitMQendpoint,以便路由在生产中正常执行,但不必实际将测试连接到RabbitMQ服务器?我需要某种“模拟信息”制作人。 一个代码示例或代码片段将非常有帮助,非常感谢!
-
在Camel-Kafka中创建并发的Kafka消费者
我使用的是camel-kafka版本。以下是KafkaURI: 请注意,我在URI选项中使用了。但是,当我一次将多条消息发布到主题时(全部发布到同一个分区),kafka使用者将依次接收这些消息。怎样才能同时接收到这些信息? 我正在寻找如下的解决方案: 是我用来从ibm MQ中同时读取的内容
-
单一消费计划中的多功能应用?
通过门户创建 Azure 函数应用时,无法选择是使用现有消耗计划还是创建新消耗计划。 但是,可以通过 ARM 模板执行此操作。 Azure 函数应用:在同一消耗计划下组织 Azure 函数应用对此进行了讨论,但它确实没有任何影响。 消费计划和功能应用程序之间的一对一映射与单个计划中的多个应用程序之间有什么实际区别?
-
我如何在Kafka中使用多个消费者?
我是一个学习Kafka的新学生,我遇到了一些关于理解多个消费者的基本问题,到目前为止,文章、文档等都没有太大的帮助。 我尝试做的一件事是编写我自己的高级Kafka生产者和消费者,并同时运行他们,发布100个简单的消息到一个主题,并让我的消费者检索他们。我成功地做到了这一点,但是当我试图引入第二个消费者来消费刚刚发布消息的同一主题时,它没有收到任何消息。 我的理解是,对于每个主题,您可以有来自不同消
-
在ActiveMQ Artemis中为每个消费者创建DLQ
我正在使用JMS消费来自ActiveMQ Artemis主题的消息。我的消费者直接连接到他们消费者队列的FQQN。像这样: 而中的配置是: 但是,DLQ的名字将会是<代号> DLQ。Transactions.Client1,没有消费者名称。 我需要的是每个消费者都有自己的DLQ。像这样的东西。这可能吗? 编辑: 我说的“消费者”,可能(实际上)更像是一个“消费群体”。例如,< code>Consu
-
减少Kafka消费者配置中Max.Poll.Records的影响
在某些情况下,API处理花费了更多的时间,因为获取了更多的记录,我们得到了以下错误? 成员consumer-prov-em-1-399ede46-9e12-4388-b5b8-f198a4e6a5bc向协调器apslt2555.uhc.com:9095(ID:2147483577 rack:null)发送离开组请求已过期。这意味着对poll()的后续调用之间的时间长于配置的max.poll.int
-
Kafka--对《消费者》中对象的反序列化
我们正在考虑在我们的for消息传递中使用Kafka,我们的应用程序是使用Spring开发的。所以,我们已经计划用Spring-Kafka。 生产者将消息作为HashMap对象放入队列。我们有JSON序列化器,并且假设映射将被序列化并放入队列。这是生产者配置。 我们看到的文章很少,建议是这样做: 我们不想为创建反序列化程序编写一些代码。有没有我们缺少的样板?任何帮助都将不胜感激!!
-
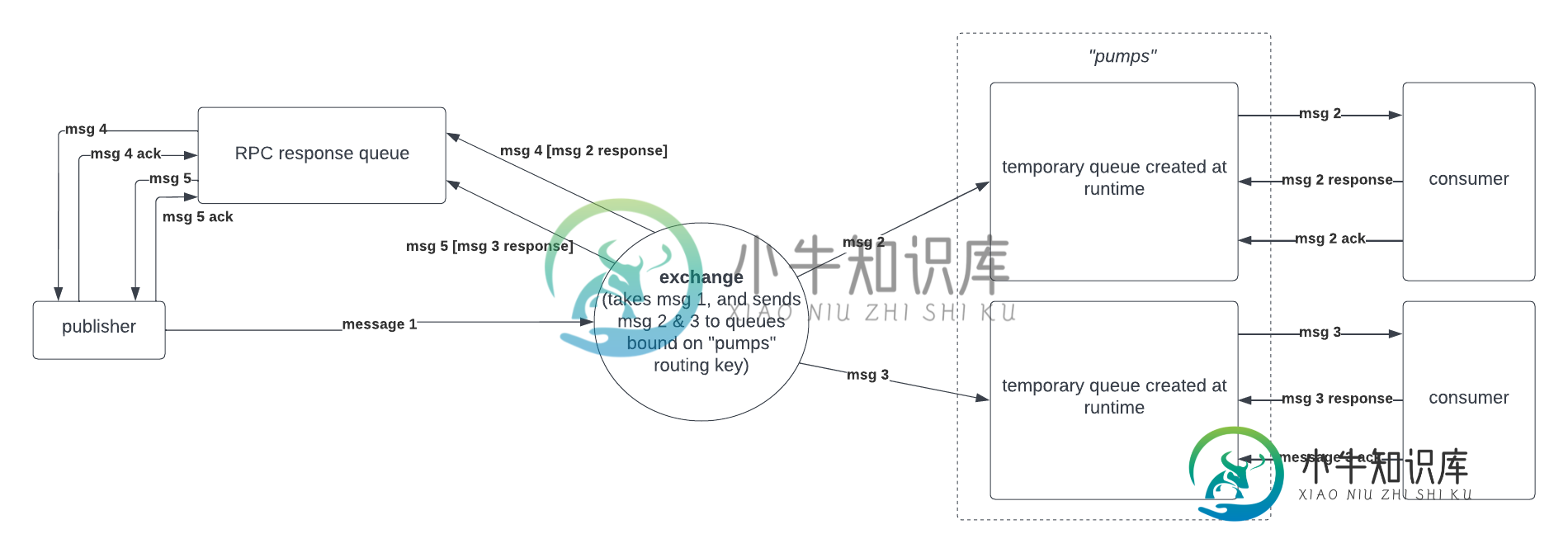 如何在直接交换中与多个消费者确认消息
如何在直接交换中与多个消费者确认消息发布者创建reply_to队列并发布到路由密钥,其中包含一条消息,告诉消费者向队列发送响应(RPC协议),以及一个传回的相关id,以便所有未来的结果都与该唯一标识符相关联 Exchange向绑定到该路由密钥的所有队列发送消息。这里,有两个消费者的两个队列,每个都绑定到路由密钥“泵” 一段时间后,消费者回复回队列,然后确认消息,以便他们的唯一队列删除发送到其队列的消息。每个收到消息的消费者都会这样做
-
为什么kafka 0.8.2说每个分区仅由一个消费者组中的一个消费者使用
在Apache Kafka 0.8.2 office文档的第5.6节“分销、消费者和消费者群体”小节中,它说 组中的使用者尽可能公平地划分分区,每个分区仅由一个消费组中的一个使用者使用。 但是我发现,在实践中,一个消费者组中的多个消费者可以通过从同一主题分区发送 FetchRequest 来使用单个分区中的数据。 在接下来的消费者身份证登记处小节中 除了由一个组中的所有使用者共享的group_id
-
如何检查Kafka中消费者的滞后,该消费者被分配了主题的特定分区?
我想检查手动分配给特定主题的消费者组的滞后,这可能吗。我使用的是Kafka-0.10.0.1。我用的是shKafka跑步课。shKafka。管理ConsumerGroupCommand-new consumer-description-bootstrap server localhost:9092-group test但它说不存在组,所以我想知道当我们手动分配分区时,是否可以检查使用者的延迟。
-
在Kafka 0.9中,有没有一种方法可以列出一个消费组中所有消费者的偏移量?
我正在使用Kafka 0.9新的消费者API。 我让Kafka为消费者负责补偿。我让消费者在多台机器上阅读相同的主题。 我试图找出以下内容: 在消费者组中注册的消费者 每个消费者的偏移量 我以为消费者-群体-消费者关系会存储在ZooKeeper中。我在ZooKeeper中看到了消费者节点,它没有孩子。 通过查看代码,我可以知道的偏移量被写入了kafka,但我不知道它们被写入了哪个主题?
-
为什么一个消费者为Spring Cloud Stream Kafka创建多个消费者配置?
我刚刚开始玩弄《Spring-Cloud-Stream》中的Kafka活页夹。 我配置了一个简单的消费者: 但当我启动应用程序时,我看到在启动日志中创建了三个独立的消费者配置: 我发现这些配置之间唯一不同的是客户机。id。 除此之外,我不知道为什么只有一个消费者有三种配置。 是因为我也在运行吗? 这是我的:
-
如何根据php中的小计和运费计算总金额?
我在做购物车。我能根据数量计算产品价格。 现在我计算的总额取决于小计和运费与产品价格。 当我增加产品数量时,它会计算产品价格,但不会计算小计和总金额。 或者有没有其他安全的方法来处理这个问题? 你能帮我解决这个问题吗?
-
Laravel/OmniPay贝宝,通过自定义运费金额
我试图通过一个自定义运费贝宝快递结账。 我用的是omnipay和laravel 4。 我收集这是可能的贝宝快递文档中引用,但不能让它与omniPay工作我尝试了以下: 在XXX是航运,运Amt,shipping_amount,我已经尝试添加航运价值到购物车中的每个项目。我尝试过修改类来手动添加运输值,就像这样: