《集群化》专题
-
8.1.3 三阶:跨主机集群容器模式
跨主机集群容器模式 在同一台主机上运行多个zookeeper容器可以实现集群方式,并且可以很方便的文件共享(数据卷)。 但是遇到跨主机访问就不会那么方便,容器的跨主机网络的访问官方没有提供现成的方案。 不过官方提供的高级网络配置中,可以利用其配置原理,自己搭建一个网桥,实现容器的互相访问,pipework就是这样实现了跨主机访问,有兴趣的话可以关注一下,这不是本文的重点。 本文将结合之前试验过的O
-
8.1.2 二阶:单主机集群容器模式
单主机集群容器模式 单节点(主机)的zookeeper容器搭建,原理也是比较简单的,我们利用之前创建的zookeeper镜像分别创建三个容器: Zk1 sudo docker run -d -p 21811:2181 --name=container1 \ -v /home/zk/container1:/var/zookeeper/data \ -v /home/zk/zoo.cfg:/var
-
在生产 cluster(集群)上运行 topologies(拓扑)
在生产集群上运行 Topology 类似于在 本地模式 下运行.以下是步骤: 1)定义 Topology (如果使用 Java 定义, 则使用 TopologyBuilder ) 2)使用 StormSubmitter 将 topology 提交到集群. StormSubmitter 以 topology 的名称, topology 的配置和 topology 本身作为输入.例如: Config
-
使用kubeconfig文件配置跨集群认证
Kubernetes 的认证方式对于不同的人来说可能有所不同。 运行 kubelet 可能有一种认证方式(即证书)。 用户可能有不同的认证方式(即令牌)。 管理员可能具有他们为个人用户提供的证书列表。 我们可能有多个集群,并希望在同一个地方将其全部定义——这样用户就能使用自己的证书并重用相同的全局配置。 所以为了能够让用户轻松地在多个集群之间切换,对于多个用户的情况下,我们将其定义在了一个 kub
-
Kubernetes集群安全性配置最佳实践
本文是对Kubernetes集群安全性管理的最佳实践。 端口 请注意管理好以下端口。 端口 进程 描述 4149/TCP kubelet 用于查询容器监控指标的cAdvisor端口 10250/TCP kubelet 访问节点的API端口 10255/TCP kubelet 未认证的只读端口,允许访问节点状态 10256/TCP kube-proxy kube-proxy的健康检查服务端口 909
-
Mesos - 优秀的集群资源调度平台
Mesos 项目是源自 UC Berkeley 的对集群资源进行抽象和管理的开源项目,类似于操作系统内核,用户可以使用它很容易地实现分布式应用的自动化调度。 同时,Mesos 自身也很好地结合和主持了 Docker 等相关容器技术,基于 Mesos 已有的大量应用框架,可以实现用户应用的快速上线。 本章将介绍 Mesos 项目的安装、使用、配置以及核心的原理知识。
-
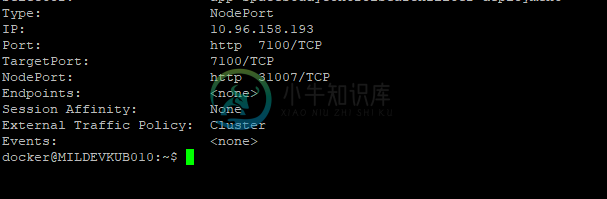 无法使用节点端口方法在群集中外部访问从群集中部署的kubernetes服务
无法使用节点端口方法在群集中外部访问从群集中部署的kubernetes服务我正在尝试访问库伯内特斯集群部署的Spring Boot微服务并尝试测试REST API。我在部署脚本中配置了节点端口方法。但是当我尝试使用Postman工具访问时,我只得到“无法获得任何响应”的响应。 我配置了服务。yaml脚本类似于以下结构, 我的部署。yaml如下所示:, 当我使用时,输出如下所示, 我正在尝试通过以下方式访问我部署的API, 更新 当我为我的部署运行命令时,我得到如下响应:
-
强制驱动程序在spark独立集群中的特定从机上运行,该集群运行“--deploy-mode cluster”
我正在运行一个小型spark集群,其中有两个EC2实例(M4.xLarge)。 --驱动程序-内存8G --驱动器-核心2 --部署模式客户端
-
集群环境中javax.ejb.Singleton的单例程度如何?
问题内容: 我需要为集群环境中的所有用户和所有节点维护一个在应用程序内唯一的简单计数器。我考虑过像这样使用单例会话bean注释javax.ejb.Singleton: 这看起来很简单,但是如果它在集群环境中可以正常工作,我将找不到答案。集群的每个节点是否都具有自己的实例? 当然,我可以将bean保留在数据库中,但实际上这只是一个计数器,这样做会过分杀伤力。另外,我希望计数器在应用程序崩溃或重新启动
-
将float数组划分为相似的段(集群)
问题内容: 我有这样一个浮点数组: 现在,我想像这样对数组进行分区: // [200]由于集群支持较少,将被视为异常值 我必须为多个数组找到这种段,但我不知道分区大小应该是多少。我试图通过使用层次聚类(聚集)来做到这一点 ,它为我提供了令人满意的结果。但是,问题是,建议我不要对一维问题使用聚类算法,因为这样做没有任何理论上的依据(因为它们是针对多维数据的)。 我发现了另一个建议,而不是聚类,即自然
-
Akka:如何找到集群中的当前节点?
问题内容: 在Akka actor中,如何找到群集的节点?即,本地节点认为当前可访问的节点。 谢谢-丹尼尔 问题答案: 您实际上不需要订阅或。您可以只访问集群扩展的成员,例如,
-
Hadoop平台集群配置、环境变量设置?
本文向大家介绍Hadoop平台集群配置、环境变量设置?相关面试题,主要包含被问及Hadoop平台集群配置、环境变量设置?时的应答技巧和注意事项,需要的朋友参考一下 zookeeper:修改zoo.cfg文件,配置dataDir,和各个zk节点的server地址端口,tickTime心跳时间默认是2000ms,其他超时的时间都是以这个为基础的整数倍,之后再dataDir对应目录下写入myid文件和z
-
使用多处理模块进行集群计算
问题内容: 我对使用计算机集群运行Python程序感兴趣。过去我一直在使用Python MPI接口,但是由于在编译/安装这些接口时遇到困难,我更喜欢使用内置模块(例如Python的多处理模块)的解决方案。 我真正想做的就是设置一个跨整个计算机集群的实例,并运行一个。这是可能/容易做到的事情吗? 如果这不可能,那么我至少希望能够从中央脚本在每个节点上为每个节点使用不同参数来启动实例。 问题答案: 如
-
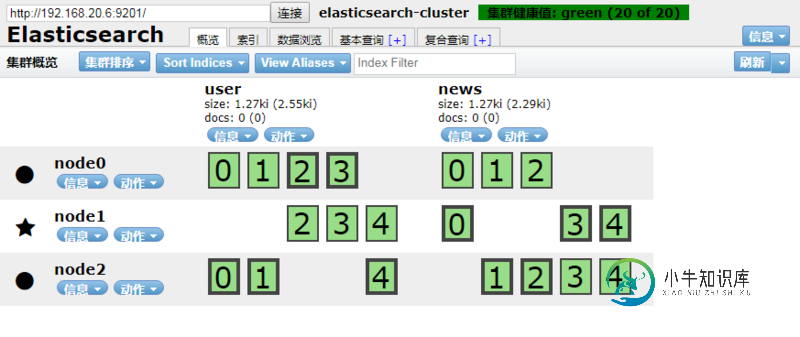 使用docker快速部署Elasticsearch集群的方法
使用docker快速部署Elasticsearch集群的方法本文向大家介绍使用docker快速部署Elasticsearch集群的方法,包括了使用docker快速部署Elasticsearch集群的方法的使用技巧和注意事项,需要的朋友参考一下 本文将使用Docker容器(使用docker-compose编排)快速部署Elasticsearch 集群,可用于开发环境(单机多实例)或生产环境部署。 注意,6.x版本已经不能通过 -Epath.config 参数
-
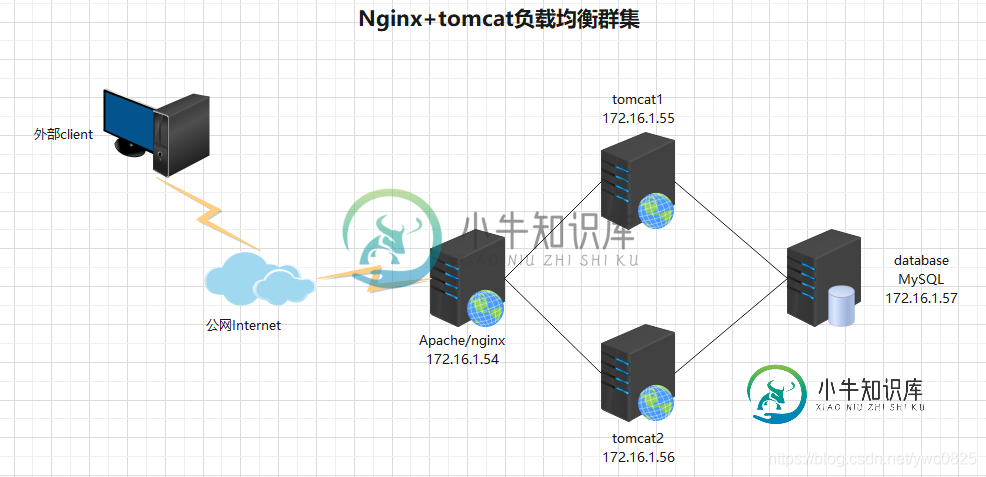 Nginx+tomcat负载均衡集群的实现方法
Nginx+tomcat负载均衡集群的实现方法本文向大家介绍Nginx+tomcat负载均衡集群的实现方法,包括了Nginx+tomcat负载均衡集群的实现方法的使用技巧和注意事项,需要的朋友参考一下 实验环境如下 这里需要准备4台服务器(1台nginx、2台tomcat做负载、一台MySQL做数据存储) 准备软件包如下: 软件包地址连接: 链接: https://pan.baidu.com/s/1Zitt5gO5bDocV_8TgilvRw