《负载均衡》专题
-
CDF x值为50%,平均值不显示相同的数字
我有一个数据框,我创建了列的CDF: 在50%标记处,CDF覆盖图中的数据点显示平均值为120,但是显示平均值为154。 为什么会有差异? :
-
NetworkX平均最短路径长度和直径需要永远
我有一个由未加权边构建的图(a),我想计算主图(a)中最大连通图(giantC)的平均最短路径长度。但是,到目前为止,该脚本已经运行了3个多小时(在Colab和本地进行了尝试),对于和都没有输出任何结果。 我使用的是, 这是我的剧本 有没有办法让它更快?或者是计算giantC图的直径和最短路径长度的替代方法?
-
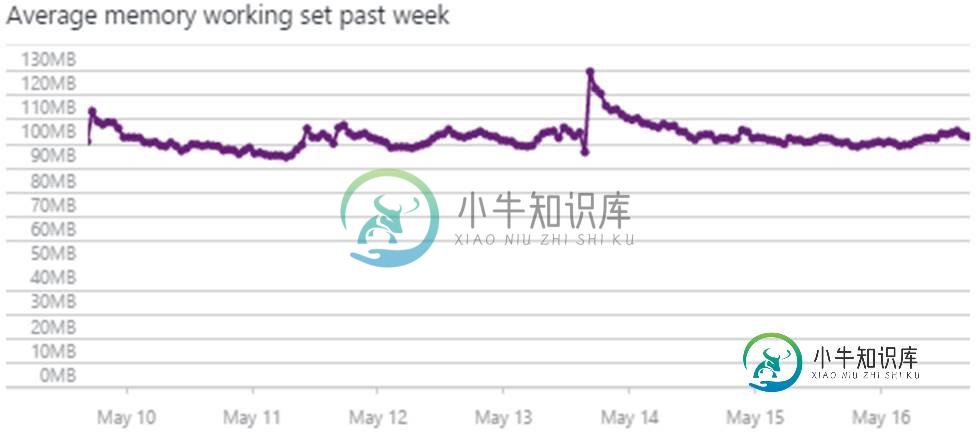 Azure中的平均内存工作集和内存工作集
Azure中的平均内存工作集和内存工作集我在Azure中有一个应用程序服务。它显示了两个称为“平均内存工作集”(Average Memory Working Set)和“内存工作集”(Memory Working Set)的度量。现在,内存工作集被定义为进程中线程最近接触到的内存页集。门户中显示的这两个图形如下所示: 现在,我有三个问题: > 如何找出我的服务的专用最大内存是多少?一旦达到限制会发生什么? 内存工作集是进程中的线程最近接
-
根据长度将数据帧分为相对均匀的块
问题内容: 我必须创建一个函数,将提供的数据帧分成所需大小的块。例如,如果数据帧包含1111行,我希望能够指定400行的块大小,并获得三个较小的数据帧,分别具有400、400和311的大小。是否有方便的功能来完成这项工作?在切片的数据帧上存储和迭代的最佳方法是什么? 示例数据框 问题答案: 您可以将序列的底数划分为数据帧中的行数,然后将其用于将数据帧拆分为大小相等的块:
-
TSQL将结果集平均划分为组并进行更新
问题内容: 订单表具有如下数据: 运算符表: 组表: 如您所见,约翰有3个订单,凯特(Kate),威尔(Will),杰克(Jack)和山姆(Sam)没有。 现在,我想根据某些条件将操作员分配给订单: 订单现金必须大于0 订单必须具有状态= 1 订单必须在组1或2中 操作员必须处于活动状态(active = 1) 操作员必须在组1或2中 这是我想要得到的结果: 我想重新整理订单并更新operator
-
为什么向0.0应用指数移动平均线较慢?
这是我的代码: 将指数移动平均值从0.1应用到0.2(或从0.2应用到0.1或从0.0应用到0.1)会导致大约3100次迭代: 相反,如果我使用0.0,它的迭代成本要高出25倍: 为什么?棘手的地方在哪里?我想不出来。非规范化?
-
高效的“滚动/移动哈希”计算(如移动平均)
我正在尝试优化一个程序,该程序需要在数据流的每个位置(字节)为数据流中的恒定大小窗口计算哈希。在比可用RAM大得多的磁盘文件中查找重复时需要它。目前我为每个窗口计算单独的md5哈希,但它花费了很多时间(窗口大小为几千字节,因此每个数据字节被处理几千次)。我想知道是否有一种方法可以在恒定(与窗口大小无关)时间内计算每个后续哈希(例如移动平均中1个元素的加减)?哈希函数可以是任何东西,只要它不提供长哈
-
Java中由数组计算平均值/最大值/最小值
代码:
-
如何确保消息平均发送到所有消费者
我们公司在Go中建立了push服务,为了保证传输速度,我们在四台机器上安装了push服务,当我们需要发送通知时,我们将消息发送给rabbitMQ,然后push服务从队列中获取消息,但有时我们发现只有一台机器获取消息。 我应该如何设置配置以确保每个消费者获得相同数量的消息?
-
java中具有固定平均值的随机整数数组
我需要创建一个随机整数数组,它们的和是1000000,这些数字的平均值是3。数组中的数字可以重复,数组的长度可以是任意数字。 我能找到随机整数的数组,它们的和是1000000。 然而,我不知道如何找到平均数为3的随机数。
-
如何在python 3中打印均值、中位数和模式
我是python编程的新手,我的代码出现了运行时错误。感谢任何帮助。 第一行由一个表示测试用例数量的整数T组成。每个测试用例的第一行由一个表示数组大小的整数N组成。下面的一行由N个空格分隔的整数Ai组成,表示数组中的元素。 2 2 1
-
如何格式化字符串输出,使列均匀居中?
在我的java课上,我们写了一个卡片程序,在这个程序中,你可以选择一张“秘密卡片”,最后它会告诉你你的秘密卡片是什么。我只有一个问题,那就是格式化输出。到现在为止,当它打印第一列时,第一列是偶数,但第二列和第三列不是。我的老师说要使用空格,但我试过了,不起作用。我知道有一种方法可以格式化它,但我不确定。输出看起来像这样: 我的输出代码如下: 如果你愿意,我可以发布整个代码,但我尽量不发布太多。我非
-
当日的平均值和sd,以R为单位,使用xts
再次,我确实在xts中有我的df,但没有名字!(据我所知,设置为时不再有名字。单点( )): 我想计算一天的平均值和标准差,而不是整个df。 工程,但我得到的不是一天的平均值-如何处理标准差?谢谢
-
给定均值、方差和桶数,求直方图桶边界
我需要找到直方图的桶边界,当用户输入均值,方差和桶数的标准正态分布,除了产生分布值。 我正在使用java nextGaussian()生成正态分布值,但我不确定如何获得桶边界,以便直方图形状看起来像正态分布。
-
 一个数组的平均间隔,python中的标准差(Pandas)
一个数组的平均间隔,python中的标准差(Pandas)我想计算两个相关数组的许多连续间隔的均值和标准偏差(如下所示),其中前两列分别是(比方说)时间和距离。第三、四、五是平均时间(中心)、平均距离和偏差标准。(实际上这是我亲手做的)。在这个例子中,平均值和标准差是为每三个连续的间隔做出的(但通常可以超过4×4,10×10,以此类推)。 所以,我有类似的长列表,我想计算(可能用PANDAS,NUMPY和/或SCIPY)类似的东西,做一些循环,创建平均时