
AWS ElasticSearch群集的堆大小

我有一个AWS ElasticSearch T2.Medium实例,有两个节点在运行,几乎没有任何负载。但它一直在崩溃。
我看到了度量JVMMemoryPressure的以下图表:
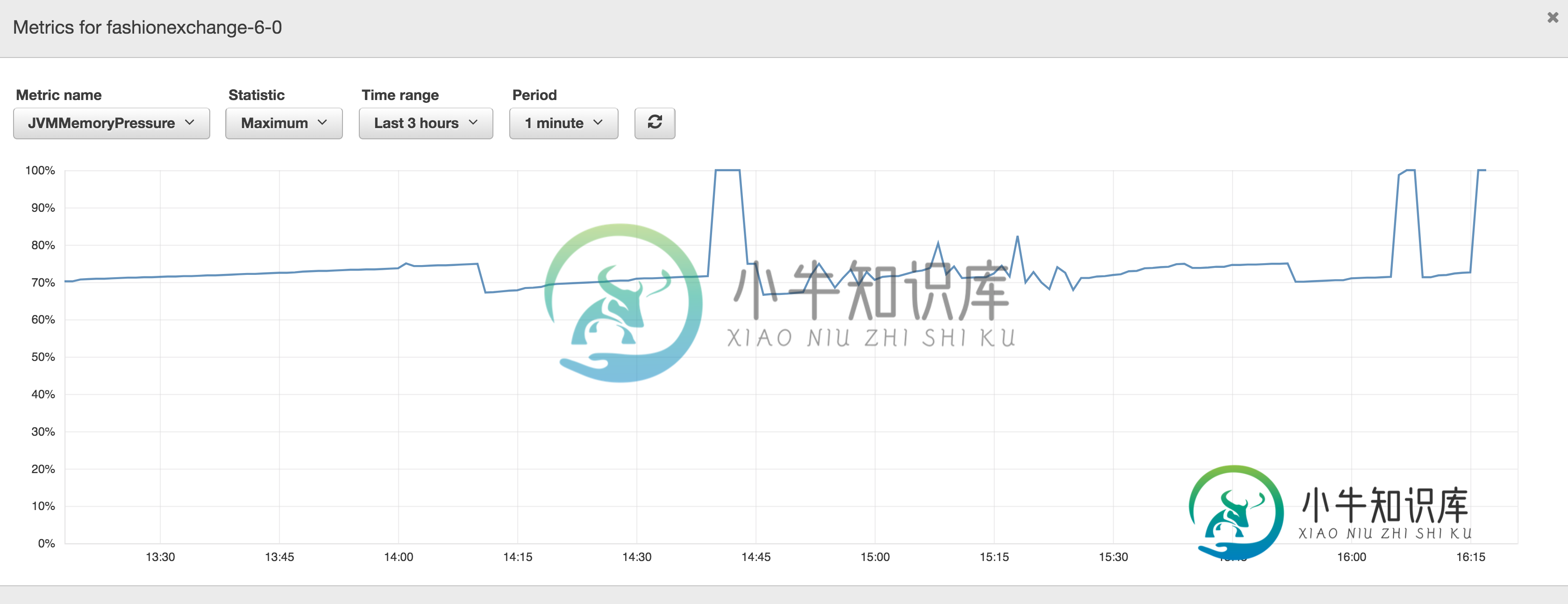
当我去吉巴纳的时候,我看到下面的错误信息:
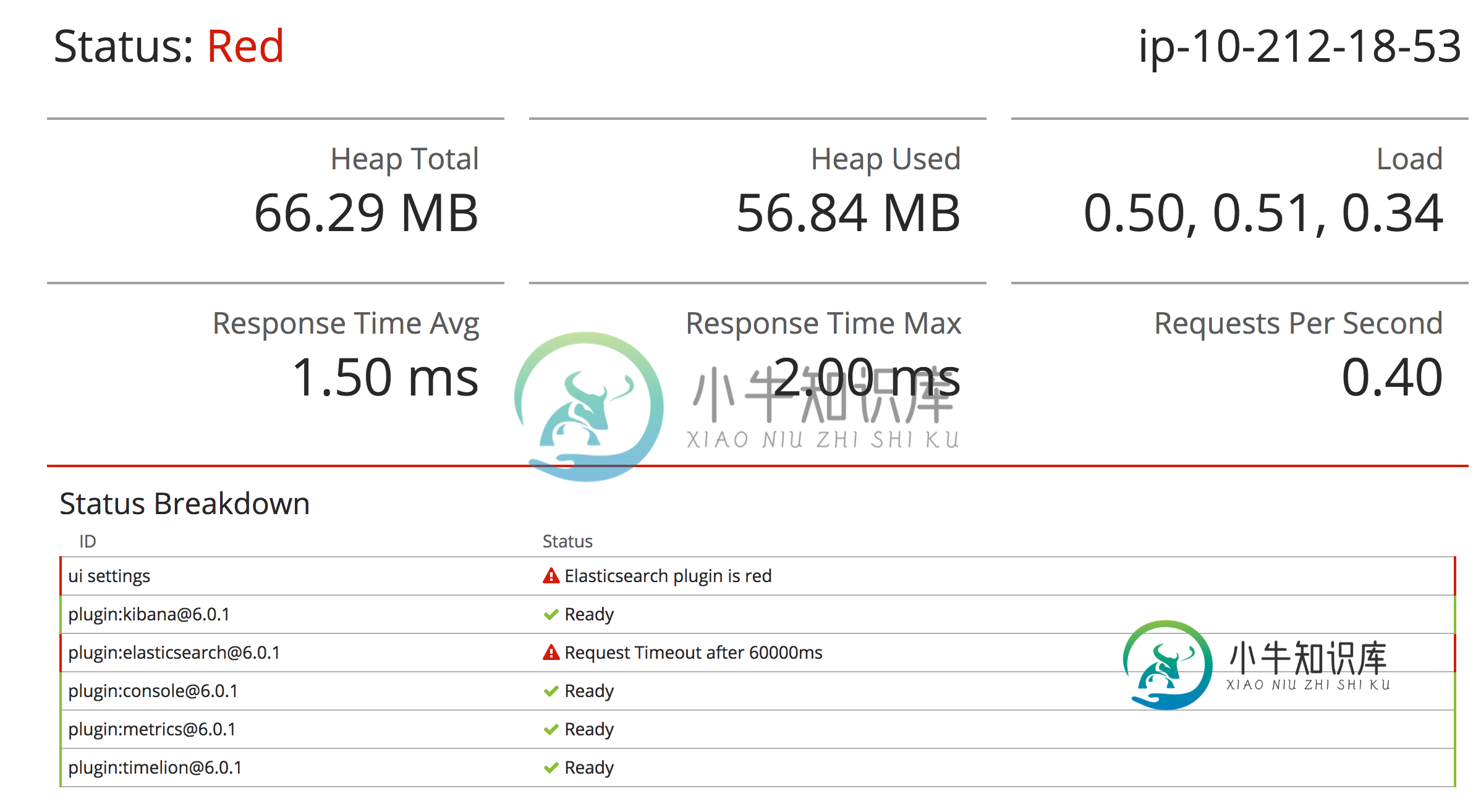
问题:
- 计算机只有64 MB可用内存,而不是应该与此实例类型关联的4 GB可用内存,我的解释正确吗?是否有其他地方来验证堆内存的绝对量,而不是只在Kibana出错时才在其上验证?
- 如果是,如何改变此行为?
- 如果这是正常的,那么每当内存占用达到100%时,我可以在哪里寻找导致ElasticSearch崩溃的可能原因。实例上的负载很少。
在实例的日志记录中,我看到了很多警告,例如下面的警告。它们没有提供从何处开始调试问题的任何线索。
[2018-08-15T07:36:37,021][WARN ][r.suppressed ] path: __PATH__ params:
{}
org.elasticsearch.cluster.block.ClusterBlockException: blocked by: [__PATH__ master];
at org.elasticsearch.cluster.block.ClusterBlocks.globalBlockedException(ClusterBlocks.java:165) ~[elasticsearch-6.0.1.jar:6.0.1]
at org.elasticsearch.action.bulk.TransportBulkAction$BulkOperation.handleBlockExceptions(TransportBulkAction.java:387) [elasticsearch-6.0.1.jar:6.0.1]
at org.elasticsearch.action.bulk.TransportBulkAction$BulkOperation.doRun(TransportBulkAction.java:273) [elasticsearch-6.0.1.jar:6.0.1]
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37) [elasticsearch-6.0.1.jar:6.0.1]
at org.elasticsearch.action.bulk.TransportBulkAction$BulkOperation$2.onTimeout(TransportBulkAction.java:421) [elasticsearch-6.0.1.jar:6.0.1]
at org.elasticsearch.cluster.ClusterStateObserver$ContextPreservingListener.onTimeout(ClusterStateObserver.java:317) [elasticsearch-6.0.1.jar:6.0.1]
at org.elasticsearch.cluster.ClusterStateObserver$ObserverClusterStateListener.onTimeout(ClusterStateObserver.java:244) [elasticsearch-6.0.1.jar:6.0.1]
at org.elasticsearch.cluster.service.ClusterApplierService$NotifyTimeout.run(ClusterApplierService.java:578) [elasticsearch-6.0.1.jar:6.0.1]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:569) [elasticsearch-6.0.1.jar:6.0.1]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_172]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_172]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_172]
或
[2018-08-15T07:36:37,691][WARN ][o.e.d.z.ZenDiscovery ] [U1DMgyE] not enough master nodes discovered during pinging (found [[Candidate{node={U1DMgyE}{U1DMgyE1Rn2gId2aRgRDtw}{F-tqTFGDRZaovQF8ILC44w}{__IP__}{__IP__}{__AMAZON_INTERNAL__, __AMAZON_INTERNAL__}, clusterStateVersion=207939}]], but needed [2]), pinging again
或
[2018-08-15T07:36:42,303][WARN ][o.e.t.n.Netty4Transport ] [U1DMgyE] write and flush on the network layer failed (channel: [id: 0x385d3b63, __PATH__ ! __PATH__])
java.io.IOException: Connection reset by peer
at sun.nio.ch.FileDispatcherImpl.writev0(Native Method) ~[?:1.8.0_172]
at sun.nio.ch.SocketDispatcher.writev(SocketDispatcher.java:51) ~[?:1.8.0_172]
at sun.nio.ch.IOUtil.write(IOUtil.java:148) ~[?:1.8.0_172]
at sun.nio.ch.SocketChannelImpl.write(SocketChannelImpl.java:504) ~[?:1.8.0_172]
at io.netty.channel.socket.nio.NioSocketChannel.doWrite(NioSocketChannel.java:432) ~[netty-transport-4.1.13.Final.jar:4.1.13.Final]
at io.netty.channel.AbstractChannel$AbstractUnsafe.flush0(AbstractChannel.java:856) [netty-transport-4.1.13.Final.jar:4.1.13.Final]
at io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.forceFlush(AbstractNioChannel.java:368) [netty-transport-4.1.13.Final.jar:4.1.13.Final]
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:638) [netty-transport-4.1.13.Final.jar:4.1.13.Final]
at io.netty.channel.nio.NioEventLoop.processSelectedKeysPlain(NioEventLoop.java:544) [netty-transport-4.1.13.Final.jar:4.1.13.Final]
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:498) [netty-transport-4.1.13.Final.jar:4.1.13.Final]
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:458) [netty-transport-4.1.13.Final.jar:4.1.13.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:858) [netty-common-4.1.13.Final.jar:4.1.13.Final]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_172]
共有1个答案

我知道那个数字是不正确的。我不知道它是从哪里来的。要获得正确的内存使用情况,可以运行以下查询:
获取“
-
我们正在将web应用程序从内存缓存中的临时解决方案迁移到apache ignite集群,其中运行webapp的jboss作为客户端节点工作,两个外部vm作为ignite服务器节点工作。 当用一个客户机节点和一个服务器节点测试性能时,一切正常。但在集群中使用一个客户端节点和两个服务器节点进行测试时,服务器节点会出现OutOfMemoryError崩溃。
-
我是Java的初学者,刚开始使用Intellij作为我的IDE。 当我使用它时,有时会延迟。 我更改了我的 xms 和 xmx 以获得更大的堆大小(xms = 1024,xmx = 2048),但它抛出了一个错误。 所以,我把它回滚了。 错误消息是这样的:“初始堆大小设置为大于最大堆大小的值”。 有什么问题? 如果可能,如何增加最大堆大小? 我用的是笔记本电脑,它有8GB内存。x64Intelli
-
问题内容: 我对SQL(Server2008)的较低层次的了解是有限的,现在我们的DBA对此提出了挑战。让我解释一下这种情况:(我已经提到一些明显的陈述,希望我是对的,但是如果您发现有问题,请告诉我)。 我们有一张桌子,上面放着人们的“法院命令”。创建表(名称:CourtOrder)时,我的创建方式如下: 然后,我将非聚集索引应用于主键(以提高效率)。我的理由是,这是一个唯一字段(主键),应该像我
-
Cluster Cluster.EdsClusterConfig Cluster.OutlierDetection Cluster.LbSubsetConfig Cluster.LbSubsetConfig.LbSubsetSelector Cluster.LbSubsetConfig.LbSubsetFallbackPolicy (Enum) Cluster.RingHashLbConfig C
-
根据这份文件: 然而,与Redis(群集模式禁用)群集不同,当前,一旦创建了Redis(群集模式启用)群集,其结构就不能以任何方式改变;不能添加或删除节点或碎片。如果需要添加或删除节点,或更改节点类型,则必须重新创建集群。(来源) 然而,本文档似乎描述了向集群添加碎片的过程: 通过使用Amazon ElastiCache for Redis 3.2.10版本的在线重新划分和分片重新平衡,您可以动态
-
一、负载均衡 负载均衡算法 转发实现 二、集群下的 Session 管理 Sticky Session Session Replication Session Server 一、负载均衡 集群中的应用服务器(节点)通常被设计成无状态,用户可以请求任何一个节点。 负载均衡器会根据集群中每个节点的负载情况,将用户请求转发到合适的节点上。 负载均衡器可以用来实现高可用以及伸缩性: 高可用:当某个节点故障