
为什么从databricks spark笔记本(hadoop fileUtils)到DBFS装载位置的写入速度比写入DBFS根位置慢13倍?

写入 /dbfs/mnt(blob存储)需要2小时。同样的工作需要8分钟才能写入 /dbfs/FileStore.
我想了解为什么这两种情况下的写性能不同。我还想知道/dbfs/FileStor使用哪个后端存储?
我知道DBFS是可扩展对象存储之上的抽象。在这种情况下,对于 /dbfs/mnt/blob 存储和 /dbfs/文件存储/,应该需要相同的时间。
问题陈述:
源文件格式:.tar.gz
平均尺寸:10 mb
tar.gz文件数:1000
每个tar.gz文件包含大约20000个csv文件。
要求:解压缩tar.gz文件并将CSV文件写入blob存储/中间存储层以进行进一步处理。
unTar并写入挂载位置(附截图):

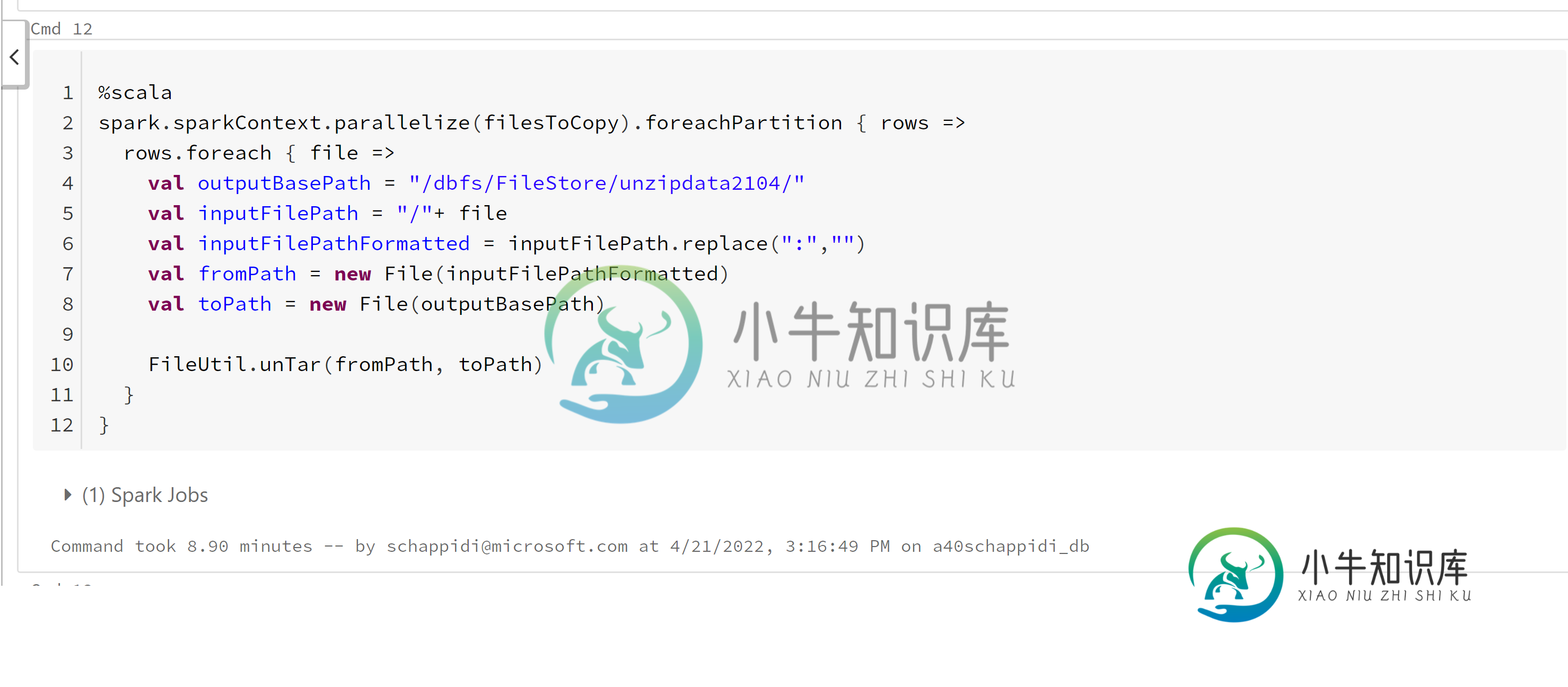
问题:为什么写入DBFS/FileStore或DBFS/databricks/driver比写入DBFS/mnt存储快15倍?
DBFS根(/FileStore、/databricks-dataset、/datatricks/driver)在后端使用什么存储和文件系统?每个子文件夹的大小限制是多少?
共有1个答案

可能有多种因素会影响这一点,但它需要更多信息来调查:
-
< li >您的< code>/mnt装入点可能指向另一个区域中的blob存储,因此您有更高的延迟时间 < li >例如,如果从其他集群对blob存储进行大量读取/写入或列表操作,您将遇到限制,这可能会导致Spark任务重试(如果有任何任务出错,请检查Spark UI)。另一方面,< code>/FileStore位于一个专用的blob存储中(所谓的DBFS根),它并没有这样加载。
通常,对于 DBFS 根数据库,将使用 Azure Blob 存储,而不是 ADLS。具有分层命名空间的 ADLS 具有额外的操作开销,因为它需要检查权限等。这也可能会影响性能。
但要解决此问题,最好打开支持票证,因为它可能需要后端调查。
另外,请注意,DBFS根应该只用于临时数据,因为它只能从workspace访问,所以您不能与其他工作区或其他用户共享其上的数据。
-
问题内容: 我面临一个非常奇怪的问题:使用Redis时,我的写入速度非常糟糕(在理想情况下,写入速度应该接近RAM上的写入速度)。 这是我的基准: 是生成随机字符串的类(arg是字符串长度) 以下是几个结果: [写入] nb:100000 |时间:4.408319378 |速度:0.713905907055318 MB / s [写入] nb:100000 |时间:4.4139469070553
-
我正在尝试使用writefile,但由于某种原因,它在./events文件夹之外使用。 我尝试使用fs, xp.js试图在同一个文件夹中写入level.json。
-
本文向大家介绍IOS入门笔记之地理位置定位系统,包括了IOS入门笔记之地理位置定位系统的使用技巧和注意事项,需要的朋友参考一下 前言:关于地理位置及定位系统,在iOS开发中也比较常见,比如美团外面的餐饮店铺的搜索,它首先需要用户当前手机的位置,然后在这个位置附近搜索相关的餐饮店铺的位置,并提供相关的餐饮信息,再比如最常见的就是地图导航,地图导航更需要定位服务,然后根据用户的目的地选出一条路线。其实
-
我在Jupyter Notebook中拖放一个图像。默认情况下,它会给我一个代码: 我能做些什么来“无需”<代码>
-
问题内容: 我正在尝试使用BufferedImage.TYPE_USHORT_GRAY将16位灰度图像数据写入png。通常我会这样写图像: 然后: 设置像素,最后: 写到png图像。 但是现在我将其作为图像: 如何将像素保存为该格式?将setRGB()与16位整数一起使用似乎无效,当我打开保存的png文件时,我看到很多条带发生。 我尝试保存从0到65535的简单渐变,然后在灰度图像上使用setRG
-
问题内容: 我正在将 FILEPATH 参数写入属性文件,如下所示。 文件 路径 为 D:\ filelog.txt 写入时,控制台打印如下。 但是当我打开属性文件时,内容就像.. 有人建议我,我在这里真正在想什么..? 问题答案: 只是打电话。您将看到像输入一样返回“ D:\ filelog.txt”。