《花旗》专题
-
使用复制和选择将拼花板数据加载到表中时出现数据类型错误
我试图将parquet数据从AWS S3阶段移动到Snowflake中的表中,并不断得到数据类型错误。具体地说,无论我如何调整列,这个错误总是弹出 无法识别数值“|” null 我的代码如下:
-
我想用python中circle语句画一个八角形,但我花了半天只能画个八边形?
from turtle import * circle(40,step = 12) done
-
平时会对哪些内容进行付费?为什么愿意花钱去看或者听这些内容?
本文向大家介绍平时会对哪些内容进行付费?为什么愿意花钱去看或者听这些内容?相关面试题,主要包含被问及平时会对哪些内容进行付费?为什么愿意花钱去看或者听这些内容?时的应答技巧和注意事项,需要的朋友参考一下 对职业能力提升教学内容进行付费。因为职业能力关系到糊口薪资和职位晋升,一些还涉及到证书证明,需要通过网上注册学习,参加考试认证。 对于工作上的技术难点而网上免费回答又千篇一律雷同的模棱两可内容会付
-
亚马逊电子病历和S3,org。阿帕奇。火花sql。分析异常:路径s3:///var/表已存在
我正在试图找到Spark 2.0上的错误源。0,我有一个将表名作为键、数据帧作为值的映射,我循环遍历它,最后使用spark avro(3.0.0-preview2)将所有内容写入S3目录。它在本地运行非常完美(当然是本地路径而不是s3路径),但是当我在Amazon的EMR上运行它时,它运行了一段时间,然后它说文件夹已经存在并终止(这意味着相同的键值在for循环中被使用了不止一次,对吗?)。这可能是
-
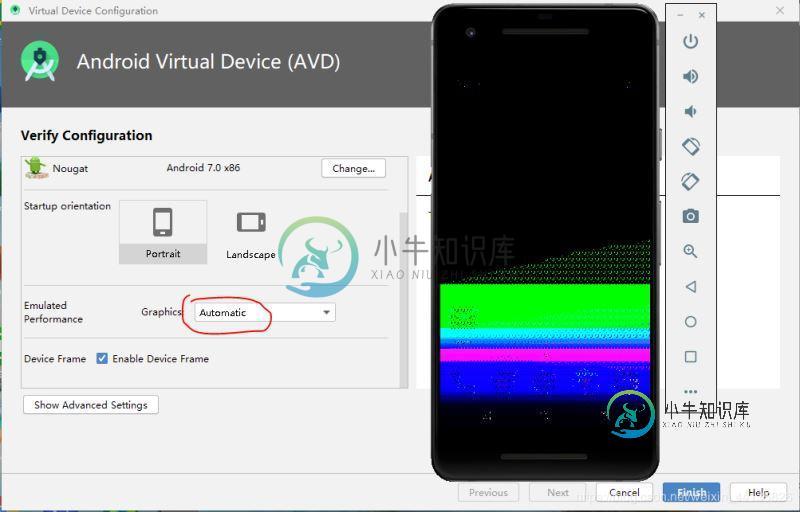 Android studio虚拟机在启动界面和桌面出现画面模糊花屏问题的解决方法
Android studio虚拟机在启动界面和桌面出现画面模糊花屏问题的解决方法本文向大家介绍Android studio虚拟机在启动界面和桌面出现画面模糊花屏问题的解决方法,包括了Android studio虚拟机在启动界面和桌面出现画面模糊花屏问题的解决方法的使用技巧和注意事项,需要的朋友参考一下 1.之前自己的虚拟机这样设置没问题,今天突然出现这样的花屏 2.最后解决了,解决方法,按照下边红框设置 3.问题方法说明: 之前看不太明白,就找的翻译 反思:之前是设置的自动(
-
为什么我可以使用花括号用另一个枚举类的值初始化一个枚举类?
我发现了Clang-12、Clang-13和Clang-14在
-
PHPExcel错误:不推荐使用带花括号的数组和字符串偏移量访问语法[重复]
我刚刚将我的更新为,我注意到弹出了这个错误: ErrorException(E\u不推荐)不推荐使用带大括号的数组和字符串偏移量访问语法 需要“类/PHPExcel”。php’; 这是触发上述错误的部分代码: 文件: 文件:
-
如何使用Serenity/JS进行量角器-茉莉花框架测试。serentiy支持量角器jasmine框架吗
我想为我使用protractor-jsamine框架构建的测试集成serenity报告。所做的所有探索只显示了serenity与量角器-Cucmber框架集成的结果。下面是我的配置文件示例。我应该添加什么来与宁静报告集成。目前我正在使用jasmine Reporter。
-
使用Intellij在括号()或方括号[]或花括号{}之间选择块,可以使用键盘或鼠标
我已经开始使用IntelliJ,我真的很喜欢它,但是与Eclipse相比,我错过了一些特性。其中之一是在{}、()或[]之间选择块,或者在块的打开/关闭之间跳转。例如,在eclipse中,如果您在一个开始括号之后双击,它将选择直到匹配的结束括号为止的所有内容,如下所示: 其中如果您在开头括号之后双击,那么它会选择直到结尾括号的所有内容,就在item5之后。我发现当您双击时,IntelliJ会选择方
-
如何发送一个工作在库伯内特斯的火花。无法实例化外部计划程序
2019-03-13 18:26:57错误sparkcontext:91-初始化sparkcontext时出错。org.apache.spark.sparkexception:无法在org.apache.spark.sparkcontext$.org$apache$spark$sparkcontext$$createTaskscheduler(Sparkcontext.scala:2794)...
-
Py4JJavaError:调用o389时出错。当试图将rdd数据框作为拼花文件写入本地目录时
我正试图使用Jupyter笔记本中的以下代码将数据框写入本地目录中的拼花地板文件: 我得到以下错误: 我检查了所有系统变量:Hadoop_home、Java_home、Spark_home、Scala_home、Pyspark_python、Pyspark_driver_python。 我已经使用Hadoop v2.7和Scala 2.12.4安装了Spark v3.2,更新到v2.12.10。我
-
为什么当我再次运行应用程序时,信标要花很长时间才能识别设备?
目前,我正在使用altbeacon库开发一个信标识别功能。我设计了一个特定的活动,使用函数在设备接近信标时触发一个事件。 当我第一次运行应用程序时,它会立即识别信标并触发一个事件。但在关闭app后再打开,或者活动离开后再返回时,会有20秒左右的延迟。 我尝试了下面的代码来解决这个问题,但它并没有解决我问的问题。
-
在完全输出模式下,Spark结构化流是否可以丢弃/控制中间状态?(火花2.4.0)
我有一个场景,我想处理来自kafka主题的数据。我有这个特定的java代码来从kafka主题中读取数据作为流。 我将其转换为 String,定义架构,然后尝试使用水印(用于后期数据)和窗口(用于分组和聚合),最后输出到 kafka sink。 问题 > 我是否正确理解在 kafka 接收器中使用完整输出模式时,中间状态将永远增加,直到我出现内存不足异常? 此外,完整输出模式的理想用例是什么?仅当中
-
堆排序与插入排序JMH基准:为什么我的插入实现了。花费更少的时间?
我已经实现了插入排序和堆排序。从理论上讲,堆排序具有 nlogn 时间复杂度,插入具有 n^2。为什么,那么对 100,000 个长数组进行排序需要大约 x6 倍的插入实现? 我使用JMH对每个排序算法的平均时间进行基准测试。以下是我的基准代码: 这是基准测试的结果: JMH 1.12(51天前发布)VM版本:JDK 1.8.0_65,VM 25.65-b01 VM调用程序:C:\Program
-
SSMS速度快而应用程序速度慢-为什么要花费这么长时间才能填充此DataSet?
问题内容: 我有一个从查询中填充的数据集,如下所示… (混淆查询字段) 我已经剖析了此查询,它在12秒钟内在SSMS中运行时返回了大约200行。请注意,我重新启动了服务器,并使用了必需的DBCC命令来确保未使用现有的执行计划。 但是,当我从.Net应用程序运行此查询时,将花费30秒以上的时间来填充数据集,并且默认的ADO.Net命令超时会超过30秒。 如果查询在12秒内运行,我只是看不到为什么要花