《DB》专题
-
使用Quarkus·蒙哥DB客户端
我已经开始用MongoDB客户端探索Quarkus。我在文档中遇到了很多锅炉板代码。(特别是。BSON) 参考: https://quarkus.io/guides/mongo-guide 我们不能利用注释来生成代码吗?这是有意避免反射开销吗?
-
AWS Λ 和迪纳摩DB 空响应
我正在尝试从Lambda函数写入DynamoDB表。当我测试运行这个函数时,它返回null,没有错误消息,也没有任何东西写入表中。功能如下。我已经为这个功能设置了一个服务角色,它具有允许访问“产品”表的权限策略。我看到一些教程提到创建一个“AWS Lambda应用程序”,然后创建Lambda函数,但我不认为这对我的使用是必要的。 我还尝试过使用文档客户端 我得到的错误是:“发电机。文档客户端不是构
-
Azure Databricks -导出和导入DBFS文件系统
我们刚刚在资源组中创建了一个新的 Azure 数据砖资源。在同一资源组中,有一个 Azure 数据砖的旧实例。从这个旧的数据砖实例开始,我将数据存储在dbfs中的数据复制到最新的数据砖实例中。我该怎么做?我的想法是使用FS命令将数据从一个dbfs复制或移动到另一个数据库,可能是装入卷,但我不明白我该怎么做。你有什么迹象吗? 谢谢,弗朗西斯科
-
数据砖dbfs是否支持文件元数据,如文件/文件夹创建日期或修改日期
我正试图在databricks笔记本的目录中查找最新的拼花文件。dbfsutils.fs.ls似乎不支持任何有关文件或文件夹的元数据。python中有没有其他方法可以做到这一点?数据存储在azure数据湖中,该数据湖安装在“/mnt/foo”下的DBFS上。感谢任何帮助或指点。
-
有没有办法将dbfs(数据库)路径中的csv文件分配给pyspark中的变量?
我正在数据库中执行以下代码,将火花数据帧转换为csvdataframe.csv并存储在dbfs路径中。 这个文件是在dbfs:/dataframe.csv中创建的。我需要为这个文件指定一个文件名,这样我就可以将这个文件附加到邮件中。我正在使用: 但这给我带来了错误:<code>IOError:文件数据帧。csv不存在 有人能帮我吗?
-
无法将CSV文件从Databricks集群DBFS导入h2o
我已在我的AWS Database ricks集群上成功安装了两个h2o,然后成功启动了h2o服务器: 当我尝试导入存储在Database ricks DBFS中的iris CSV文件时: 我得到一个H2OResponseError:服务器错误water . exceptions . h2onotfoundargumentexception CSV文件绝对在那里;在同一个Databricks笔记本
-
如何在databricks中读取挂载的dbc文件?
我尝试读取数据块中的dbc文件(从s3存储桶装载)。文件路径是: 如何使用火花读取此文件? 我尝试了下面的代码: 但它生成并错误: 谢谢帮忙!
-
数据砖 - 将 dbfs:/文件存储文件下载到我的本地计算机
通常我使用下面的URL将文件从数据砖DBFS文件存储下载到我的本地计算机。 然而,这一次文件没有被下载,URL把我带到了Databricks的主页。有没有人对我如何从DBFS下载文件到本地有什么建议?或者应该如何修复URL以使其工作? 任何建议将不胜感激! 沙俊春
-
Azure Database ricks中DBFS的数据大小限制是多少
我在这里读到,AWS数据砖的存储限制为单个文件的5TB,我们可以存储任意数量的文件,那么同样的限制是否适用于Azure数据砖?或者,是否对 Azure 数据砖应用了其他限制? 更新: @CHEEKATLAPRADEEP感谢您的解释,但是,有人能分享一下背后的原因吗:“我们建议您将数据存储在挂载对象存储中,而不是DBFS根目录中” 我需要在Power BI中使用DirectQuery(因为数据量巨大
-
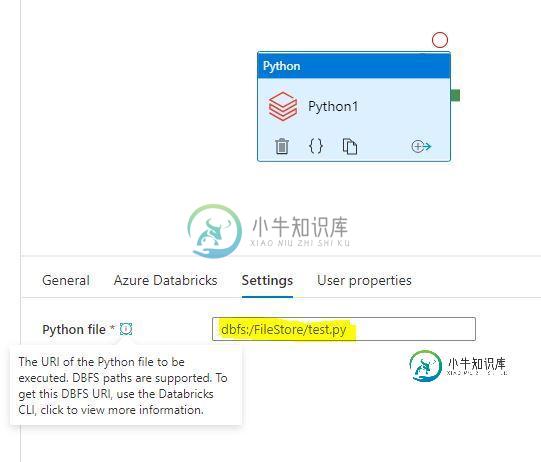 ADF数据块python活动从blob存储中而不是从dbfs中选择python脚本
ADF数据块python活动从blob存储中而不是从dbfs中选择python脚本我正在从 Azure 数据工厂运行数据砖 python 活动。我想从 Azure blob 存储/数据湖中选择 python/shell 脚本,而不是 dbfs 路径。我目前的ADF数据砖蟒蛇活动不允许没有“dbfs:/”。 你能帮我一下吗?
-
 为什么从databricks spark笔记本(hadoop fileUtils)到DBFS装载位置的写入速度比写入DBFS根位置慢13倍?
为什么从databricks spark笔记本(hadoop fileUtils)到DBFS装载位置的写入速度比写入DBFS根位置慢13倍?写入 /dbfs/mnt(blob存储)需要2小时。同样的工作需要8分钟才能写入 /dbfs/FileStore. 我想了解为什么这两种情况下的写性能不同。我还想知道/dbfs/FileStor使用哪个后端存储? 我知道DBFS是可扩展对象存储之上的抽象。在这种情况下,对于 /dbfs/mnt/blob 存储和 /dbfs/文件存储/,应该需要相同的时间。 问题陈述: 源文件格式:.tar.gz
-
将CSV压缩为dbfs中的ZIP文件(数据块文件存储)
我正在尝试将位于azure datalake中的csv压缩为zip。该操作是使用datricks中的python代码完成的,我在其中创建了一个挂载点以将dbfs与datalake直接关联。 这是我的代码: 但是我收到了这个错误: 有什么办法吗? 提前感谢。
-
 Azure databricks DBFS mount not 可见
Azure databricks DBFS mount not 可见我正在尝试使用python notebook使用下面的代码将azure存储blob挂载到azure数据块中。 装载是成功的,我能够看到使用也在我的 Linux VM 中使用 DBFS CLI。 但在UI中不可见,也不能从python notebook < code > FileNotFoundError:[Errno 2]没有这样的文件或目录:“/mnt/test mount/”。 有人能告诉我你
-
Cosmos DB更改具有任意数量豆荚的库伯内特斯集群中的提要
我的Cosmos数据库中有一个集合,我想观察它的变化。我有很多文件(官方和非官方)解释如何做到这一点。但有一件事我无法以可靠的方式工作:当我没有任何实例名称的公共引用时,如何接收对多个实例的相同更改? 我这样说是什么意思?嗯,我正在库伯内特斯集群(AKS)中运行我的工作负载。我在集群中有一个可变数量的实例,它们应该观察我的集合。为了使更改提要正常工作,我必须为每个实例有一个唯一的实例名称。我唯一的
-
spring Hibernate,GET Query,Hibernate Query形成成功,我可以从DB中获取数据,但当我从浏览器中击中它的抛出404
我现在正在用Hibernate学习spring。我有一个简单的Customer表,其中列是“id”、“first_name”、“last_name”、“email”。 我使用hibernate查询数据库,并将所有客户的结果作为输出。我已经使用了spring boot和MVC一样… 问题是我能够成功地从数据库中提取数据,并且能够在控制台中打印…但当我试图通过浏览器通过GET请求访问它时,它会抛出一个