《集群化》专题
-
集群之二GossIP
主要内容:一、P2P通信,二、GossIP,二、网络管理,三、总结一、P2P通信 传统的互联网设计,包括现在主流的互联网系统,基本是中心化的,也就是说,一切的网上活动,都需要经过一个服务中心(这是一个逻辑表述,不要和一个点,一个机器,一个机房等混淆),用户所有的动作,从理论上讲,都可以被服务端记录和控制。它和现实社会是对应的,比如去火车站买票,必须去火车站(虽然说现在不用亲自去火车站,但中心化反而更严重了)。买东西,必须去超市和菜市场,就是要打个电话,也得去电信
-
操作etcd集群 - 在容器内运行etcd集群
注: 内容翻译自 Run etcd clusters inside containers 下列指南展示如何使用 static bootstrap process 来用rkt和docker运行 etcd 。 rkt 运行单节点 etcd 下列 rkt 运行命令将在端口 2379 上暴露 etcd 客户端API,而在端口 2380上暴露伙伴API。 当配置 etcd 时使用 host IP地址。 ex
-
带有Docker群模式的Redis集群
我是Docker Swarm的新手。我试图用compose文件在Docker swarm上部署redis集群。我希望redis集群使用端口6380,所以我配置了端口,并让它在compose文件中挂载redis配置文件。 但是当我运行时,我得到了一个错误的声明,“对不起,集群配置文件redis-node.conf已经被不同的Redis集群节点使用了。请确保不同的节点使用不同的集群配置文件。” 这是我
-
Flink作业集群与会话集群-部署和配置
我正在研究Flink 1.9.1的docker/k8s部署可能性。 我看完了[1][2][3][4]。 目前,我们确实认为,我们将尝试采用工作集群方法,尽管我们想知道社区的这一趋势是什么?我们不希望每个Flink集群部署多个作业。 不管怎样,我想知道一些事情: > 在这两种情况下,Flink的UI都显示每个任务管理器有4个CPU。 如果使用作业群集,如何重新提交作业。我指的是这个用例。你可能会说我
-
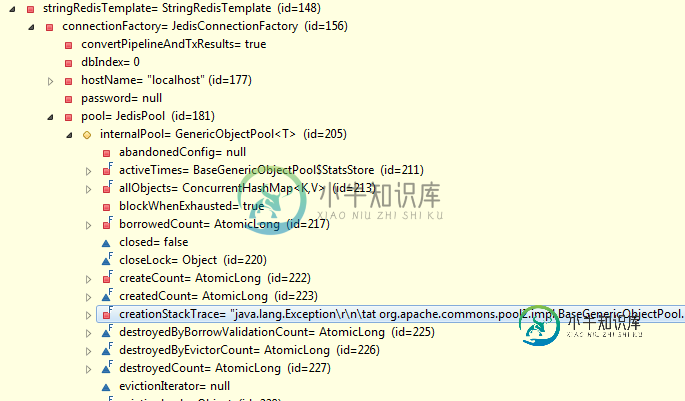 Redis集群与Spring boot的集成
Redis集群与Spring boot的集成我有一个redis集群,有主服务器、从服务器和3个哨兵服务器。主从映射到dns名称node1-redis-dev.com、node2-redis-dev.com。redis服务器版本为2.8 我在application.properties文件中包含以下内容。 但是,当我检查StringRedisTemplate时,在JedisConnectionFactory的hostName属性下,我看到的是
-
基于SQL中的群集索引和非群集索引优化查询?
问题内容: 我最近一直念叨如何和作品。我的理解很简单(如果有错,请纠正我): 的数据结构,其背和IS :根据索引列(或键)对数据进行物理排序。每个只能有一个。如果在创建表的过程中未指定No ,则服务器将在上自动创建一个。 问题1 :由于数据是根据索引进行物理排序的,因此这里不需要额外的空间。这样对吗?那么,当我删除创建的索引时会发生什么? :在中,树的包含列值和指向数据库中实际行的指针(行定位符)
-
SQL Oracle计数群集
问题内容: 我有一个基于时间戳的数据集。 我想查询并返回 关闭次数:在这种情况下,关闭次数为3,基于0为ON和1为OFF。 每次关闭之间的时间段 例子: 我正在使用Oracle 问题答案: 使用ORACLE中的LEAD和LAG函数,您可以构建以下查询: 1.关机次数: 2.期间每次关闭之间
-
kubeadm canot联接集群
您的Kubernetes控制飞机已成功初始化! 要开始使用集群,您需要以普通用户的身份运行以下内容: mkdir-p$home/.kube sudo cp-i/etc/kubernetes/admin.conf$home/.kube/config sudo chown$(id-u):$(id-g)$home/.kube/config 和输出: 此节点已加入群集:*证书签名请求已发送到apiserv
-
多集群Kafka设置
我想建立一个多kafka集群,大约有3个zookeeper实例,每个集群中有3个kafka代理,每个kafka经纪人大约有5个主题和5个分区。有什么设置指南可以参考吗? PS:我可以找到带有多个Kafka代理的单个zookeeper实例的信息,但不能找到带有多个zookeeper实例的设置。
-
Flink Standalone 集群部署
一、部署模式 Flink 支持使用多种部署模式来满足不同规模应用的需求,常见的有单机模式,Standalone Cluster 模式,同时 Flink 也支持部署在其他第三方平台上,如 YARN,Mesos,Docker,Kubernetes 等。以下主要介绍其单机模式和 Standalone Cluster 模式的部署。 二、单机模式 单机模式是一种开箱即用的模式,可以在单台服务器上运行,适用于
-
EKS上的Flink群集
我对Flink和库伯内特斯是新手。我计划创建一个flink流作业,将数据从文件系统流到Kafka。 使用工作正常的flink job jar(本地测试)。现在我正试图在kubernetes主持这项工作,并希望在AWS中使用EKS。 我已经阅读了有关如何设置flink群集的官方flink文档。https://ci.apache.org/projects/flink/flink-docs-releas
-
Kubernetes Redis群集问题
我试图在CentOS上使用kubernetes创建redis集群。我的kubernetes主服务器运行在一台主机上,而kubernetes从服务器运行在两台不同的主机上。 kubectl create-f RC.Yaml 使用的Redis-config文件 我使用以下命令创建kubernetes服务。 ./redis-trib.rb创建-副本1 172.30.79.2:6379 172.30.79
-
Spring boot OAuth2 SSO集群
我使用spring Boot、spring Oauth2构建SSO服务器。当在独立模式下,令牌存储在内存中,它运行良好。但现在,我想在多个服务器上运行SSO服务器。我用JDBC更改了存储策略,然后在端口9999和9998上运行两个实例。我不知道如何配置application.yml文件的客户端和资源服务器。我在客户端服务器上尝试了以下配置:
-
Flink Statefun HA kubernetes集群
我正在尝试在kubernetes上部署高可用的flink集群。在下面的示例中,工作节点被复制,但我们只有一个主pod。 https://github.com/apache/flink-statefun 据我所知,有两种方法可以让job manager成为HA。 https://ci.apache.org/projects/flink/flink-docs-stable/ops/jobmanager
-
glassfish 4.1与JMS集群
我已经用目标服务器和集群创建了集群“MyCluster”、两个本地实例和资源jms/queue1、jms/queue2和jms/topic。 > create-cluster mycluster create-instance--node localhost-domain1--cluster mycluster instance01 create-instance--node localhost-