《兴业数金》专题
-
如何与詹金斯并行执行同一作业多次?
问题内容: 我正在测试詹金斯,看它是否适合我们的构建和测试框架。我发现Jenkins及其可用的插件可以满足我们的大多数需求。除了我似乎无法找到有关如何执行一种特定类型任务的帮助。 我们正在为嵌入式设备创建应用程序。我们需要在这些设备上运行100项测试。如果我们在构建后在一台设备上运行所有测试,那么将需要几个小时才能获得结果。但是,如果我们在100个设备上并行运行测试,则可以在更短的时间内获得结果。
-
如何仅执行詹金斯中最新的排队作业?
问题内容: 我在詹金斯(Jenkins)有一个提交构建项目,该项目计划在完成时安排一个接受构建项目。由于提交的速度快于接受构建作业的完成时间,因此不久之后,现在有 六个 排队的接受构建作业。我希望验收构建项目像“投票SCM”功能一样工作- 完成后,开始最近排队的作业 ,跳过其余的 作业 。 没有更多的技巧,我无法使用“在构建其他项目之后构建”,因为我需要将信息从提交构建作业传递到验收构建作业。 问
-
使用flink/kubernetes替换etl作业(在SSI上):每个作业类型一个flink集群,或者每个作业执行创建和销毁flink集群
我正在尝试将使用SSIS包创建的数百个feed文件ETL作业替换为apache flink作业(并将kuberentes作为底层infra)的可行性。我在一些文章中看到的一条建议是“为一种工作使用一个flink集群”。 由于我每天都有少量的每种工作类型的工作,那么这意味着对我来说最好的方法是在执行工作时动态创建flinkcluster并销毁它以释放资源,这是正确的方法吗?我正在建立flinkclu
-
Spring批处理JobOperator.restart启动一个新的作业实例,不从最后一个块继续作业,而是从最后一个步骤继续作业
启动一个新的作业实例,不从最后一个块继续作业,而是从最后一个步骤继续作业。我需要从最后写的那块开始继续工作。 我的阅读器是一个自定义的RestReader,它首先计算要处理的项的总数,然后从API读取这个精确的数字。我正在使用@stepscope注释,因为我需要自定义阅读器中的自定义变量 使用@stepscope时Spring批处理重新启动功能不工作。 是否可以从上一个块开始继续工作,还是问题出在
-
生成添加到目标的所有数学表达式组合(Java作业/面试)
问题内容: 我已经尝试解决以下编码难题的问题,但无法在1小时内完成。我对算法的工作原理有一个想法,但是我不确定如何最好地实现它。我下面有我的代码和问题。 pi的前12位数字是314159265358。我们可以将这些数字转换为一个表达式,其计算结果为27182(e的前5位数字),如下所示: 要么 请注意,输入数字的顺序不变。只需插入运算符(+,-,/或*)即可创建表达式。 编写一个函数以获取数字和目
-
业务中心元数据文件使用Visual Studio OData Connection Service生成incorret APi路由
我有一个Dynamics Business Central的演示租户,我正在与OData合作,为公司实体制作CRUD示例,然后它为发票、报价、订单、产品和其他工作。我已经使用以下URL调用下载了元数据文件:https://api.businesscentral.dynamics.com/v2.0/{tenantid}/production/odatav4/$Metadata 使用IConfiden
-
使用数据库,php,js确定餐厅是否现在营业(就像yelp一样)
问题内容: 我想知道是否有人知道yelp如何确定哪些餐馆“现在营业”?我正在使用html / javascript /php开发类似的应用程序。我每天都会在数据库中有一列,并以“ 2243”格式(晚上10:43 pm)写以逗号分隔的小时数。因此,例如,如果一家餐厅开门供应午餐和晚餐,则可能是“ 1100,1400,1700,2200”。然后我会检查(使用js)当前时间是否落在当前日期的范围之一内。
-
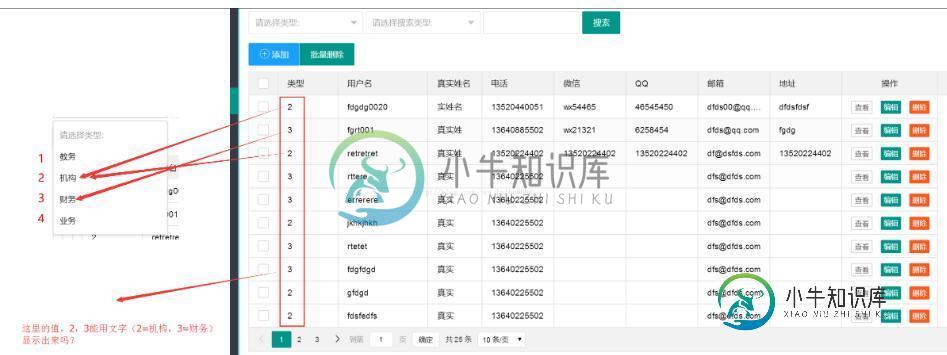 layui 数据表格 根据值(1=业务,2=机构)显示中文名称示例
layui 数据表格 根据值(1=业务,2=机构)显示中文名称示例本文向大家介绍layui 数据表格 根据值(1=业务,2=机构)显示中文名称示例,包括了layui 数据表格 根据值(1=业务,2=机构)显示中文名称示例的使用技巧和注意事项,需要的朋友参考一下 数据是用ThinkPHP5操作 类型是固定4个, 用layui templet - 自定义模板 方法一: 其它方法二:(ThinkPHP5读数据) 代码: 以上这篇layui 数据表格 根据值(1=业务,
-
AWS Glue Crawler将所有数据发送到Glue Catalog和Athena,而无需胶水作业
我刚接触AWS胶水。我正在使用AWS Glue Crawler从两个S3存储桶中抓取数据。我每个桶里有一个文件。AWS Glue Crawler在AWS Glue数据目录中创建了两个表,我还可以在AWS Athena中查询数据。 我的理解是,为了在雅典娜中获取数据,我需要创建粘合作业,这将在雅典娜中提取数据,但我错了。如果说Glue crawler将数据放置在Athena中而不需要Glue job
-
如何在应用程序模式下将java参数传递给Flink作业工件
我只是将Flink从1.10版升级到1.11版。在1.11中,Flink提供了新的特性,用户可以在Kubernetes上以应用程序模式部署作业。https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/kubernetes.html#deploy-session-cluster 在V1.10中,我们启动F
-
在Spring批处理中不可能将作业参数传递给step作用域bean
我正在使用Spring batch编写一个批处理,并试图将一个作业参数传递给item reader bean定义,但是当我执行该批处理时,我总是得到以下错误: 我只是不知道我做错了什么,因为根据我在网上发现的文档和其他帖子,一切似乎都很好。 编辑:我使用的是Spring 4.3.3和Spring Batch 3.0.7
-
 12.8字节跳动商业化技术大数据开发实习二面凉经30min
12.8字节跳动商业化技术大数据开发实习二面凉经30min1.自我介绍 2.解释数据库,表,索引 3.索引一遍加在哪里 4.问索引为什么能加快查找速度 5.解释第三范式 6.出了七八道走不走索引的判断题,解释理由(有个范围查找的走没走索引答错了,呜呜呜呜) 7.解释二叉树 8.问二叉树的几种遍历方式 9.算法题,问二叉树存不存在根节点到叶子结点路径上的数据和为一个target。 反问,问了部门业务场景,还稍微聊了一点数仓的东西。 12.16update,
-
Spring批处理作业执行监听器-访问JobStep定义的子作业的详细信息
我有一份工作(父母工作)的工作(孩子)。在父作业的jobexecution侦听器中,我希望访问每个子作业的所有细节(作业名、步骤名、读/写计数等)。我怎样才能做到这一点?
-
运行 cron 作业以从大量计划作业记录表中进行轮询是否不好?
我有一个表,cron 作业会每分钟轮询该表,以向其他服务发送消息。表中的记录实质上是计划在特定时间运行的活动。cron 作业只是检查哪些活动已准备好运行,并通过 SQS 将该活动的消息发送到其他服务。 当cron作业发现活动已准备好运行时,在通过SQS发送消息后,该记录将被标记为。有一个API允许其他服务检查计划活动是否已经完成。因此,需要保留那些记录的历史记录。 然而,我在这里关心的是这样的设计
-
前端 - vue2封装的业务组件获取数据的方法到底是应该在父组件里调用然后传数据进来,还是写在业务组件里,created时调用?
如果业务组件使用比较频繁,要抽成公共的,那么它的获取数据的方法如果不放在业务组件内,是不是意味着每次调用的时候都要写一遍,感觉会很恶心。但是如果写在内部,调用它的父组件应该在什么时机调用它?以及以什么方式调用它呢?