《垂直分表》专题
-
数据库 - 或许我们都被分库分表约束了思维?
概述 这篇文章没什么太多的干货,纯纯是一篇讨论和思考帖。 从业数据库领域三年有余了,从分库分表中间件到数据库团队内核学到了很多东西。也接触了很多项目,包括TiDB、Vitess、Polardb、StarDB等等。 国内的项目好像很多都聚焦于分库分表的概念,包括很多的数据库团队都在尝试这个概念的落地和沉溺于性能的跑分。 最近我在预览MySQL官方,看到了Partitioning的概念,而且占据了很大
-
Maven surefire插件使java 11上的jvm崩溃(通过直接写入分叉jvm 1中的本地流而损坏了STDOUT)
使用Java11运行maven构建时,构建在运行测试时发出以下警告: ...之后是构建失败后的以下stderr输出: 也就是说,与大多数在最新版本的插件中解决的问题不同,在surefire和JVM的最新版本中,这个问题似乎再次抬头。 欢迎任何解决方案或工作方法。我正在使用以下版本: Apache Maven 3.5.3(3383C37E1F9E9B3BC3DF5050C29C8AFF9F29529
-
后端 - GridFS将文件分成多个块存储的好处是什么,为何不直接存一个整个文件呢?
MongoDB GridFS,它将大文件分割成多个块进行存储,并提供了一种方便的方式来管理和检索这些文件。 请问: 1、GridFS将文件分成多个块存储的好处是什么,为何不直接存一个整个文件呢? 2、GridFS将文件分成多个块存储,查询获得整个文件会不会有性能影响?
-
与直接存储日期相比,使用日期维度表有什么优势?
问题内容: 我需要存储相当大的数据历史记录。我一直在研究存储此类档案的最佳方法。看来,数据仓库方法是我需要解决的问题。强烈建议使用日期维度表,而不要使用日期本身。谁能向我解释为什么单独使用一张桌子会更好?我不需要汇总任何数据,只需在过去的任何一天中快速高效地访问它们即可。我确定我丢失了一些东西,但是我看不到将日期存储在单独的表中比将日期存储在存档中有什么好处。 问题答案: 好吧,一个好处是,作为一
-
Python分部
问题内容: 我试图将一组从-100到0的数字归一化到10-100的范围,并且遇到了问题,只是注意到即使根本没有任何变量,这也无法评估我期望的方式: 浮动划分也不起作用: 如果除法的任一侧都转换为浮点数,它将起作用: 第一个示例中的每一边都被评估为一个int,这意味着最终答案将被转换为一个int。由于0.111小于.5,因此将其舍入为0。在我看来,这不是透明的,但我想是这样的。 有什么解释? 问题答
-
JDBC分页
问题内容: 我想使用JDBC实现分页。我想知道的实际情况是“如何分别从数据库中获取第1页和第2页的前50条记录,然后再获得50条记录” 我的查询是[数据表包含20,000行] 对于第1页,我可以获得50条记录,对于第2页,我想要获得下50条记录。如何在JDBC中有效地实现它? 我已经搜索过,发现这是跳过首页记录的方法,但是在大型结果集上花费一些时间,我不想花这么多时间。另外,我不想在查询中使用和+
-
ASP.NET 分页
本文向大家介绍ASP.NET 分页,包括了ASP.NET 分页的使用技巧和注意事项,需要的朋友参考一下 示例 ObjectDataSource 如果使用ObjectDataSource,几乎已经为您处理了所有事情,只需告诉GridViewAllowPaging并给它一个即可PageSize。 手动装订 如果手动绑定,则必须处理该PageIndexChanging事件。只需设置DataSource和
-
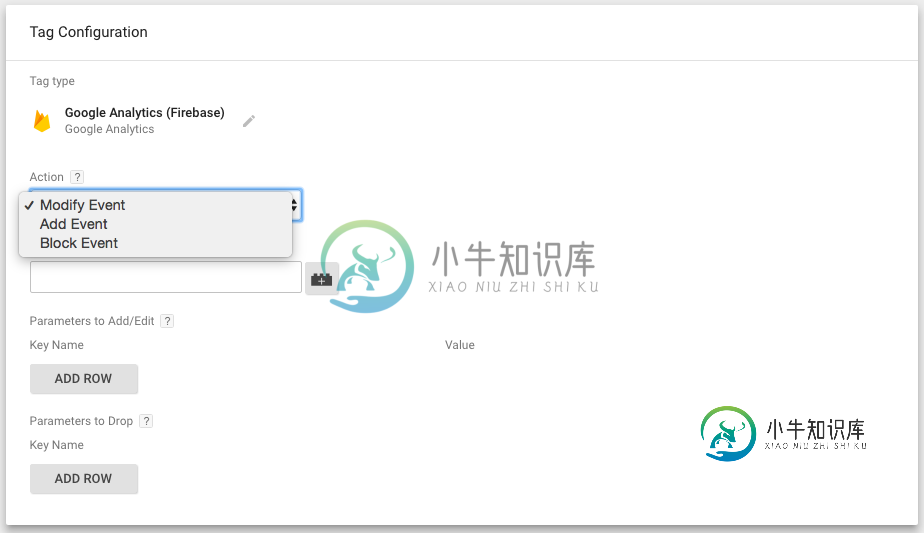 Firebase分析
Firebase分析这个问题是关于为什么Google Analytics(分析)Firebase需要GTM。在这个问题上有一个类似的帖子,但它与如何有关。我正在寻找为什么人们想要在已经强大的Google Analytics for Firebase旁边实现GTM的原因。 2017年5月,“Firebase Analytics”更名为“Google Analytics for Firebase”。这不应与移动应用程序(
-
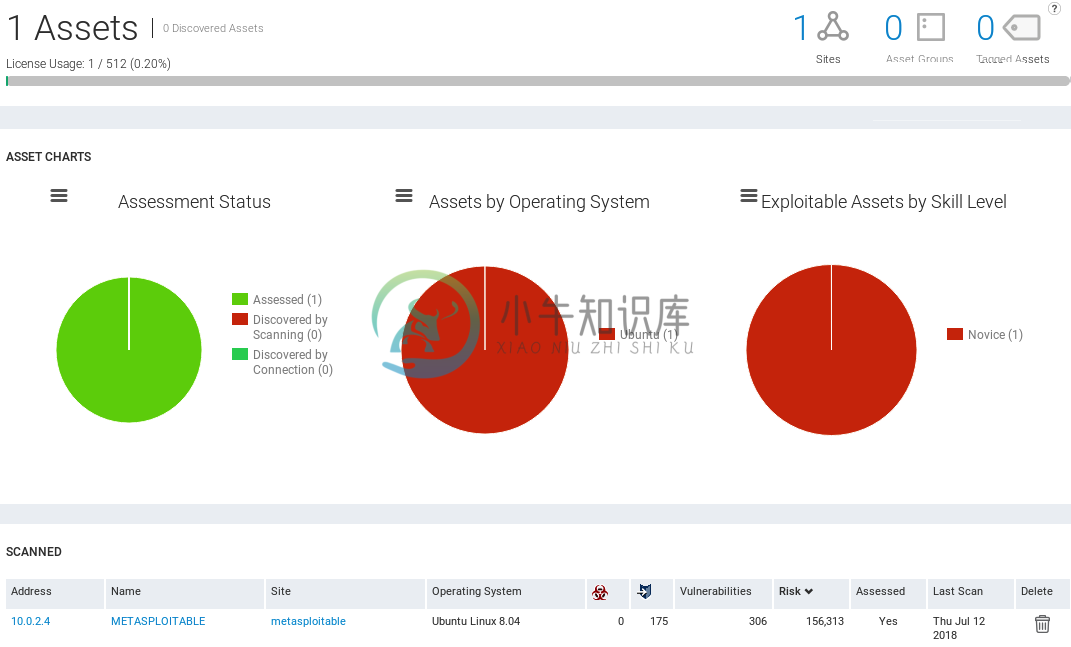 Nexpose分析
Nexpose分析扫描结束后,我们进入Asserts页面。在下面的屏幕截图中,可以看到我们扫描了一个资产,并且资产在Ubuntu上运行。我们需要入侵这项资产的技能是Novice: 正如我们在前面的截图中看到的,Nexpose展示了比Metasploit社区更多的信息。Nexpose是一个更高级的漏洞管理框架。 我们可以在下面的屏幕截图中看到,我们扫描了一个METASPLOITABLE目标,该站点是Global,它在
-
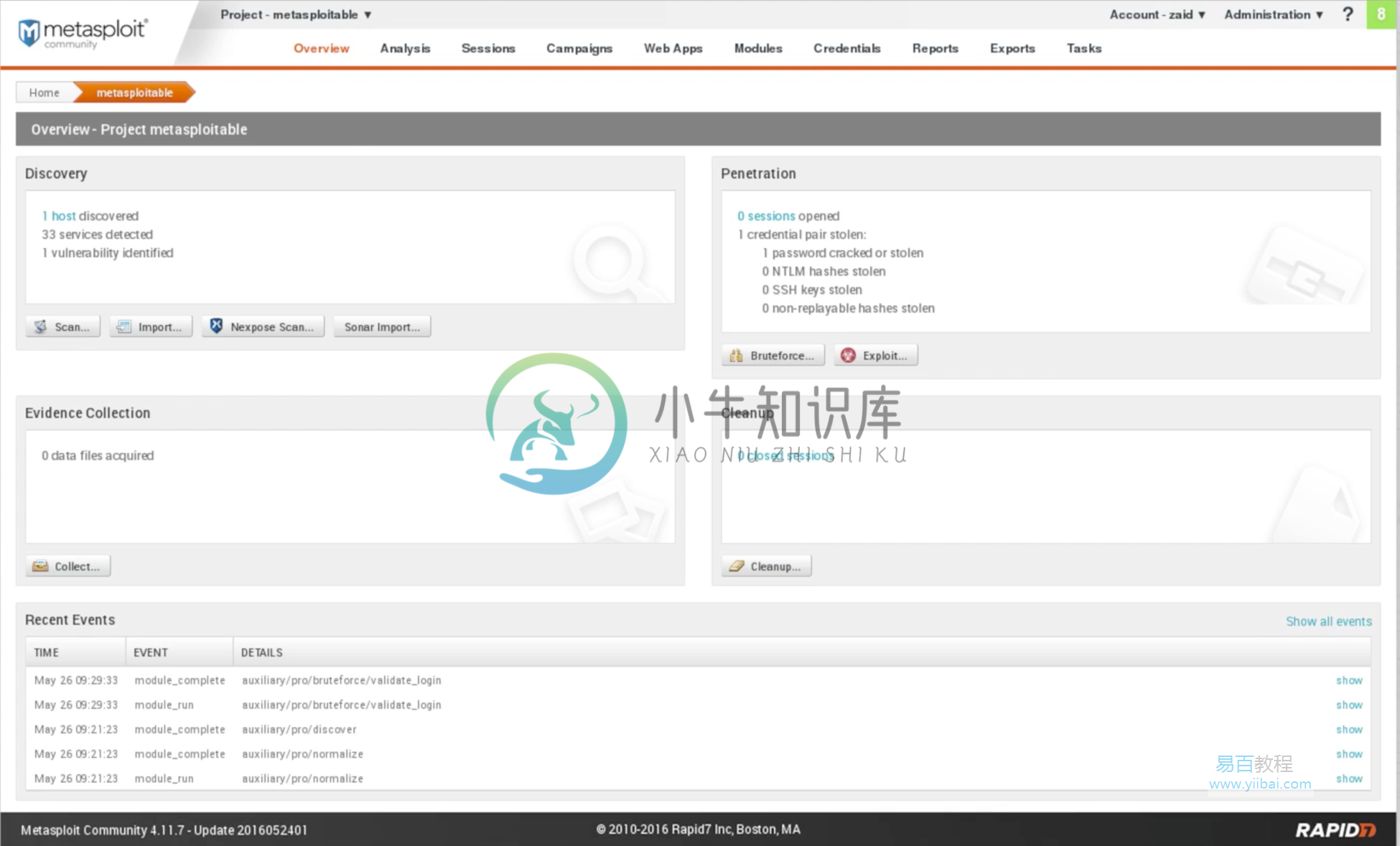 MSFC分析
MSFC分析扫描过程结束大约需要两分钟。如果点击Metasploitable机器,可以看到发现了一个新热点,其上安装了33个新服务,并且还设法检测到一个漏洞: 现在点击Analysis | Hosts,看到主机IP为,并且已经正确扫描。它有VMware,它有服务器,它是在Linux 8.04上运行: 如果点击IP 10.0.2.4,就能看到已安装的服务,如下面的屏幕截图所示: 在上面的屏幕截图中,NAME显示
-
Elasticsearch分析
主要内容:分析器,令牌器/标记生成器,令牌过滤器,字符过滤器当在搜索操作期间处理查询时,任何索引中的内容由分析模块分析。该模块由分析器,分词器,分词器过滤器和字符过滤器组成。 如果没有定义分析器,则默认情况下注册内置的分析器,分词器,分词器过滤器和字符过滤器到分析模块。例如。 请求正文 响应 分析器 分析器由令牌器和可选的令牌过滤器组成。这些分析器在具有逻辑名的分析模块中注册,可以在映射定义或某些API中引用它们。有许多默认分析仪如下 - 编号 分析器 描
-
 Bootstrap 分页
Bootstrap 分页主要内容:分页(Pagination),实例,实例,实例,翻页(Pager),实例,实例,实例,分页更多实例本章将讲解 Bootstrap 支持的分页特性。分页(Pagination),是一种无序列表,Bootstrap 像处理其他界面元素一样处理分页。 分页(Pagination) 下表列出了 Bootstrap 提供的处理分页的 class。 Class 描述 示例代码 .pagination 添加该 class 来在页面上显示分页。 .disabled, .active 您可以自定义链接,
-
Bootstrap4 分页
主要内容:实例,当前页页码状态,实例,不可点击的分页链接,实例,分页显示大小,实例,面包屑导航,实例,分页的对齐方式,实例网页开发过程,如果碰到内容过多,一般都会做分页处理。 Bootstrap 4 可以很简单的实现分页效果。 要创建一个基本的分页可以在 <ul> 元素上添加 .pagination 类。然后在 <li> 元素上添加 .page-item 类,<li> 元素的 <a> 标签上添加 .page-link 类: 实例 <ul class="pagination"> <li class
-
 MongoDB分片
MongoDB分片主要内容:MongoDB 中的分片,分片实例分片是跨多台机器存储数据的过程,它是 MongoDB 满足数据增长需求的方法。随着数据的不断增加,单台机器可能不足以存储全部数据,也无法提供足够的读写吞吐量。通过分片,您可以添加更多计算机来满足数据增长和读/写操作的需求。 为什么要分片? 在复制中,所有写操作都将转到主节点; 对延迟敏感的查询仍会转到主查询; 单个副本集限制为 12 个节点; 当活动数据集很大时,会出现内存不足; 本地磁盘不够大;
-
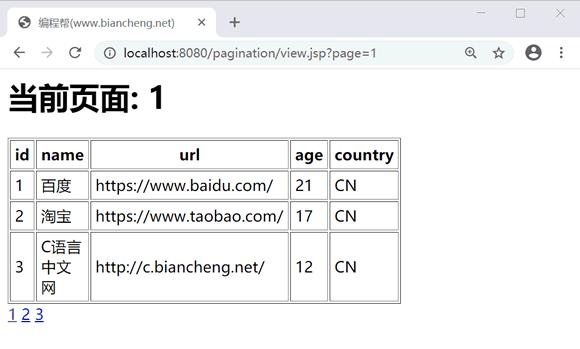 JSP分页
JSP分页主要内容:实现分页步骤,示例当数据有几万、几十万甚至上百万时,用户必须要拖动页面才能浏览更多的数据,很大程度的影响了用户体验。这时可以使用分页来显示数据,能够使数据更加清晰直观,且不受数量的限制。 分页的方式主要分为两种: 将查询结果以集合等形式保存在内存中,翻页时从中取出一页数据显示。该方法可能导致用户浏览到的是过期数据,且如果数据量非常大,查询一次数据就会耗费很长时间,存储的数据也会占用大量的内存开销。 每次翻页时只从数