《链路追踪》专题
-
在windows中追加/删除虚拟打印机实例教程
本文向大家介绍在windows中追加/删除虚拟打印机实例教程,包括了在windows中追加/删除虚拟打印机实例教程的使用技巧和注意事项,需要的朋友参考一下 由于项目需要在windwos系统中添加多台虚拟打印机(能够正常打印出纸),查找了一下系统函数。 使用 rundll32 printui.dll,PrintUIEntry,在CMD中运行,在弹出框中得到以下提示。 用法: rundll32
-
Alamofire 4.0/Swift 3.0-追加多部分表单数据(CSV文件)
我以前在Swift 2.2中有一个.post多种形式的上传,它遵循以下格式(请注意,我没有包括所有AlamoFire代码…那太长了。我只是包括相关部分): 这很有效。然而,在迁移到Swift 3.0和Alamofire 4.0之后,我现在使用以下格式: 我最终得到以下错误:无法使用类型为“(NSData,withName:String,fileName:String,mimeType:String
-
自定义文章类型-追加文章段到当前URL
我已经注册了一个自定义帖子类型。 我还有一个页面模板,列出了所有的项目,标题为“我的作品”。使用模板的页面的URL为: http://sitename/my-works 但是,当我创建一个公文包帖子时,我会得到如下URL: http://sitename/portfolio/post-name 单击页面模板中的某个项目时,是否可以将其重定向到: http://sitename/my-works/p
-
从列表中提取列表,然后追加到数据框
我试图从包含列表的json中提取一个字段,然后将该列表附加到数据帧中,但遇到了一些不同的错误。 我想我可以将其写入csv,然后用Pandas读取csv,但我尽量避免写入任何文件。我知道我也可以使用StringIO生成csv,但这存在空字节问题。替换这些将是(我认为)另一个逐行的步骤,这将进一步延长脚本完成所需的时间。。。我正在对一个返回成千上万个结果的查询运行此操作,因此保持它的快速和简单是一个优
-
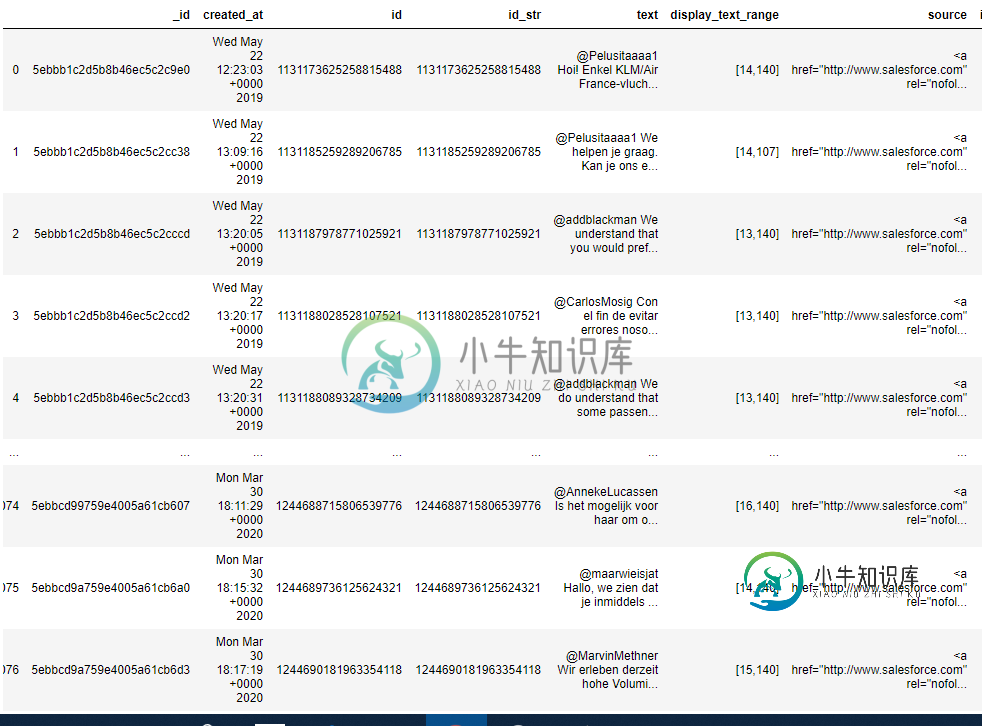 将数据帧中的值列表追加到新列[重复]
将数据帧中的值列表追加到新列[重复]我试图做的是从列“in_reply_to_user_id”(不在图片中,因为df太宽,无法容纳)与给定id具有相同值的行中获取文本,并将文本附加到列表中,然后将其放入新列中。例如,所有tweet中的“in_reply_to_user_id”列等于第一条tweet的“id”的文本都应该放在一个列表中,然后添加到数据框中名为“reples”的新列中。以下是我尝试过的一些事情:
-
Python 3:使用while True循环在列表上追加整数
我正在尝试做以下练习: 任务四 创建一个空列表购买金额用用户输入的项目价格填充列表继续添加到列表中,直到输入“完成” 可以在正确时使用:带中断 打印购买金额 以下是我目前掌握的代码: 但它给了我一个非常奇怪的输出,如下所示: 输入价格:2222222 输入价格:1 输入价格: 2 输入价格:3 输入价格:完成 输入价格:完成 ['2222222','2','完成'] 有人知道为什么它会覆盖第二、第
-
使用Scala Spark在同一个csv文件中追加新表
我想在现有的CSV文件中追加表。我使用下面的代码: 每次下面的代码块运行时,都会在data/outputs.CSV(其中outputs.CSV是文件夹而不是CSV文件)中创建一个新文件。
-
将新数据追加到已分区的拼花文件中
我正在编写一个ETL进程,在该进程中,我需要每小时读取日志文件,对数据进行分区,并保存它。我正在使用Spark(在数据库中)。日志文件是CSV,所以我读取它们并应用模式,然后执行转换。 我的问题是,如何将每个小时的数据保存为拼花板格式,但添加到现有的数据集?保存时,我需要按DataFrame中存在的4列进行分区。 下面是我的保存行: 我使用parquet是因为分区大大增加了以后的查询。此外,我必须
-
将数组的数组追加到FormData并通过AJAX发送
是这种格式,在后端,我只在请求中获得格式。我还需要发送“original_file_name”和“function_name”属性。当然,我可以将数组分成3个部分并分别追加它们,但是有没有办法将每个mediasData数组索引的所有there属性发送到formdata数组各自的索引中?
-
将新对象追加到数组列表的开头[重复]
问题是:“要求用户输入其国家的详细信息,使用输入的值创建一个国家的新对象,并将其附加到数组列表的开头。” 我确实遵循了最基本的规则来防止任何错误,但是当我试图编译时。它复制了一些像日本和美国这样的物体。尝试许多不同的方法来调试和理解问题,但我找不到。
-
使用scala将转换后的列追加到spark数据帧
我正在尝试访问配置单元表,并从表/数据帧中提取和转换某些列,然后将这些新列放入新的数据帧中。我试着用这种方式- 它使用SBT构建时没有任何错误。但当我尝试运行它时,我收到以下错误- 我想了解是什么导致了这个错误,如果有任何其他的方法来完成我正在尝试做的事情。
-
log4j可加性、类别日志级别和追加器阈值
我很难理解可加性、类别日志级别和追加器阈值之间的关系。 下面的场景(我的log4j.properties文件): null
-
在Selenium中滚动webelement后意外追加到列表的值
我对python(以及一般编程)是新手,我想从使用Selenium滚动后动态更新的webelement中刮取数据,类似于本文:尝试使用python和Selenium迭代地滚动和刮取网页。与问题中的截图类似,我的webelement是一个带有标题的数据表,其中可能有水平或垂直滚动条。 我要做的第一件事是在我的webelement上滚动(一次滚动一列,这样就不会跳过任何列),并刮遍所有的标题。到目前为
-
多线程追加器队列中的慢队列裁剪器
我有一个场景,其中多个线程正在写入同一队列。 Appender线程从不同的市场(每个线程都是单一市场)接收更新,并将这些数据推入相同的队列:
-
BigQuery在架构中插入(而不是追加)一个新列
是否有一种方便的方法(Python、Web UI或CLI)可以将新列插入现有BigQuery表(已经有100列左右)并相应地更新架构? 假设我想在第 49 列之后插入它。如果我通过查询执行此操作,我将不得不键入每个列名称,不是吗? 更新:建议的答案没有清楚地说明这如何适用于BigQuery。此外,文件似乎不包括 语法。测试确认 标识符不适用于 BigQuery。