《集群化》专题
-
从spark集群向cassandra集群写入dataframe:分区和性能调优
我有两个集群-1。Cloudera Hadoop-Spark作业在这里运行2。云-卡桑德拉星团,多DC 在编写从spark作业到cassandra集群的dataframe时,我在编写之前在spark中进行了重新分区(repartioncount=10)。见下文: 在我的多租户spark集群中,对于一个有20M记录的spark批加载,以及以下配置,我看到了很多任务失败、资源抢占和动态失败。 PS:我
-
KeyCloak与mysql-InnoDB集群的独立集成
正在尝试让Keyclope与mysql innodb群集配合使用。我已经单独配置了Keyclope。xml符合文档要求。 这是数据源 这是司机 我还添加了module.xml打包mysql jdbc驱动程序(我使用最新版本mysql-connector-java-8.0.21.jar) 运行keydrope时出现的错误是 这方面的任何帮助都会非常有用。
-
从外部运行的现有HazelCast群集启动Vert.x群集管理器
我的笔记本电脑上安装了docker desktop。使用docker,我使用TCP-IP创建了一个带有两个节点的Hazelcast集群,为此我使用了Hazelcast/Hazelcast:4.0.2映像。 我已经检查了两个成员的docker服务日志,这表明两个成员都成功创建并加入,没有任何错误。此外,使用IntelliJ IDE在我的笔记本电脑中创建了一个Hazelcast客户端JAVA程序,通过
-
性能优化 - 集群状态维护
我们都知道,ES 中的 master 跟一般 MySQL、Hadoop 的 master 是不一样的。它即不是写入流量的唯一入口,也不是所有数据的元信息的存放地点。所以,一般来说,ES 的 master 节点负载很轻,集群性能是可以近似认为随着 data 节点的扩展线性提升的。 但是,上面这句话并不是完全正确的。 ES 中有一件事情是只有 master 节点能管理的,这就是集群状态(cluster
-
Kubernetes 上的集群初始化配置
本文介绍如何对 Kubernetes 上的集群进行初始化配置完成初始化账号和密码设置,以及批量自动执行 SQL 语句对数据库进行初始化。 注意: 如果 TiDB 集群创建完以后手动修改过 root 用户的密码,初始化会失败。 以下功能只在 TiDB 集群创建后第一次执行起作用,执行完以后再修改不会生效。 配置 TidbInitializer 请参考 TidbInitializer 示例和 API
-
使用Wildfly的集群式Singleton?
问题内容: 我正在尝试在Wildfly 8.2上创建一个简单的集群。我已经配置了2个Wildfly实例,它们以独立的群集配置运行。我的应用程序已部署到这两个应用程序,并且我可以毫无问题地访问它。 我的集群EJB如下所示: …并且我编写了一个非常简单的RESTful服务,让我可以通过浏览器调用这些方法… 我可以从单个Wildfly实例中调用和方法,并获得预期值。但是,如果我尝试从一个实例调用poke
-
 Redis集群的相关详解
Redis集群的相关详解本文向大家介绍Redis集群的相关详解,包括了Redis集群的相关详解的使用技巧和注意事项,需要的朋友参考一下 注意!要求使用的都是redis3.0以上的版本,因为3.0以上增加了redis集群的功能。 1.redis介绍 1.1什么是redis Redis是用C语言开发的一个开源的高性能键值对(key-value)的非关系型数据库。通过多种键值数据类型来适应不同场景下的存储需求,目前支持的键值数
-
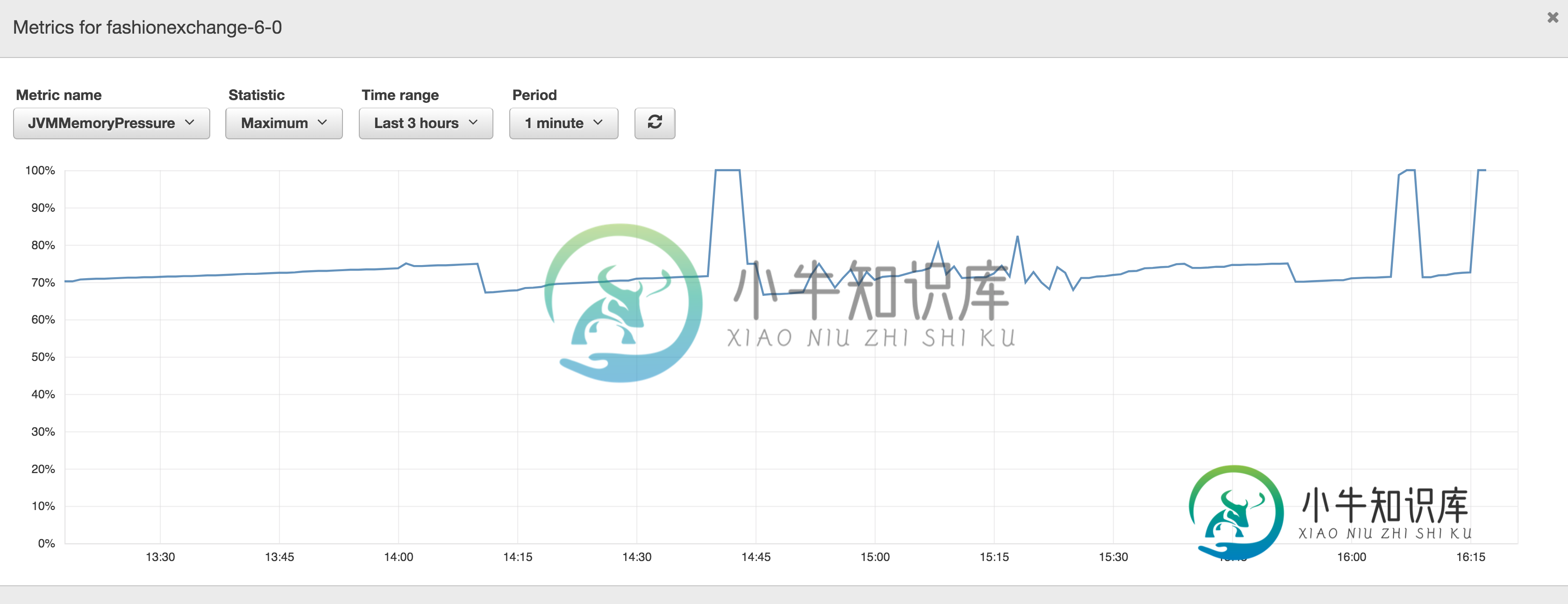 AWS ElasticSearch群集的堆大小
AWS ElasticSearch群集的堆大小我有一个AWS ElasticSearch T2.Medium实例,有两个节点在运行,几乎没有任何负载。但它一直在崩溃。 我看到了度量JVMMemoryPressure的以下图表: 当我去吉巴纳的时候,我看到下面的错误信息: 问题: 计算机只有64 MB可用内存,而不是应该与此实例类型关联的4 GB可用内存,我的解释正确吗?是否有其他地方来验证堆内存的绝对量,而不是只在Kibana出错时才在其上验
-
glassfish集群web应用部署
我创建了两个java web应用程序,一个使用mysql,另一个使用oracle。我在glassfish4.0服务器中部署了这些应用程序,并且工作正常。然后,我在服务器中创建集群,其中1个实例位于本地节点,1个实例来自远程节点。该集群和实例成功运行 然后我将应用程序部署到集群,当我在浏览器中运行web时, 应用程序使用mysql显示错误“类名错误或未为com.mysql.jdbc.jdbc2.op
-
redis集群支持事务吗?
我是redis的新手,我刚刚使用redis几个月了。目前我使用的是2.8.x稳定版本,但我试图使用3.0.0来导入redis集群功能。我使用java jedis作为客户机,这是我的问题:我发现jedis client的最新版本支持redis cluster lua脚本(jediscluster.evalsha),但我在哪里都找不到管道和事务相关的函数,所以我想知道是jedis还没有实现它(管道、事
-
Cassandra-覆盖群集键和行
我有一个关于设计的挑战,我有选择在我的卡桑德拉桌子上。这是在生产上运行的。但最近我观察到以下问题。 (这里的表名和列是为了便于讨论) 我的问题是,有人能在不改变Datamodel设计的情况下提出解决方案吗?
-
集群环境中的Spring Scheduler
我使用Spring调度程序,使用@调度注释来调度运行文件生成服务的作业。应用程序部署在集群环境中Tomcat的5个单独节点上,用于负载平衡和故障转移。正因为如此,服务被调度了5次,这是不可能的。有没有办法将调度程序配置为仅在当前节点上运行? 有一种方法使用数据库找出当前活动节点,并在这里调用该特定实例的调度器 另一种方法是使用石英调度器 由于我无法对部署的应用程序进行重大更改,是否有简单的解决方案
-
集群环境中的单例
问题内容: 将Singleton对象重构到集群环境的最佳策略是什么? 我们使用Singleton从数据库中缓存一些自定义信息。它 主要是 只读的,但是在发生某些特定事件时会刷新。 现在,我们的应用程序需要部署在集群环境中。根据定义,每个JVM将具有自己的Singleton实例。因此,当在单个节点上发生刷新事件并且刷新其缓存时,JVM之间的缓存可能不同步。 保持缓存同步的最佳方法是什么? 谢谢。 编
-
集群资源管理器 —— YARN
一、hadoop yarn 简介 Apache YARN (Yet Another Resource Negotiator) 是 hadoop 2.0 引入的集群资源管理系统。用户可以将各种服务框架部署在 YARN 上,由 YARN 进行统一地管理和资源分配。 二、YARN架构 1. ResourceManager ResourceManager 通常在独立的机器上以后台进程的形式运行,它是整个集
-
操作etcd集群 - 加密(TODO)
注: 内容翻译自 Security Model TBD……