《负载均衡》专题
-
Python实现滑动平均(Moving Average)的例子
本文向大家介绍Python实现滑动平均(Moving Average)的例子,包括了Python实现滑动平均(Moving Average)的例子的使用技巧和注意事项,需要的朋友参考一下 Python中滑动平均算法(Moving Average)方案: 以上这篇Python实现滑动平均(Moving Average)的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊
-
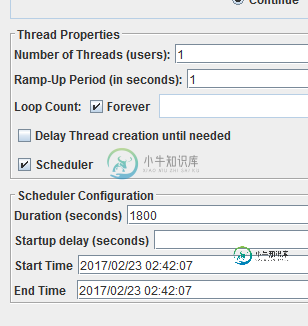 无法增加jmeter中的平均吞吐量
无法增加jmeter中的平均吞吐量我已经将线程数和上升时间设置为1/1,我正在从data.csv迭代我的1000条记录1800秒。现在给出数字,我已经设置了CTT,恒定时间吞吐量为每分钟2000,我预计平均吞吐量2000/60 = 33.3 /sec,但我得到18.7/秒,当我将吞吐量提高到4000/60时,我仍然得到18或19/秒。
-
R语言平均值,中位数和众数
主要内容:1.平均值,2.中位数,3.众数R中的统计分析通过使用许多内置函数来执行的。这些函数大部分是R基础包的一部分。这些函数将R向量与参数一起作为输入,并在执行计算后给出结果。 我们在本章中讨论的是如何求平均值,中位数和众数。下面将分别一个个演示和讲解 - 1.平均值 平均值是通过取数值的总和并除以数据序列中的值的数量来计算。函数用于在R中计算平均值。 语法 R中计算平均值的基本语法是 - 以下是使用的参数的描述 - x - 是输入向
-
返回每一行中每组的平均值
我正在使用SQL Server,数据库中有下表: 到目前为止我尝试了什么(错误的,因为它不计算每个组的平均值,而是计算所有列的总平均值):
-
用查找表在Pyspark中求平均向量
我试图在PySpark中使用https://nlp.stanford.edu/projects/GloVe/预先训练的手套模型实现一个简单的Doc2Vec算法。 我有两个RDD:
-
pandas DataFrame:用列的平均值替换nan值
我有一个pandas DataFrame,其中大部分都是实数,但也有一些值。
-
Apache Spark k-均值聚类-RDD用于输入
该向量包含X、Y坐标,即成对的双打。我想为每个用户ID标识坐标集群,所以我在RDD上进行映射,并尝试为每个组运行k-means: 但是当我运行这个时,我从一行中得到了一个NPE: 问题是,我必须将coords转换为RDD来进行K-Means操作。
-
 C++后端实习(均OC) 滴滴/蔚来/Momenta
C++后端实习(均OC) 滴滴/蔚来/Momenta大部分时间都在问项目,面试体验:滴滴>蔚来>Momenta 滴滴面试官态度很nice,偏门八股很少问,根据项目来考察,不会的还会引导,最后还给了一些学习建议,好感度++ 一面侧重c++语言基础(智能指针、并发、虚函数)和项目,二面侧重系统设计和计算机基础 算法题考的比较简单。。这点我是没想到的 滴滴 基础架构部 一面(50min) golang线程同步方式 菱形继承解决方案 c++11线程同步方式
-
求两个加权平均相等的子阵
我试图通过DP找到所有子数组的加权平均值,然后按列排序,找到长度相同的2。但我无法继续下去,我的方法似乎太模糊/太粗暴了。我将非常感谢任何帮助。提前谢了。
-
具有选定初始中心的k均值
问题内容: 我正在尝试使用选定的初始质心进行k均值聚类。它说在这里 指定您的初始中心: 如果通过,它应该是形状(的,)并给出初始中心。 我在Python中的代码: 返回错误: 并返回相同的初始中心。任何想法如何形成初始中心以便可以被接受吗? 问题答案: 的默认行为是使用不同的随机质心多次初始化算法(即Forgy方法)。然后,随机初始化的数量由参数(docs)控制: n_init :int,默认值:
-
Python-如果两列均为NaN,则删除行
问题内容: 这是对该问题的扩展,OP希望知道如何删除单列值为NaN的行。 我想知道如何删除 2 (或更多)列中的值 均为 NaN的行。使用第二个答案的创建的数据框: 如果我使用命令,特别是使用,那么它将完成一个“或”类型的放置并离开: 我想要的是一个“和”类型放置,它将放置行中的列索引为1 和 2的行删除。这将留下: 仅删除第一行的位置。 有任何想法吗? 编辑:更改数据框值以保持一致性 问题答案:
-
Pandas Dataframe查找所有列均相等的行
问题内容: 我有一个包含字符的数据框-我想要按行的布尔结果,告诉我该行的所有列是否具有相同的值。 例如,我有 我希望结果是 我已经尝试过.all,但似乎只能检查是否都等于一个字母。我能想到的唯一另一种方法是在每一行上做一个唯一的,看看是否等于1?提前致谢。 问题答案: 我认为最干净的方法是使用eq根据第一列检查所有列: 现在,您可以使用全部(如果它们都等于第一项,则它们都相等):
-
在python中计算指数移动平均值
问题内容: 我有一个日期范围,并且每个日期都有一个度量值。我想计算每个日期的指数移动平均值。有人知道怎么做这个吗? 我是python的新手。似乎没有将平均值内置到标准python库中,这让我感到有些奇怪。也许我找的地方不对。 因此,给定以下代码,如何计算日历日期的IQ点的移动加权平均值? (可能是一种更好的数据结构方式,任何建议将不胜感激) 问题答案: 编辑:看来SciKits(补充SciPy的附
-
 Python实现计算图像RGB均值方式
Python实现计算图像RGB均值方式本文向大家介绍Python实现计算图像RGB均值方式,包括了Python实现计算图像RGB均值方式的使用技巧和注意事项,需要的朋友参考一下 要求 存在一个文件夹内有若干张图像,需要计算每张图片的RGB均值,并计算全部图像的RGB均值。 代码 这里需要注意cv2.imread()读取顺序为BGR问题。 注意 路径不能出现中文,不然容易出错。 错误如下: TypeError: 'NoneType' o
-
python如何按求和和平均列分组?
问题内容: 作为输入,我有一个带时间的CSV文件,每次都有一串数字。 我想输出按小时平均和总和分组的每小时表格: 到目前为止,我一直在看用字典来完成它,其中小时是一个关键,值是一个计数和总和的列表,然后将总和除以计数就可以得到平均值。我敢肯定,必须有一种更清洁的方法来做到这一点。也许有些图书馆可以使用它。有什么建议? 问题答案: 一个熊猫的解决方案: 印刷品: 另存为csv文件: 这是以下内容: