《垂直分表》专题
-
如何使用streams Java 8按键分组列表并拆分值
我需要对ABC列表进行分组,同时我还想拆分值。输入: 请建议,谢谢。
-
如何选择合适的分表键、路由规则、分片数
什么是分表键 分表键即分库/分表字段,zebra里面叫做维度,是在水平拆分过程中用于生成拆分规则的数据表字段。Zebra 根据分表键的值将数据表水平拆分到每个物理分库中。 数据表拆分的首要原则,就是要尽可能找到数据表中的数据在业务逻辑上的主体,并确定大部分(或核心的)数据库操作都是围绕这个主体的数据进行,然后可使用该主体对应的字段作为分表键,进行分库分表。 业务逻辑上的主体,通常与业务的应用场景相
-
Bootstrap Table表格一直加载(load)不了数据的快速解决方法
本文向大家介绍Bootstrap Table表格一直加载(load)不了数据的快速解决方法,包括了Bootstrap Table表格一直加载(load)不了数据的快速解决方法的使用技巧和注意事项,需要的朋友参考一下 bootstrap-table是一个基于Bootstrap风格的强大的表格插件神器,官网:http://bootstrap-table.wenzhixin.net.cn/zh-cn/
-
Spring Webflux-WebClient:如何直接获得嵌套在更大响应中的列表?
关于Spring Webflux的小问题,以及如何直接获取http响应中的Pojo嵌套列表。 我们正在使用一个API,它的响应类似于 基本上,它是一个响应,其中包含很多我不需要的字段,加上其中的类型列表元素,我想直接获取。 如果我创建两个不同的类,第一个 第二个 并像这样调用Webclient: 它工作得很好!我只需要携带一个我在代码中不需要的非常大的类,每次用getter检索我需要的嵌套列表。
-
通过Office 365直接登录使用兑换服务获取日历列表
我有一个web应用程序,我使用office 365登录(sharepoint)来验证用户,然后重定向到我的web应用程序。 现在我想访问登录的Office 365用户的日历并添加事件,获取日历列表等。我已经查看了Office 365 API,但它使用我不想使用的OAuth2身份验证。 因此,我选择了Exchange eService API,但它需要用户的Networks凭据,这意味着我必须为每个
-
直接解析json文件并将其存储到hadoop,然后直接向hadoop查询以获取所需的数据
在我的项目中,大量数据来自json格式的服务器。为了获取这些数据,计划每小时运行一个cron任务,它会返回我们保存到文件中的那一个小时的数据。这组数据将用于分析目的,并将有很多测量点,基于这些测量点将呈现分析报告和图表。现在由于数据会很重,决定使用HADOOP进行数据存储。我看了很多文章,发现有一个用于输入处理的映射器文件和用于输出的还原器文件,但没有找到动态数据的好例子。 但我想知道如何直接解析
-
Apache Kafka分区未使用RoundRobin分区器均匀分布
我正在使用Kafka Producer和RoundRobin分区器来处理一个有12个分区的主题。 代码可在此处找到https://github.com/apache/kafka/blob/2.8/clients/src/main/java/org/apache/kafka/clients/producer/RoundRobinPartitioner.java 我面临的问题是,这个分区程序让分区正确
-
低分辨率Mandelbrot分形不。。。足够高的分辨率?
好的,这里有一个奇怪的问题,我有问题(用gcc btw编译) 下面是用于命令提示的Mandelbrot分形生成器的源代码。我以前做过这项工作,我想加快自己的测试速度,看看我能以多快的速度生成命令提示符中实际生成Mandelbrot分形所需的代码。我经常这样做是为了给自己找点乐子 不管怎样,我遇到了一个新问题,我不太明白问题是什么。当分形呈现时,无论我设置了多少次迭代或什么转义值,它都将始终显示为椭
-
2.5. 分解成分中的信号(矩阵分解问题)
校验者: @武器大师一个挑俩 @png 翻译者: @柠檬 @片刻 2.5.1. 主成分分析(PCA) 2.5.1.1. 准确的PCA和概率解释(Exact PCA and probabilistic interpretation) PCA 用于对一组连续正交分量中的多变量数据集进行方差最大方向的分解。 在 scikit-learn 中, PCA 被实现为一个变换对象, 通过 fit 方法可以降维成
-
分组Python元组列表
问题内容: 我有一个这样的(标签,计数)元组列表: 由此,我想对所有具有相同标签的值求和(相同的标签始终相邻),并以相同的标签顺序返回列表: 我知道我可以用以下方法解决它: 但是,有没有更Pythonic /优雅/有效的方法来做到这一点? 问题答案: 可以做你想做的:
-
表定义/分区/建模
每个最终用户都与站点进行交互:查看产品、将产品添加到购物车和购买产品(我们称之为用户事件)。我想存储最近30天(或180天,如果可能的话)的活动。 需要考虑的事情: > 站点大小不同!我们有一些“重”网站有10M的最终用户,但我们也有一些“轻”网站有几百/几千个用户。 事件没有唯一的ID。 用户一次可以有多个事件,例如,他们可以查看包含多个产品的页面(但为了简化,我们可以不受此限制)。 粗略估计:
-
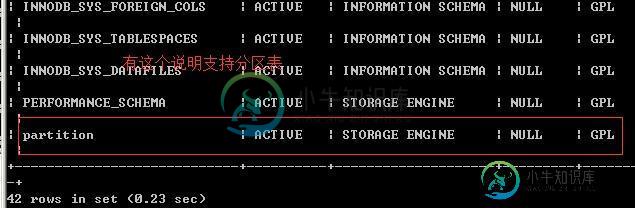 MySQL优化之分区表
MySQL优化之分区表本文向大家介绍MySQL优化之分区表,包括了MySQL优化之分区表的使用技巧和注意事项,需要的朋友参考一下 当数据库数据量涨到一定数量时,性能就成为我们不能不关注的问题,如何优化呢? 常用的方式不外乎那么几种: 1、分表,即把一个很大的表达数据分到几个表中,这样每个表数据都不多。 优点:提高并发量,减小锁的粒度 缺点:代码维护成本高,相关sql都需要改动 2、分区,所有的数
-
如何分割成表行
我已经尝试了这里给出的许多解决方案,但我无法将这段代码拆分为多个表行。非常感谢!! 更新:如果我的问题不清楚,很抱歉。我想喝5杯,然后开始新的一排,希望这能有所帮助。谢谢你的回答! 有人能帮我吗?Minesh的代码很接近,但我仍然会出错,请参阅下面的评论。非常非常感谢!!
-
分段错误-双链表
我正在实现一个类似于队列的双链接列表。因此,当我向列表中添加节点(例如5个节点)并清空列表并尝试向列表中添加新节点时,会出现分段错误(核心转储)。我不知道它为什么这么做。你能解释一下吗?
-
 Jasper报表Excel列分段
Jasper报表Excel列分段要求:开发10个报告和导航到每个报告时,点击超链接放置在导航菜单上。 当导出到excel时,每个子报表都应该放在单独的excel表中,excel列分段应该与报表列相匹配。完成了90%的工作。 只剩下excel分段问题。