《分库分表》专题
-
PHP合并分隔符
我正在尝试以特定的方式合并两个字符串。 基本上,我需要将前两个字符串合并到第三个字符串中,在它们之间有一个管道符号,然后用逗号分隔: 这两个将变成: 我希望这有意义?
-
SQL Server数据分组
SQL Server中分组查询通常用于配合聚合函数,实现分类汇总统计的信息。而其分类汇总的本质实际上就是先将信息排序,排序后相同类别的信息会聚在一起,然后通过需求进行统计计算。 SQL Server中常用的数据分组相关查询如下: GROUP BY - 根据指定列表达式列表中的值对查询结果进行分组。 HAVING - 指定组或聚合的搜索条件。 GROUPING SETS - 生成多个分组集。 CUB
-
 PDFBox分割PDF文档
PDFBox分割PDF文档主要内容:分割PDF文档中的页面,示例在前一章中,我们已经看到了如何将JavaScript添加到PDF文档。 现在来学习如何将给定的PDF文档分成多个文档。 分割PDF文档中的页面 可以使用类将给定的PDF文档分割为多个PDF文档。 该类用于将给定的PDF文档分成几个其他文档。 以下是拆分现有PDF文档的步骤 第1步:加载现有的PDF文档 使用类的静态方法加载现有的PDF文档。 此方法接受一个文件对象作为参数,因为这是一个静态方法,可
-
 Intellij Idea Profiler分析器
Intellij Idea Profiler分析器主要内容:什么是 VisualVM?,配置,监控应用,螺纹测量,抽样申请,CPU采样,内存采样,内存泄漏Profiler 提供了有关我们应用程序性能的准确信息。它通过我们的应用程序测量 CPU、内存和堆使用的性能。它还为我们提供了有关应用程序线程的详细信息。VisualVM 工具用于测量 Java 应用程序分析。 什么是 VisualVM? 它是一个可视化工具,已与 JDK 以及 Java 6 或更高版本捆绑在一起。它适合初学者,并提供有关我们应用程序性能的详细信息。 配置 在 Windows
-
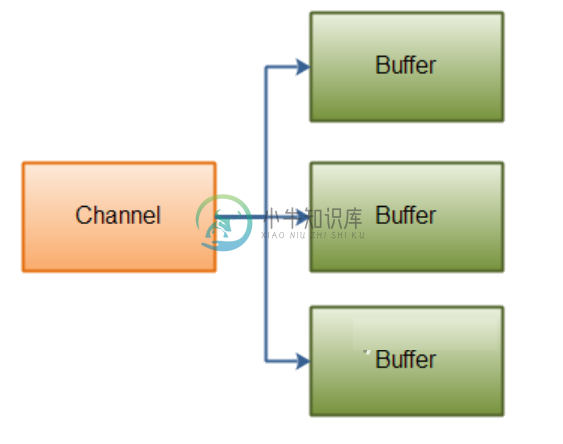 Java NIO 分散/聚集
Java NIO 分散/聚集主要内容:1 分散/聚集的介绍,2 分散读取,3 聚集写入1 分散/聚集的介绍 Java NIO带有内置的分散/聚集功能。分散/聚集是在读取和写入Channel中使用的概念。 从Channel分散读取是将数据读取到多个缓冲区中的读取操作。因此,通道将数据从通道“分散”到多个缓冲区中。 对Channel的聚集写入是一种将来自多个缓冲区的数据写入单个通道的写入操作。因此,通道将来自多个缓冲区的数据“聚集”到一个Channel中。 在需要分别处理传输数据的各个
-
 Java HashMap原理分析
Java HashMap原理分析主要内容:1 什么是哈希(散列)(Hashing),2 HashMap hashCode()方法,3 HashMap equals()方法,4 HashMap 存储桶,5 HashMap的索引计算过程,6 HashMap get()方法,7 HashMap原理分析完整代码本文主要介绍HashMap工作原理,了解哈希算法的计算过程。 1 什么是哈希(散列)(Hashing) 哈希是通过使用方法hashCode() 将对象转换为整数形式的过程。必须正确编写hashCode() 方法,以提高HashM
-
相似度得分-Levenshtein
问题内容: 我用Java实现了Levenshtein算法,现在可以通过算法进行更正,也就是成本。这确实有一点帮助,但并没有太大帮助,因为我希望将结果表示为百分比。 所以我想知道如何计算那些相似点。 我也想知道你们的人民是如何做的以及为什么。 问题答案: 两个字符串之间的Levenshtein距离定义为将一个字符串转换为另一个字符串所需的最小编辑次数,允许的编辑操作为单个字符的插入,删除或替换。(维
-
随机分布均匀
问题内容: 我知道如果我使用Java的Random生成器,并使用nextInt生成数字,则数字将均匀分布。但是,如果我使用2个Random实例,并使用两个Random类生成数字,会发生什么。数字是否会均匀分布? 问题答案: 每个实例生成的数字将均匀分布,因此,如果将两个实例生成的随机数序列组合在一起,则它们也应均匀分布。 请注意,即使结果分布是均匀的,您也可能要注意种子,以避免两个生成器的输出之间
-
分解RSA / ECB / OAEPWITHSHA-256ANDMGF1PADDING
问题内容: Java有一种称为的模式。那有什么意思? RFC3447, 公开密钥密码标准(PKCS)#1:RSA密码规范2.1版 ,第 7.1.2 节 解密操作 说,哈希和MGF都是RSAES-OAEP- DECRYPT的选项。MGF是它自己的功能,在 B.2.1节MGF1中 定义,并且还具有自己的哈希“选项”。 也许RSAES-OAEP- DECRYPT和MGF1中的哈希“选项”应该是相同的,或
-
如何分辨Eclipse Workspace?
问题内容: 有没有办法告诉您当前正在使用的当前Eclipse工作区是什么? 问题答案: 对我来说,选择File-> Switch Workspace-> Other …可以显示当前工作空间的名称。 我试图确认 “ 实际上,这显示的是最后关闭的工作空间,而不是当前的工作空间。如果要打开和关闭多个工作空间,则这是不可靠的。 ” 而且我无法复制它。每次获得当前加载的工作区时(我正在Juno上进行测试)。
-
第5部分:测试
本教程上接教程第4部分。 我们已经建立一个网页投票应用,现在我们将为它创建一些自动化测试。 自动化测试简介 什么是自动化测试? 测试是检查你的代码是否正常运行的简单程序。 测试可以划分为不同的级别。 一些测试可能专注于小细节(某一个模型的方法是否会返回预期的值?), 其他的测试可能会检查软件的整体运行是否正常(用户在对网站进行了一系列的操作后,是否返回了正确的结果?)。这些其实和你早前在教程 1中
-
第1部分:模型
让我们通过例子来学习。 在本教程中,我们将引导您创建一个基本的投票应用。 它将包含两部分: 一个公共网站,可让人们查看投票的结果和让他们进行投票。 一个管理网站,可让你添加、修改和删除投票项目。 我们假设你已经 安装了 Django 。你可以运行以下命令来验证是否已经安装了 Django 和运行着的版本号: python -c "import django; print(django.get_ve
-
7.21.Dijkstra 算法分析
最后,让我们看看 Dijkstra 算法的运行时间。我们首先注意到,构建优先级队列需要 $$O(V)$$ 时间,因为我们最初将图中的每个顶点添加到优先级队列。 一旦构造了队列,则对于每个顶点执行一次 while 循环,因为顶点都在开始处添加,并且在那之后才被移除。 在该循环中每次调用 delMin,需要 $$O(logV)$$时间。 将该部分循环和对 delMin 的调用取为 $$O(Vlog(V
-
7.18.强连通分量
在本章的剩余部分,我们将把注意力转向一些非常大的图。我们将用来研究一些附加算法的图,由互联网上的主机之间的连接和网页之间的链接产生的图。 我们将从网页开始。 像 Google 和 Bing 这样的搜索引擎利用了网页上的页面形成非常大的有向图。 为了将万维网变换为图,我们将把一个页面视为一个顶点,并将页面上的超链接作为将一个顶点连接到另一个顶点的边缘。 Figure 30 展示了从 Luther C
-
6.14.查找树分析
随着二叉搜索树的实现完成,我们将对已经实现的方法进行快速分析。让我们先来看看 put 方法。其性能的限制因素是二叉树的高度。从词汇部分回忆一下树的高度是根和最深叶节点之间的边的数量。高度是限制因素,因为当我们寻找合适的位置将一个节点插入到树中时,我们需要在树的每个级别最多进行一次比较。 二叉树的高度可能是多少?这个问题的答案取决于如何将键添加到树。如果按照随机顺序添加键,树的高度将在 $$log2