《负载均衡》专题
-
在直方图中绘制平均线(matplotlib)
我正在使用python中的matplotlib绘制直方图,并希望绘制一条代表数据集平均值的线,以虚线的形式覆盖在直方图上(或者其他颜色也可以)。关于如何在柱状图上画一条线有什么想法吗? 我正在使用plot()命令,但不确定如何绘制垂直线(即,我应该为y轴指定什么值? 谢谢
-
获取SQL中每X行的平均值
问题内容: 假设我有下表 我想绘制这些值,但是由于我的真实表有成千上万个值,因此我考虑了获取每X行的平均值。我有什么办法可以做到这一点,即每2或4行,如下所示: 另外,是否有任何方法可以根据表中的总行数使此X值动态化?例如,如果我有1000行,则将基于每200行(1000/5)计算平均值,但是如果我有20行,则应基于每4行(20/5)计算平均值。 我知道如何以编程方式执行此操作,但是有什么方法可以
-
查询以找到平均加权价格
问题内容: 我在Oracle中有一个表,每个给定部分有多行。每行都有一个与之关联的数量和价格。给定零件的行集合总计的总数量也是如此。以下是数据示例。我需要得到零件的平均加权价格。例如,如果数量为100的零件的价格为1,数量为50的零件的价格为2,则加权平均价格为1.33333333 有想法吗? 问题答案: 试试这个:
-
近似均匀数据的压缩算法
我在SE上看到过关于压缩算法的问题,但没有一个完全符合我的要求。显然,真正均匀分布的数据无法压缩,但我们能做到多近? 我(可能是错误的)想法:我会想象通过转换数据(以某种方式标准化?),您可以强调几乎一致的数据的非均匀性方面,然后使用转换集进行压缩,可能与逆变换或其参数一起进行。但也许我完全错了,当数据接近均匀性时,它们的表现都一样糟糕? 当我查看(无损)压缩算法列表时,我看不出它们对某些类型的数
-
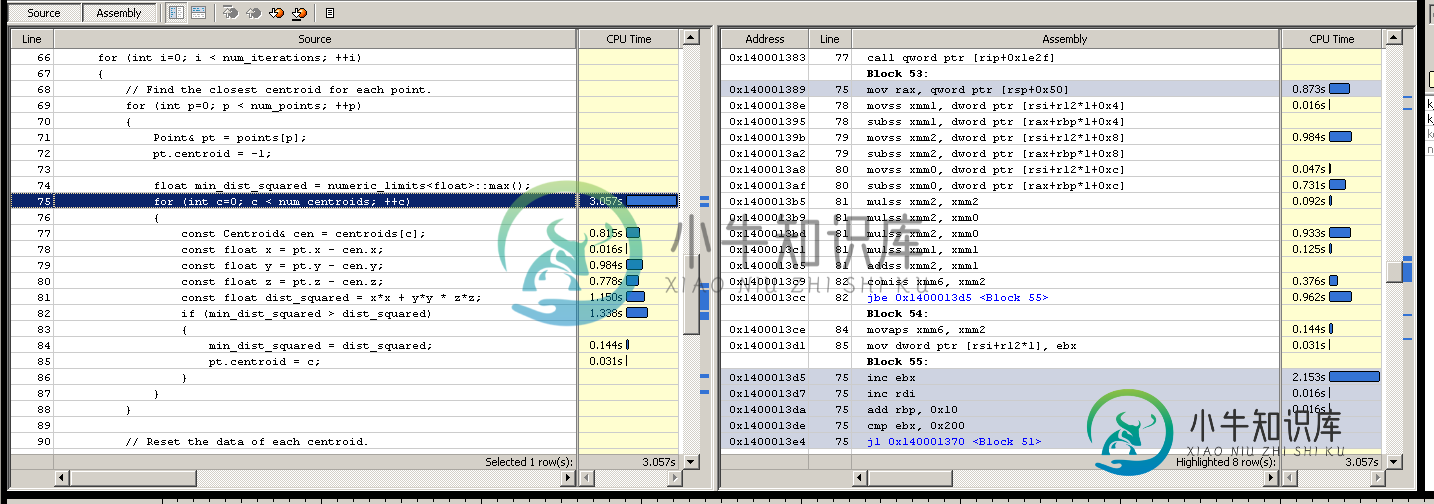 无分支K-均值(或其他优化)
无分支K-均值(或其他优化)注意:我更喜欢如何处理和提出这些类型的解决方案的指南,而不是解决方案本身。 我的系统中有一个非常关键的性能函数,在特定上下文中显示为头号分析热点。它正在进行k-means迭代(已经使用并行处理每个工作线程中的点子范围的多线程)。 处理这段代码所需的任何时间节省都非常重要,所以我经常在这段代码上做很多事情。例如,可能值得将质心循环放在外部,并针对给定质心并行遍历点。这里的簇点数量以百万计,而质心的数
-
将Flink操作符平均分配给TaskManager
我正在一个由15台机器组成的裸机集群上制作Flink流媒体应用程序的原型。我使用的是90个任务槽(15x6)的纱线模式。 该应用程序从单个Kafka主题读取数据。Kafka主题有15个分区,所以我也将源操作符的并行性设置为15。然而,我发现Flink在某些情况下会将2-4个消费者任务实例分配给同一个taskmanager。这会导致某些节点受到网络限制(Kafka主题是提供大量数据,而机器只有1G
-
使用MapReduce计算数字的平均值
我一直在尝试编写一些代码来使用MapReduce查找数字的平均值。 我尝试使用全局计数器来实现我的目标,但是我无法在映射器的< code>map方法中设置计数器值,也无法在缩减器的< code>reduce方法中检索计数器值。 我是否必须在< code>map中使用全局计数器(例如,通过使用所提供的< code>Reporter的< code>incrCounter(key,amount))?或者
-
平均轮数为零的子阵列数
你有一个整数数组。您必须找到子阵列的数量,该数量意味着(这些元素的总和除以这些元素的计数)舍入为零。我已经用O(n^2)时间解决了这个问题,但效率不够。有办法吗?
-
do.call(rbind, list)对于不均匀的列数
我有一个列表,每个元素都是一个字符向量,长度不同。我想将数据绑定为行,这样列名就“对齐”,如果有额外的数据,就创建列,如果缺少数据,就创建NAs 下面是我正在使用的数据的模拟示例 如果我确定每个元素的格式是相同的,下面的行通常是我会做的... 我希望有人能想出一个很好的解决方案,匹配列名,并用s填空,同时添加新列,如果在绑定过程中发现新列。。。
-
我想打印比平均值大多少
我已经打印了总数和平均数。然而,我无法打印出有多少数字大于平均值。 我认为问题在于
-
xarray计算多年netcdf的月平均值
我有一个来自ERA5的2m温度netcdf文件,从2000年到2019年,从04月到10月,总共有13680个时间步长和61x161个纬度。我想分别计算每年所有每日时间步长的月平均值。例如,我们将获得2000年4月、2000年5月等数据的月平均值。我用xarray resample尝试了下面的代码,但是出现了两个问题。 出于某种原因,多年来,中庸之道似乎都是如此 重采样函数创建01、02、03、1
-
读取number.txt文件并查找平均值
目前正在处理一个作业,我需要读取一个数字文件,并显示数字的总量、总偶数、总奇数以及所有三个数字的平均值。我目前正在努力寻找偶数和奇数的平均值。我必须显示偶数的平均值和奇数的平均值。我通过使用parseInt将我读取的数字字符串转换为整数来找到总平均值,这样我就可以计算平均值,但是当我尝试对偶数和奇数做同样的事情时,我无法让它工作。 这是我当前的代码: 输出:
-
Hbase mapreduce作业:所有列值均为空
我正在尝试创建一个地图减少工作在Java的表从一个HBase数据库。使用这里的示例和internet上的其他内容,我成功地编写了一个简单的行计数器。然而,试图编写一个实际对列中的数据执行某些操作的程序是不成功的,因为接收的字节总是空的。 我的司机工作的一部分是这样的: 如您所见,该表称为。我的映射器如下所示: 一些注意事项: 表中的列族只是。有多个列,其中一些列称为和(第一次看到); 即使值正确显
-
R中重复行之间的平均值
我有一个数据帧,其中的行与name列重复,但与value列不重复: 我需要将重复的名称聚合到一行中,同时计算值列的平均值。预期产出如下: 我已经尝试使用< code>df[duplicated(df$name),],但是这当然不能说明重复的含义。我想使用< code>aggregate(),但问题是这个函数有趣的部分也适用于所有其他列,而且在其他问题中,它不能计算char内容。由于所有其他列在“副
-
Ignite实例间数据的均匀分布
我有9个ignite服务器实例,其缓存处于模式,在这种模式下,我用Kafka从分区并行加载数据。这里的分区包含的条目数可以通过字段唯一标识,我还使用将条目从一个分区配置到一个实例。我将key定义为, 因此,我试图在ignite实例中的缓存项和分区之间实现一对一的映射,例如。但在我的例子中,我得到的映射是, 这里实现了关联配置部分,即具有相同分区ID的条目缓存在相同的ignite实例上。但是,数据在