《负载均衡》专题
-
是否可以“均匀”地合并Spark分区?
我可以使用这个问题中的技巧来强制初始分区和最终分区之间的关系,但是Spark不知道每个原始分区的所有内容都将转移到一个特定的新分区。因此,它不能优化掉洗牌,而且它的运行速度比慢得多。
-
PySpark:使用timeseries数据进行滚动平均
这将产生两个记录: 窗口函数对时间序列数据进行分类,而不是执行滚动平均。 是否有一种方法来执行滚动平均值,在此方法中,我将为每行返回一个周平均值,时间周期结束于该行的timestampGMT? 在上面的结果中,2017-03-10的rolling_average是17,因为没有之前的记录。2017-03-15的滚动平均值是15,因为它是2017-03-15的13和2017-03-10的17的平均值
-
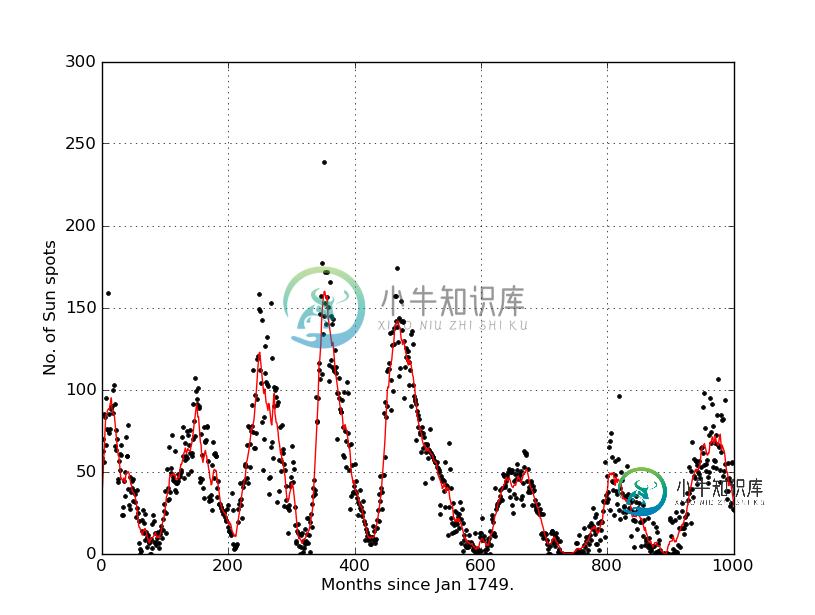 用Python从数据点求移动平均线
用Python从数据点求移动平均线我又用Python玩了一点,我找到了一本有例子的整洁的书。其中一个例子是绘制一些数据。我有一个有两列的。txt文件,我有数据。我把数据绘制得很好,但在练习中,它说:进一步修改程序,计算并绘制数据的运行平均值,定义如下: 其中在本例中(并且是数据文件中的第二列)。使程序将原始数据和运行平均值绘制在同一张图上。 到目前为止我有这个: 非常感谢^^:)
-
第 10 章 K-Means(K-均值)聚类算法
聚类 聚类,简单来说,就是将一个庞杂数据集中具有相似特征的数据自动归类到一起,称为一个簇,簇内的对象越相似,聚类的效果越好。它是一种无监督的学习(Unsupervised Learning)方法,不需要预先标注好的训练集。聚类与分类最大的区别就是分类的目标事先已知,例如猫狗识别,你在分类之前已经预先知道要将它分为猫、狗两个种类;而在你聚类之前,你对你的目标是未知的,同样以动物为例,对于一个动物集来
-
在Jmeter负载测试的5页应用程序上为100个并发用户发出了多少请求
我正在用100到1K个用户成功地运行jmeter测试,但我怀疑响应时间是否高于预期。 对于相同数量的用户,如果减少页面数量,总的响应时间就会减少 那么我是否应该单独为页面运行测试呢? 我是否应该为实际的数字(5页*20个用户=100个并发用户)减少用户数--以进行性能测试?
-
即使应用程序没有运行,FirebaseMessagingService也保持活动,并显示数据负载通知的服务
我在一个使用FCM通知的应用程序中工作,当应用程序运行时(前台或后台)会收到通知,但当我从最近的应用程序中清除应用程序时,我没有收到任何使用FireBaseMessagingService的通知。因此,我想创建一个服务,将保持活跃的myService,这是扩展FirebaseMessaging服务,即使应用程序没有运行或关闭。
-
当用户在后台收到推送后手动打开应用程序时,获取消息推送负载
我正在使用iOS7,我正在尝试确定在以下情况下是否可以获得JSON有效载荷。 我已启用后台模式“远程通知” 当我启动的应用程序从图标本身后的通知已收到我没有得到推在启动选项从 当应用程序从图标手动启动时,以下方法也不会被调用
-
谷歌云IAM工作负载身份与Azure广告'应用程序注册'/'企业应用程序'联合
我正在尝试设置Azure广告“企业应用程序”,以便从myapps访问谷歌云。微软com的身份和访问权限。 我设置了工作负载身份联合,如https://cloud.google.com/iam/docs/configuring-workload-identity-federation#azure所述,但是身份验证工作不正常,出现以下错误。 我的命令: 2个问题: 我怀疑问题在于属性映射。使用Azur
-
挂载和卸载硬盘
问题内容: 如何用Java编程语言装载和卸载硬盘驱动器(与平台无关,因此不使用运行时执行硬编码的命令)? 问题答案: 答案是“是和不是”。您无法在Java中挂载或卸载设备,因为每个操作系统都有自己的方法来执行此操作。但是…您可以提供将适配器模式用于本机接口的Java API。您应该做一些事情: 创建支持安装/卸载命令的Java接口 创建将接口实现为本机方法的类 用C或其他语言创建此命令的本机实现。
-
如何在音频均衡器中添加立体声,高音选项?
问题内容: 我正在尝试使用小型音频歌曲均衡器。我想在其中添加 高音,立体声等选项,就像在Poweramp播放器中一样。 Poweramp音乐播放器的图像 我成功实现了5个频段的均衡器,如下所示: 上面的代码只是我的均衡器代码的简短摘要。它不会像 我在此处发布的示例那样起作用。。 我也想在均衡器中添加高音,立体声,单声道效果。 我已经像这样实现了低音增强: 我使用了Inbulilt类来增强低音。 如
-
MongoDB连接计数未在副本集中的节点之间均衡
我现在正在使用MongoDB Spring Data MongoDB构建一个web应用程序。 此应用程序有一个API,它是一个简单的MongoDB查询: 我们从myCollectionName和project中随机挑选了100个文档。这是一个简单的读取请求。 总共收集了大约1亿条记录,afak我正确地使用了操作符: 是管道的第一阶段 我们的mongoDB集群是一个3节点副本集,一个节点处理写请求,
-
如何在熊猫的NaN值之间均衡地重新分配值?
我有以下数据框: 我想在NaN值之间平均重新分配(1-df['B'].groupby(level=0.sum())。列“C”是预期输出的示例。
-
如何计算平均绝对误差(MAE)和平均有符号误差(MSE)使用熊猫/Numpy/python数学库?
我有一个如下的数据集。在该数据集中,有不同颜色的温度计,给定“真实”或参考温度,根据一些测量方法“方法1”和“方法2”,它们测量的差异有多大。 我在计算我需要的两个重要参数时遇到困难,这两个参数是平均绝对误差(MAE)和平均符号误差(MSE)。我想为每个方法使用非NaN值并打印结果。 我能够得到的点,我可以返回一个两列系列的索引和和,但在这种情况下的问题是,我需要除以方法值的数量总和,这取决于有多
-
我需要生成平均响应时间和平均延迟时间。我的JMeter测试计划的csv文件
我需要生成平均响应时间和平均延迟时间。csv文件。 我在一个Web应用程序中有50个API,我需要为多达50个并发用户对其进行测试。 我尝试过聚合图及其插件,但它只生成平均经过的时间。例如,我得到了聚合已用时间:在此处输入图像描述 我的客户要求我用他们的图表为平均响应时间和平均延迟时间生成类似的电子表格报告。 如果JMeter中有什么方法可以完成,有人可以帮我吗? 在此输入图像描述目前,我已经使用
-
即使json数据包含模式和有效负载字段,kafka connect hdfs接收器连接器也会失败
我正在尝试kafka connect hdfs接收器连接器,以便将json数据从kafka移动到hdfs。 即使在kafka中的json数据具有模式和有效负载时,kafka connect任务也会因错误而失败 Kafka的数据: 错误消息: http://localhost:8083/connectors/connect-cluster-15may-308pm/tasks/0/status