《集群化》专题
-
监控集群
集群运行起来后,你可以用 ceph 工具来监控,典型的监控包括检查 OSD 状态、监视器状态、归置组状态和元数据服务器状态。 交互模式 要在交互模式下运行 ceph ,不要带参数运行 ceph ,例如: ceph ceph> health ceph> status ceph> quorum_status ceph> mon_status 检查集群健康状况 启动集群后、读写数据前,先检查下集群的健
-
集群运维
高级运维 高级集群操作主要包括用 ceph 服务管理脚本启动、停止、重启集群,和集群健康状态检查、监控和操作集群。 操纵集群 监控集群 监控 OSD 和归置组 用户管理 数据归置 你的集群开始运行后,就可以尝试数据归置了。 Ceph 是 PB 级数据存储集群,它用 CRUSH 算法、靠存储池和归置组在集群内分布数据。 数据归置概览 存储池 纠删码 分级缓存 归置组 CRUSH 图 低级运维 低级集
-
 Oracle RAC 集群
Oracle RAC 集群本篇幅主要介绍 Oracle RAC 集群的相关概念和动手搭建属于自己的 Oracle RAC 集群
-
集群流控
目录 集群流控介绍 集群流控规则配置 集群流控示例 集群流控管理(控制台) Envoy RLS token server 介绍 为什么要使用集群流控呢?假设我们希望给某个用户限制调用某个 API 的总 QPS 为 50,但机器数可能很多(比如有 100 台)。这时候我们很自然地就想到,找一个 server 来专门来统计总的调用量,其它的实例都与这台 server 通信来判断是否可以调用。这就是最基
-
集群监控
集群监控的本质是一个聚合功能。 单台机器的监控指标难以反应整个集群的情况,我们需要把整个集群的机器(体现为某个HostGroup下的机器)综合起来看。比如所有机器的qps加和才是整个集群的qps,所有机器的request_fail数量 ÷ 所有机器的request_total数量=整个集群的请求失败率。 我们计算出集群的某个整体指标之后,也会有“查看该指标的历史趋势图” “为该指标配置报警” 这种
-
4.4.1.5-Redis-集群
为 Redis 自带的主从复制提供主从切换方案。 2. TwenProxy 3. Redis Cluster 4. Codies 参考资料 Redis 集群方案
-
Docker1.12 Worker无法加入集群(集群:待定)
问题内容: 管理员版本, 工人版本。 创建了Swarm管理器: 然后创建工人 我已经检查了工人的日志 在中,我看到了“虫群:待定” 我也做到了!尽管如此,该工作人员仍无法加入集群。所以,我该怎么爱 更新1 卸载并删除配置文件,然后再次安装docker 1.12版本。 仍然面临着相同的问题(无法加入和中的“ Swarm:Pending” ),其中存在DIFFERENT错误 谢谢。 问题答案: 问题是
-
HornetQ集群嵌入时使用JBoss集群吗?
我将使用嵌入在 JBoss EAP 6.2 中的 HornetQ 2.3.12,并且需要一些集群队列。 我是否需要设置 JBoss 集群才能让 JMS 集群由大黄蜂 Q 提供支持,或者大黄蜂 Q 是独立的?根据文档,我认为是后者,因为大黄蜂Q集群是大黄蜂Q的一部分,可以在没有JBoss的情况下存在。 节点通过核心网桥连接,因此部署在每个节点中的应用程序将对队列名称执行本地 JNDI 查找,而无需集
-
为已有 TiDB 集群部署异构集群
本文档介绍如何为已有的 TiDB 集群部署一个异构集群。 前置条件 已经存在一个 TiDB 集群,可以参考 在标准 Kubernetes 上部署 TiDB 集群进行部署。 部署异构集群 什么是异构集群 异构集群是给已经存在的 TiDB 集群创建差异化的实例节点,比如创建不同配置不同 Label 的 TiKV 集群用于热点调度或者创建不同配置的 TiDB 集群分别用于 TP 和 AP 查询。 创建一
-
集群部署 - 可扩展高可用集群
本文档提供一个可扩展、高可用的 Seafile 集群架构。这种架构主要是面向较大规模的集群环境,可以通过增加更多的服务器来提升服务性能。如果您只需要高可用特性,请参考3节点高可用集群文档。 架构" class="reference-link"> 架构 Seafile集群方案采用了3层架构: 负载均衡层:将接入的流量分配到 seafile 服务器上。并且可以通过部署多个负载均衡器来实现高可用。 Se
-
集群部署 - 3节点高可用集群
本文档介绍用 3 台服务器构建 Seafile 高可用集群的架构。这里介绍的架构仅能实现“服务高可用”,而不能支持通过扩展更多的节点来提升服务性能。如果您需要“可扩展 + 高可用”的方案,请参考Seafile 可扩展集群文档。 在这种高可用架构中包含3个主要的系统部件: Seafile 服务器:提供 Seafile 服务的软件 MariaDB 数据库集群:保存小部分的 Seafile 元数据,比如
-
ignite集群与kubernetes集成
我是新点燃的。 步骤1:我在两个VM(ubuntu)中安装了Ignite 2.6.0,在一个VM中启动了节点。下面有COMAND。bin/ignite.sh examples/config/example-ignite.xml 步骤2:我的所有配置都在example-default.xml中 步骤3:在其他VM中执行包含datagrid逻辑的client.jar(该VM既是客户机也是节点)。 步骤
-
从集群收集度量
有人能建议从节点集群收集指标的最佳模式吗(每个节点都是带有Java应用程序的Tomcat Docker容器)? 我们计划使用ELK堆栈(ElasticSearch、Logstash、Kibana)作为可视化工具,但我们的问题是如何将指标交付给Kibana? 我们使用DropWizard度量库,它提供每个实例的度量(量表、计时器、直方图)。 显然,应该收集每个实例的一些指标(例如,cpu、内存等..
-
Kubernetes集群上运行的Spark独立集群的Hadoop集群Kerberos身份验证
我已经在Kubernetes上建立了Spark独立集群,并试图连接到Kubernetes上没有的Kerberized Hadoop集群。我已经将core-site.xml和hdfs-site.xml放在Spark集群的容器中,并相应地设置了HADOOP_CONF_DIR。我能够成功地在Spark容器中为访问Hadoop集群的principal生成kerberos凭据缓存。但是当我运行spark-s
-
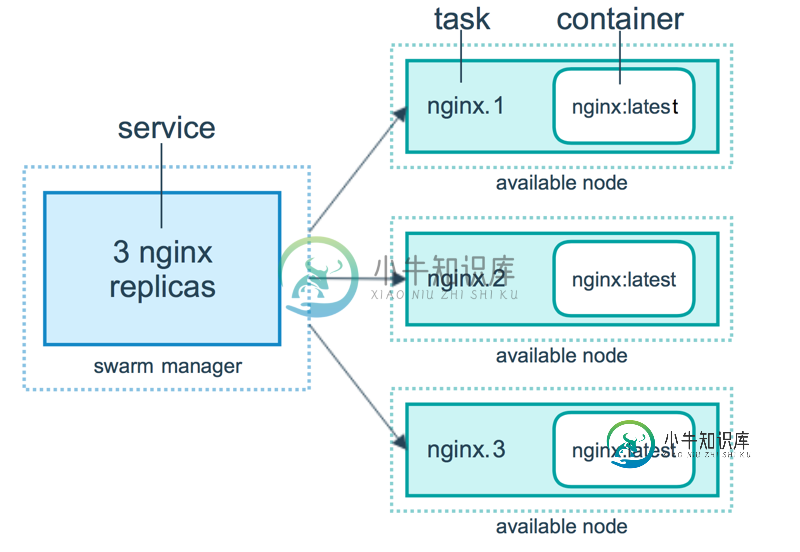 Swarm 集群管理
Swarm 集群管理主要内容:使用简介 Docker Swarm 是 Docker 的集群管理工具。它将 Docker 主机池转变为单个虚拟 Docker 主机。 Docker Swarm 提供了标准的 Docker API,所有任何已经与 Docker 守护程序通信的工具都可以使用 Swarm 轻松地扩展到多个主机。 支持的工具包括但不限于以下各项: Dokku Docker Compose Docker Machine Jen