《负载均衡》专题
-
在elasticsearch中找到文档类型的平均存储大小
问题内容: 我如何知道特定文档类型(例如,类型1和类型2)的大小(以字节为单位)? 如果我尝试: 我只得到索引的总大小(以字节为单位)。 我实际上对某种类型的文档的平均大小感兴趣,但是可以从计数和我猜得出的总大小中得出 问题答案: 使用相同的索引对不同类型的索引进行索引,并共享许多通用结构。因此,在不考虑另一种类型的影响的情况下,真的不可能分辨出一种类型正在消耗多少。
-
Shell根据web日志计算平均连接时间功能
本文向大家介绍Shell根据web日志计算平均连接时间功能,包括了Shell根据web日志计算平均连接时间功能的使用技巧和注意事项,需要的朋友参考一下 今天在网上看到一个求web连接平均时间的shell命令,在自己的机器上试了下,发现不能使用,居然出现awk: fatal: division by zero attempted这样的错误,毛了就自己改了下shell命令. 原shell脚本例子: 修
-
如何计算多个数组的数组平均值[重复]
在JavaScript中,我生成了一个x个数组,所有数组由57个数字组成。我想计算数组中每个数字的平均值,作为一个数组的平均值,即: array1[0]array2[0]array3[0]…./阵列数=[0]的平均值 array1[1]阵列2[1]阵列3[1]…./阵列数=[1]的平均值 数组一数组二数组三数组二..../数组数量=平均值[2] 这是生成的数组数组的示例: 谁能给我一个例子,让我可
-
显示WooCommerce中客户的评论总数和平均评分
问题内容: 我想在首页上显示客户评论的总数,我尝试了这种方法: 但是没有按我想要的那样工作!例如,我有4条评论,此代码仅显示(1条评论),而不是(4条评论)。 关于平均水平,我对主页上的工作方式一无所知,我只知道如何使用下面的代码在单个产品页面上实现此功能: 但是,此代码仅适用于单个产品的平均评分,而不是我想要的所有评论的全球平均值。 任何帮助表示赞赏。 问题答案: 更新 (在没有评论的情况下避免
-
如何在 MongoDB 中基于重复的 ID 计算平均值
本文向大家介绍如何在 MongoDB 中基于重复的 ID 计算平均值,包括了如何在 MongoDB 中基于重复的 ID 计算平均值的使用技巧和注意事项,需要的朋友参考一下 对于MongoDB中的平均值,请使用$avg。让我们创建包含文档的集合。在这里,我们有重复的ID,每个ID都有等级- 在find()方法的帮助下显示集合中的所有文档- 这将产生以下输出- 以下是基于重复ID获取平均评分的查询-
-
如何在MySQL中生成一系列每小时平均值?
问题内容: 我的表每隔十分钟就有一次数据: 是否可以为MySQL制定一个SQL查询,每小时返回一系列平均值? 在这种情况下,它应该返回: 问题答案: 尚不清楚是否要在几天内汇总平均值。 如果您希望26号午夜与27号午夜的平均值不同,则可以修改Mabwi的查询: 请注意该子句中的其他内容。没有这个,查询将把从到的所有数据平均在一起,而不考虑它发生的日期。
-
K均值聚类算法的Java版实现代码示例
本文向大家介绍K均值聚类算法的Java版实现代码示例,包括了K均值聚类算法的Java版实现代码示例的使用技巧和注意事项,需要的朋友参考一下 1.简介 K均值聚类算法是先随机选取K个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。一旦全部对象都被分配了,每个聚类的聚类中心会根据聚类中现有的对象被重
-
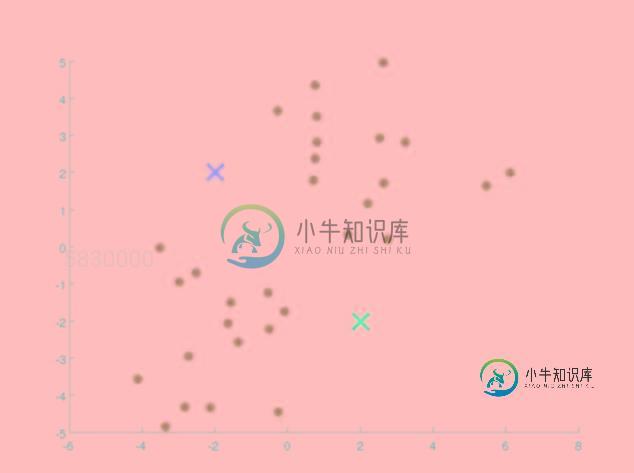 Kmeans均值聚类算法原理以及Python如何实现
Kmeans均值聚类算法原理以及Python如何实现本文向大家介绍Kmeans均值聚类算法原理以及Python如何实现,包括了Kmeans均值聚类算法原理以及Python如何实现的使用技巧和注意事项,需要的朋友参考一下 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给定两个质心,我们这个算法的目的就是将这一堆点根据它们自身的坐标特征分为两类,因此选取了两个质心,什么时候这一堆点能够根据这两
-
创建一个MySQL函数并在列中找到平均值
本文向大家介绍创建一个MySQL函数并在列中找到平均值,包括了创建一个MySQL函数并在列中找到平均值的使用技巧和注意事项,需要的朋友参考一下 让我们首先创建一个表- 使用插入命令在表中插入一些记录- 使用select语句显示表中的所有记录- 这将产生以下输出- 以下是创建返回平均值的函数的查询- 现在您可以使用select语句调用该函数- 这将产生以下输出-
-
级联型。均无级联型。删除更改保持行为
在这个项目中,我有两个实体A和B,它们都与实体C有OneToOne关系。A和B引用了一些C。 到目前为止,使用CascadeType一切都很好。实体B中字段c上的所有内容。我们现在要删除实体B而不删除实体C。因此,我们将实体B中的级联更改为 现在,删除行为符合预期,但当持久化实体B时,实体C没有持久化级联,相反,我们得到了一个组织。springframework。道。InvalidDataAcce
-
如何在SQL Server中的日期列中查找平均值
问题内容: 我有一个带有日期列的5000条记录的表。 如何找到这些日期的平均值。我试过了,但是说 问题答案: 如果只想平均日期: 如果您想考虑时间: 参见小提琴进行测试。
-
如果所有孩子均符合条件,则选择父母
问题内容: 我有这样设置的表: 如果Child中包含给定parent_id的 所有 行均符合涉及x和y的条件(在我的情况下,x = y),我想找到Parents或不同的parent_id 。 例如: 将会得到3。当前,我有一个查询,查找 任何子级 都符合条件的parent_ids 。然后,我用它来检索那些记录,并在所有子级都符合条件的情况下在代码中检查它们。通过示例数据,我得到parent_id
-
T-SQL平均值四舍五入到最接近的整数
问题内容: 我不确定是否曾经问过这个问题,但是如何在T-SQL中将平均值四舍五入到最接近的整数? 问题答案: 这为它工作: 难道没有更短的方法吗?
-
获取Pandas中每个分区的每列平均值[重复]
我试图为数据帧(如以下数据帧)获取每个分区每列的平均值: 也就是说,我想得到和的平均值,并将它们聚合成和的唯一组合。因此,生成的DataFrame应该是: 其中,我国城市分区的重复行已聚合为一行,具有平均值。 我研究了等等问题
-
使用matplotlib在直方图上以虚线绘制平均值
我有一个从pandas数据框创建的直方图,我想绘制一条代表数据集平均值的垂直虚线。我已经回顾了这个线程,这正是我正在寻找的样式,但是,我不知道如何使它与我的代码一起工作(如下所示): 我最终收到了以下错误: 不知道这意味着什么,任何帮助都将不胜感激。 编辑:我的数据文件是一个有一列的csv,第一行是一个标题(字符串),所有后续的107行都是从app开始的值。1.0E 11至4.0E 11 假数据(